 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Assisted AR Assembly: Object Recognition and Computer Vision for Augmented Reality Assisted Assembly
Nov 07, 2025
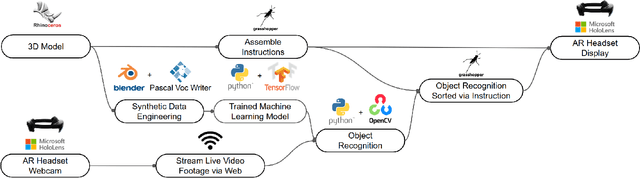
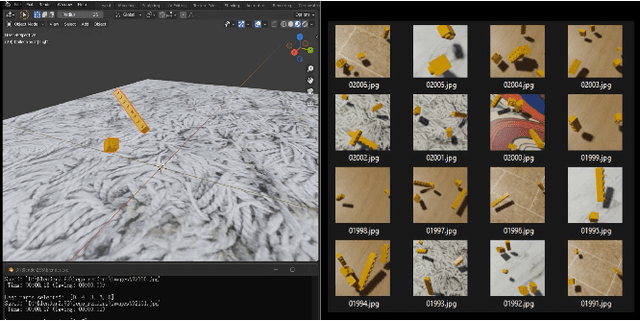

We present an AI-assisted Augmented Reality assembly workflow that uses deep learning-based object recognition to identify different assembly components and display step-by-step instructions. For each assembly step, the system displays a bounding box around the corresponding components in the physical space, and where the component should be placed. By connecting assembly instructions with the real-time location of relevant components, the system eliminates the need for manual searching, sorting, or labeling of different components before each assembly. To demonstrate the feasibility of using object recognition for AR-assisted assembly, we highlight a case study involving the assembly of LEGO sculptures.
A Multi-Stage Large Language Model Framework for Extracting Suicide-Related Social Determinants of Health
Aug 07, 2025Background: Understanding social determinants of health (SDoH) factors contributing to suicide incidents is crucial for early intervention and prevention. However, data-driven approaches to this goal face challenges such as long-tailed factor distributions, analyzing pivotal stressors preceding suicide incidents, and limited model explainability. Methods: We present a multi-stage large language model framework to enhance SDoH factor extraction from unstructured text. Our approach was compared to other state-of-the-art language models (i.e., pre-trained BioBERT and GPT-3.5-turbo) and reasoning models (i.e., DeepSeek-R1). We also evaluated how the model's explanations help people annotate SDoH factors more quickly and accurately. The analysis included both automated comparisons and a pilot user study. Results: We show that our proposed framework demonstrated performance boosts in the overarching task of extracting SDoH factors and in the finer-grained tasks of retrieving relevant context. Additionally, we show that fine-tuning a smaller, task-specific model achieves comparable or better performance with reduced inference costs. The multi-stage design not only enhances extraction but also provides intermediate explanations, improving model explainability. Conclusions: Our approach improves both the accuracy and transparency of extracting suicide-related SDoH from unstructured texts. These advancements have the potential to support early identification of individuals at risk and inform more effective prevention strategies.
Natural Language Processing in Support of Evidence-based Medicine: A Scoping Review
May 28, 2025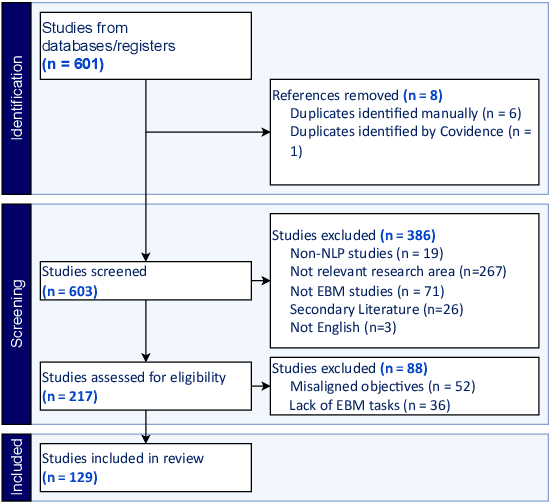
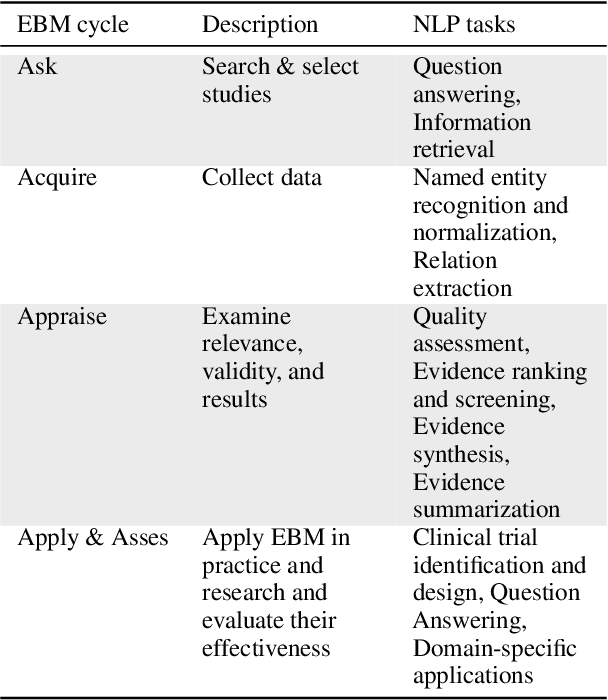
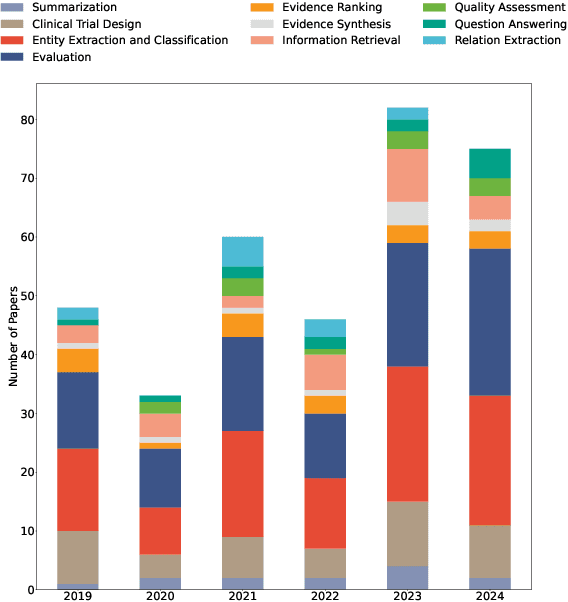
Evidence-based medicine (EBM) is at the forefront of modern healthcare, emphasizing the use of the best available scientific evidence to guide clinical decisions. Due to the sheer volume and rapid growth of medical literature and the high cost of curation, there is a critical need to investigate Natural Language Processing (NLP) methods to identify, appraise, synthesize, summarize, and disseminate evidence in EBM. This survey presents an in-depth review of 129 research studies on leveraging NLP for EBM, illustrating its pivotal role in enhancing clinical decision-making processes. The paper systematically explores how NLP supports the five fundamental steps of EBM -- Ask, Acquire, Appraise, Apply, and Assess. The review not only identifies current limitations within the field but also proposes directions for future research, emphasizing the potential for NLP to revolutionize EBM by refining evidence extraction, evidence synthesis, appraisal, summarization, enhancing data comprehensibility, and facilitating a more efficient clinical workflow.
SDF-TopoNet: A Two-Stage Framework for Tubular Structure Segmentation via SDF Pre-training and Topology-Aware Fine-Tuning
Mar 20, 2025



Accurate segmentation of tubular and curvilinear structures, such as blood vessels, neurons, and road networks, is crucial in various applications. A key challenge is ensuring topological correctness while maintaining computational efficiency. Existing approaches often employ topological loss functions based on persistent homology, such as Betti error, to enforce structural consistency. However, these methods suffer from high computational costs and are insensitive to pixel-level accuracy, often requiring additional loss terms like Dice or MSE to compensate. To address these limitations, we propose \textbf{SDF-TopoNet}, an improved topology-aware segmentation framework that enhances both segmentation accuracy and training efficiency. Our approach introduces a novel two-stage training strategy. In the pre-training phase, we utilize the signed distance function (SDF) as an auxiliary learning target, allowing the model to encode topological information without directly relying on computationally expensive topological loss functions. In the fine-tuning phase, we incorporate a dynamic adapter alongside a refined topological loss to ensure topological correctness while mitigating overfitting and computational overhead. We evaluate our method on five benchmark datasets. Experimental results demonstrate that SDF-TopoNet outperforms existing methods in both topological accuracy and quantitative segmentation metrics, while significantly reducing training complexity.
Computation-Efficient and Recognition-Friendly 3D Point Cloud Privacy Protection
Mar 20, 2025



3D point cloud has been widely used in applications such as self-driving cars, robotics, CAD models, etc. To the best of our knowledge, these applications raised the issue of privacy leakage in 3D point clouds, which has not been studied well. Different from the 2D image privacy, which is related to texture and 2D geometric structure, the 3D point cloud is texture-less and only relevant to 3D geometric structure. In this work, we defined the 3D point cloud privacy problem and proposed an efficient privacy-preserving framework named PointFlowGMM that can support downstream classification and segmentation tasks without seeing the original data. Using a flow-based generative model, the point cloud is projected into a latent Gaussian mixture distributed subspace. We further designed a novel angular similarity loss to obfuscate the original geometric structure and reduce the model size from 767MB to 120MB without a decrease in recognition performance. The projected point cloud in the latent space is orthogonally rotated randomly to further protect the original geometric structure, the class-to-class relationship is preserved after rotation, thus, the protected point cloud can support the recognition task. We evaluated our model on multiple datasets and achieved comparable recognition results on encrypted point clouds compared to the original point clouds.
Suicide Risk Assessment on Social Media with Semi-Supervised Learning
Nov 18, 2024



With social media communities increasingly becoming places where suicidal individuals post and congregate, natural language processing presents an exciting avenue for the development of automated suicide risk assessment systems. However, past efforts suffer from a lack of labeled data and class imbalances within the available labeled data. To accommodate this task's imperfect data landscape, we propose a semi-supervised framework that leverages labeled (n=500) and unlabeled (n=1,500) data and expands upon the self-training algorithm with a novel pseudo-label acquisition process designed to handle imbalanced datasets. To further ensure pseudo-label quality, we manually verify a subset of the pseudo-labeled data that was not predicted unanimously across multiple trials of pseudo-label generation. We test various models to serve as the backbone for this framework, ultimately deciding that RoBERTa performs the best. Ultimately, by leveraging partially validated pseudo-labeled data in addition to ground-truth labeled data, we substantially improve our model's ability to assess suicide risk from social media posts.
AutoWS-Bench-101: Benchmarking Automated Weak Supervision with 100 Labels
Aug 30, 2022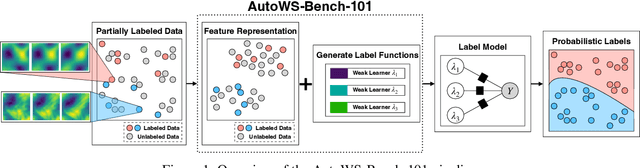
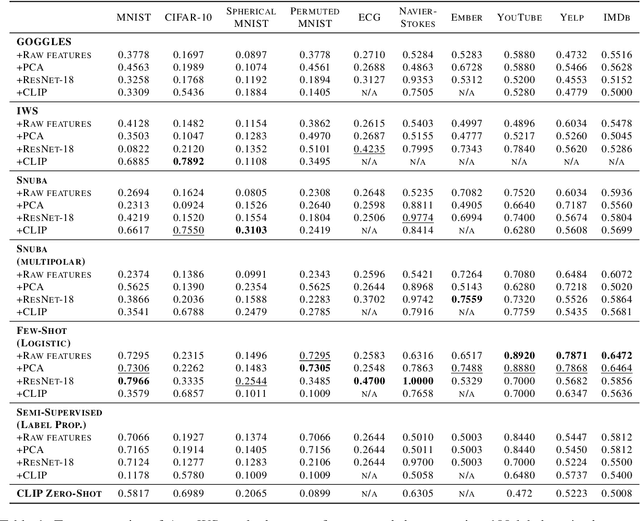
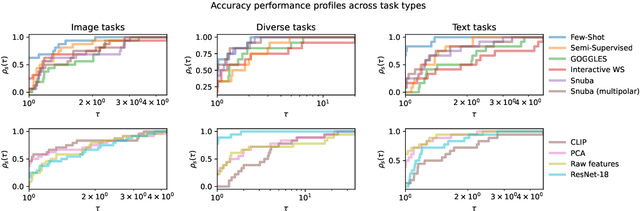
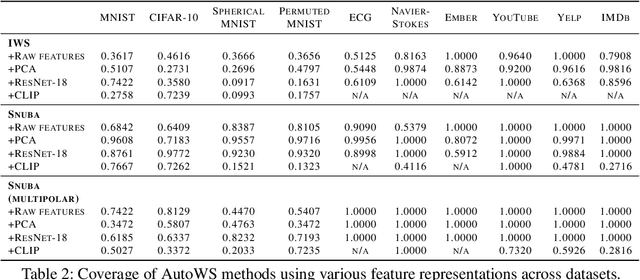
Weak supervision (WS) is a powerful method to build labeled datasets for training supervised models in the face of little-to-no labeled data. It replaces hand-labeling data with aggregating multiple noisy-but-cheap label estimates expressed by labeling functions (LFs). While it has been used successfully in many domains, weak supervision's application scope is limited by the difficulty of constructing labeling functions for domains with complex or high-dimensional features. To address this, a handful of methods have proposed automating the LF design process using a small set of ground truth labels. In this work, we introduce AutoWS-Bench-101: a framework for evaluating automated WS (AutoWS) techniques in challenging WS settings -- a set of diverse application domains on which it has been previously difficult or impossible to apply traditional WS techniques. While AutoWS is a promising direction toward expanding the application-scope of WS, the emergence of powerful methods such as zero-shot foundation models reveals the need to understand how AutoWS techniques compare or cooperate with modern zero-shot or few-shot learners. This informs the central question of AutoWS-Bench-101: given an initial set of 100 labels for each task, we ask whether a practitioner should use an AutoWS method to generate additional labels or use some simpler baseline, such as zero-shot predictions from a foundation model or supervised learning. We observe that in many settings, it is necessary for AutoWS methods to incorporate signal from foundation models if they are to outperform simple few-shot baselines, and AutoWS-Bench-101 promotes future research in this direction. We conclude with a thorough ablation study of AutoWS methods.
Rotation-Equivariant Neural Networks for Privacy Protection
Jun 21, 2020
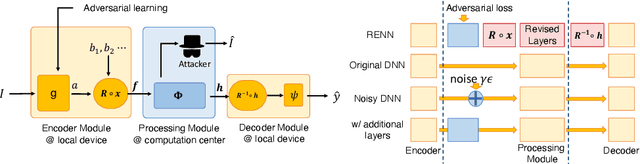
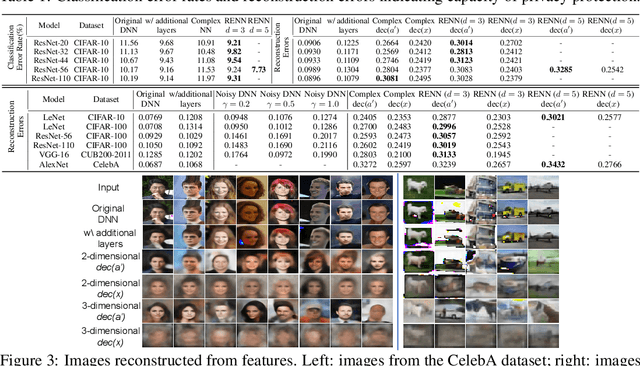
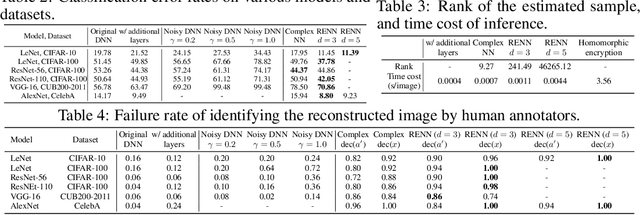
In order to prevent leaking input information from intermediate-layer features, this paper proposes a method to revise the traditional neural network into the rotation-equivariant neural network (RENN). Compared to the traditional neural network, the RENN uses d-ary vectors/tensors as features, in which each element is a d-ary number. These d-ary features can be rotated (analogous to the rotation of a d-dimensional vector) with a random angle as the encryption process. Input information is hidden in this target phase of d-ary features for attribute obfuscation. Even if attackers have obtained network parameters and intermediate-layer features, they cannot extract input information without knowing the target phase. Hence, the input privacy can be effectively protected by the RENN. Besides, the output accuracy of RENNs only degrades mildly compared to traditional neural networks, and the computational cost is significantly less than the homomorphic encryption.
Deep Quaternion Features for Privacy Protection
Mar 18, 2020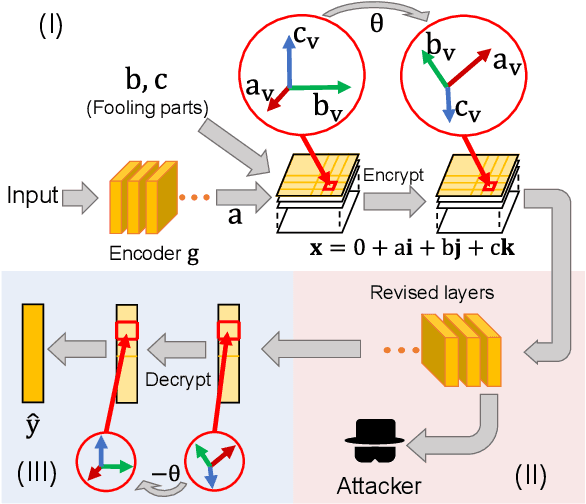

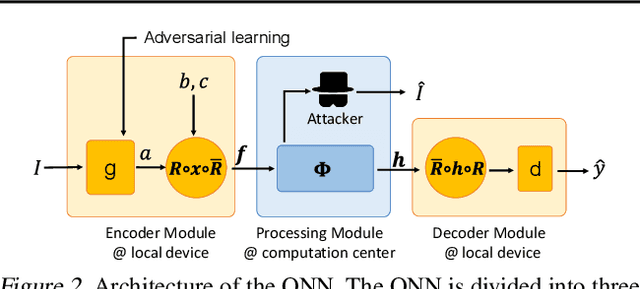
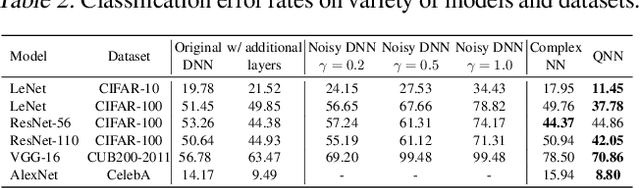
We propose a method to revise the neural network to construct the quaternion-valued neural network (QNN), in order to prevent intermediate-layer features from leaking input information. The QNN uses quaternion-valued features, where each element is a quaternion. The QNN hides input information into a random phase of quaternion-valued features. Even if attackers have obtained network parameters and intermediate-layer features, they cannot extract input information without knowing the target phase. In this way, the QNN can effectively protect the input privacy. Besides, the output accuracy of QNNs only degrades mildly compared to traditional neural networks, and the computational cost is much less than other privacy-preserving methods.
Quantifying Layerwise Information Discarding of Neural Networks
Jun 10, 2019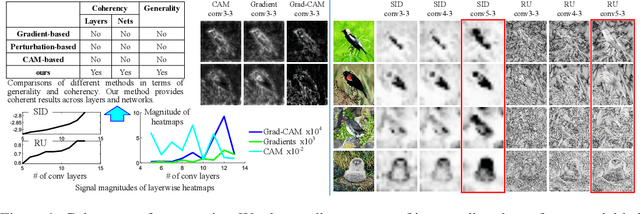
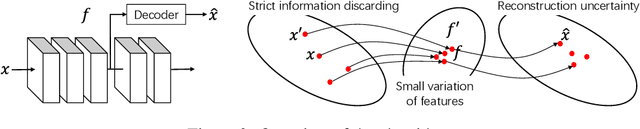

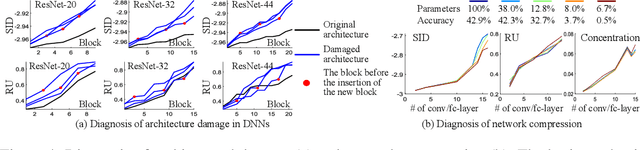
This paper presents a method to explain how input information is discarded through intermediate layers of a neural network during the forward propagation, in order to quantify and diagnose knowledge representations of pre-trained deep neural networks. We define two types of entropy-based metrics, i.e., the strict information discarding and the reconstruction uncertainty, which measure input information of a specific layer from two perspectives. We develop a method to enable efficient computation of such entropy-based metrics. Our method can be broadly applied to various neural networks and enable comprehensive comparisons between different layers of different networks. Preliminary experiments have shown the effectiveness of our metrics in analyzing benchmark networks and explaining existing deep-learning techniques.