 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistency Deep Equilibrium Models
Feb 03, 2026Deep Equilibrium Models (DEQs) have emerged as a powerful paradigm in deep learning, offering the ability to model infinite-depth networks with constant memory usage. However, DEQs incur significant inference latency due to the iterative nature of fixed-point solvers. In this work, we introduce the Consistency Deep Equilibrium Model (C-DEQ), a novel framework that leverages consistency distillation to accelerate DEQ inference. We cast the DEQ iterative inference process as evolution along a fixed ODE trajectory toward the equilibrium. Along this trajectory, we train C-DEQs to consistently map intermediate states directly to the fixed point, enabling few-step inference while preserving the performance of the teacher DEQ. At the same time, it facilitates multi-step evaluation to flexibly trade computation for performance gains. Extensive experiments across various domain tasks demonstrate that C-DEQs achieves consistent 2-20$\times$ accuracy improvements over implicit DEQs under the same few-step inference budget.
Diving into Kronecker Adapters: Component Design Matters
Feb 01, 2026Kronecker adapters have emerged as a promising approach for fine-tuning large-scale models, enabling high-rank updates through tunable component structures. However, existing work largely treats the component structure as a fixed or heuristic design choice, leaving the dimensions and number of Kronecker components underexplored. In this paper, we identify component structure as a key factor governing the capacity of Kronecker adapters. We perform a fine-grained analysis of both the dimensions and number of Kronecker components. In particular, we show that the alignment between Kronecker adapters and full fine-tuning depends on component configurations. Guided by these insights, we propose Component Designed Kronecker Adapters (CDKA). We further provide parameter-budget-aware configuration guidelines and a tailored training stabilization strategy for practical deployment. Experiments across various natural language processing tasks demonstrate the effectiveness of CDKA. Code is available at https://github.com/rainstonee/CDKA.
A Large-dimensional Analysis of ESPRIT DoA Estimation: Inconsistency and a Correction via RMT
Jan 06, 2025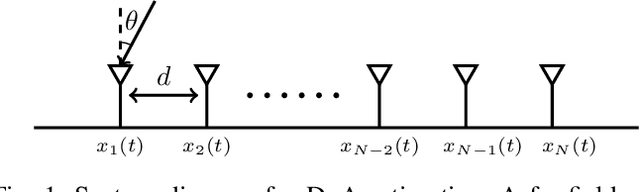
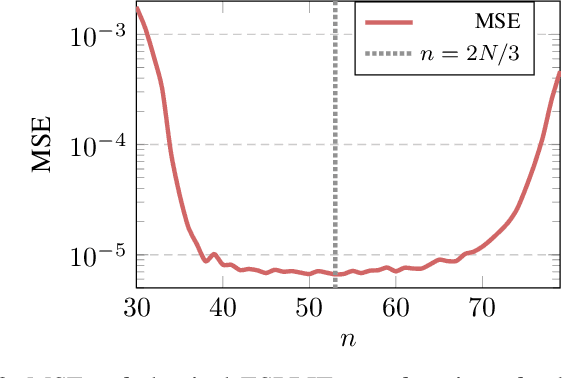
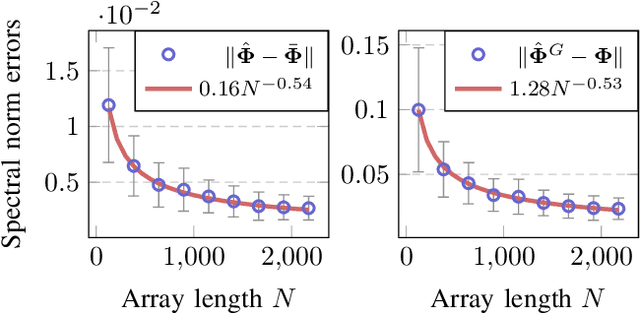
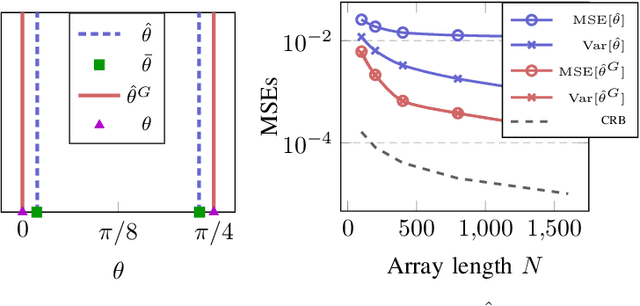
In this paper, we perform asymptotic analyses of the widely used ESPRIT direction-of-arrival (DoA) estimator for large arrays, where the array size $N$ and the number of snapshots $T$ grow to infinity at the same pace. In this large-dimensional regime, the sample covariance matrix (SCM) is known to be a poor eigenspectral estimator of the population covariance. We show that the classical ESPRIT algorithm, that relies on the SCM, and as a consequence of the large-dimensional inconsistency of the SCM, produces inconsistent DoA estimates as $N,T \to \infty$ with $N/T \to c \in (0,\infty)$, for both widely- and closely-spaced DoAs. Leveraging tools from random matrix theory (RMT), we propose an improved G-ESPRIT method and prove its consistency in the same large-dimensional setting. From a technical perspective, we derive a novel bound on the eigenvalue differences between two potentially non-Hermitian random matrices, which may be of independent interest. Numerical simulations are provided to corroborate our theoretical findings.
TRIS-HAR: Transmissive Reconfigurable Intelligent Surfaces-assisted Cognitive Wireless Human Activity Recognition Using State Space Models
Oct 03, 2024



Human activity recognition (HAR) using radio frequency (RF) signals has garnered considerable attention for its applications in smart environments. However, traditional systems often struggle with limited independent channels between transmitters and receivers, multipath fading, and environmental noise, which particularly degrades performance in through-the-wall scenarios. In this paper, we present a transmissive reconfigurable intelligent surface (TRIS)-assisted through-the-wall human activity recognition (TRIS-HAR) system. The system employs TRIS technology to actively reshape wireless signal propagation, creating multiple independent paths to enhance signal clarity and improve recognition accuracy in complex indoor settings. Additionally, we propose the Human intelligence Mamba (HiMamba), an advanced state space model that captures temporal and frequency-based information for precise activity recognition. HiMamba achieves state-of-the-art performance on two public datasets, demonstrating superior accuracy. Extensive experiments indicate that the TRIS-HAR system improves recognition performance from 85.00% to 98.06% in laboratory conditions and maintains high performance across various environments. This approach offers a robust solution for enhancing RF-based HAR, with promising applications in smart home and elderly care systems.
"Lossless" Compression of Deep Neural Networks: A High-dimensional Neural Tangent Kernel Approach
Mar 01, 2024Modern deep neural networks (DNNs) are extremely powerful; however, this comes at the price of increased depth and having more parameters per layer, making their training and inference more computationally challenging. In an attempt to address this key limitation, efforts have been devoted to the compression (e.g., sparsification and/or quantization) of these large-scale machine learning models, so that they can be deployed on low-power IoT devices. In this paper, building upon recent advances in neural tangent kernel (NTK) and random matrix theory (RMT), we provide a novel compression approach to wide and fully-connected \emph{deep} neural nets. Specifically, we demonstrate that in the high-dimensional regime where the number of data points $n$ and their dimension $p$ are both large, and under a Gaussian mixture model for the data, there exists \emph{asymptotic spectral equivalence} between the NTK matrices for a large family of DNN models. This theoretical result enables "lossless" compression of a given DNN to be performed, in the sense that the compressed network yields asymptotically the same NTK as the original (dense and unquantized) network, with its weights and activations taking values \emph{only} in $\{ 0, \pm 1 \}$ up to a scaling. Experiments on both synthetic and real-world data are conducted to support the advantages of the proposed compression scheme, with code available at \url{https://github.com/Model-Compression/Lossless_Compression}.
Deep Equilibrium Models are Almost Equivalent to Not-so-deep Explicit Models for High-dimensional Gaussian Mixtures
Feb 05, 2024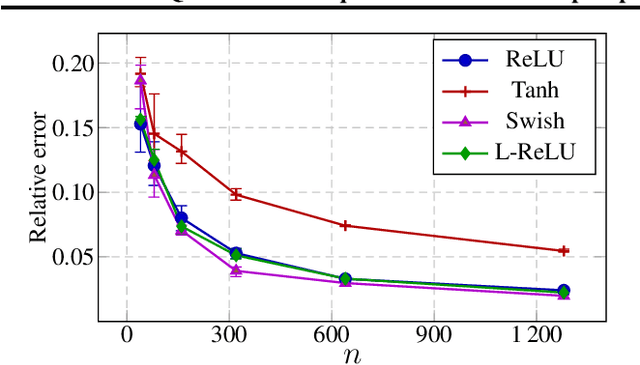
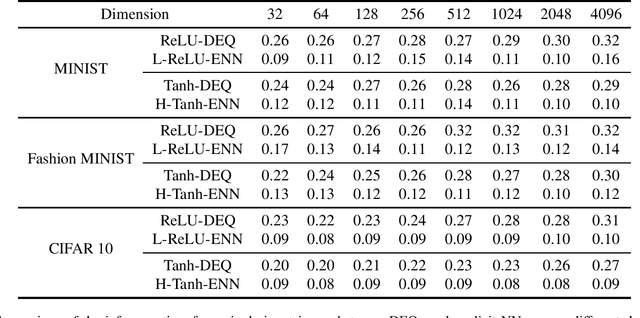
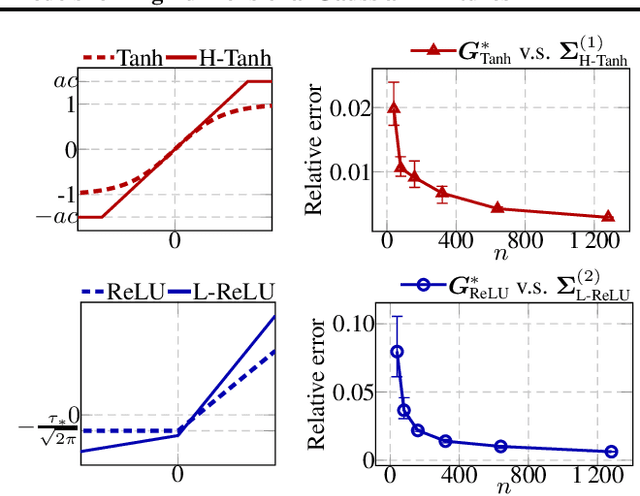
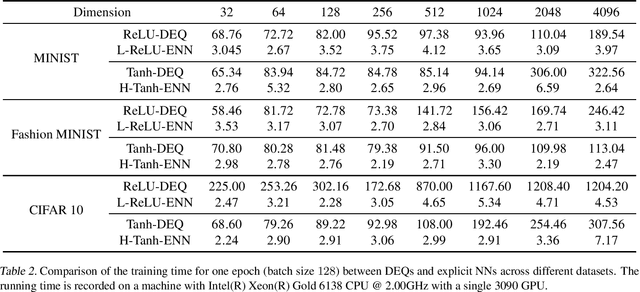
Deep equilibrium models (DEQs), as a typical implicit neural network, have demonstrated remarkable success on various tasks. There is, however, a lack of theoretical understanding of the connections and differences between implicit DEQs and explicit neural network models. In this paper, leveraging recent advances in random matrix theory (RMT), we perform an in-depth analysis on the eigenspectra of the conjugate kernel (CK) and neural tangent kernel (NTK) matrices for implicit DEQs, when the input data are drawn from a high-dimensional Gaussian mixture. We prove, in this setting, that the spectral behavior of these Implicit-CKs and NTKs depend on the DEQ activation function and initial weight variances, but only via a system of four nonlinear equations. As a direct consequence of this theoretical result, we demonstrate that a shallow explicit network can be carefully designed to produce the same CK or NTK as a given DEQ. Despite derived here for Gaussian mixture data, empirical results show the proposed theory and design principle also apply to popular real-world datasets.
DeLR: Active Learning for Detection with Decoupled Localization and Recognition Query
Dec 28, 2023Active learning has been demonstrated effective to reduce labeling cost, while most progress has been designed for image recognition, there still lacks instance-level active learning for object detection. In this paper, we rethink two key components, i.e., localization and recognition, for object detection, and find that the correctness of them are highly related, therefore, it is not necessary to annotate both boxes and classes if we are given pseudo annotations provided with the trained model. Motivated by this, we propose an efficient query strategy, termed as DeLR, that Decoupling the Localization and Recognition for active query. In this way, we are probably free of class annotations when the localization is correct, and able to assign the labeling budget for more informative samples. There are two main differences in DeLR: 1) Unlike previous methods mostly focus on image-level annotations, where the queried samples are selected and exhausted annotated. In DeLR, the query is based on region-level, and we only annotate the object region that is queried; 2) Instead of directly providing both localization and recognition annotations, we separately query the two components, and thus reduce the recognition budget with the pseudo class labels provided by the model. Experiments on several benchmarks demonstrate its superiority. We hope our proposed query strategy would shed light on researches in active learning in object detection.
Timestamp-supervised Wearable-based Activity Segmentation and Recognition with Contrastive Learning and Order-Preserving Optimal Transport
Oct 13, 2023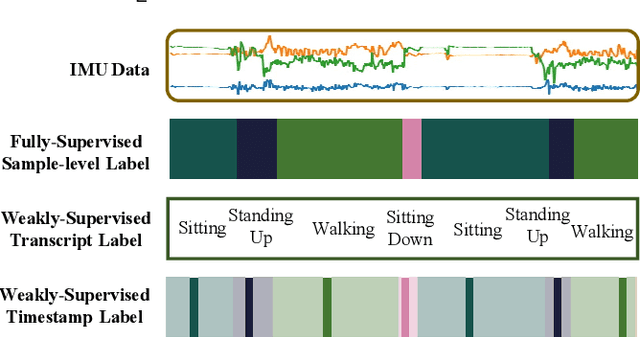

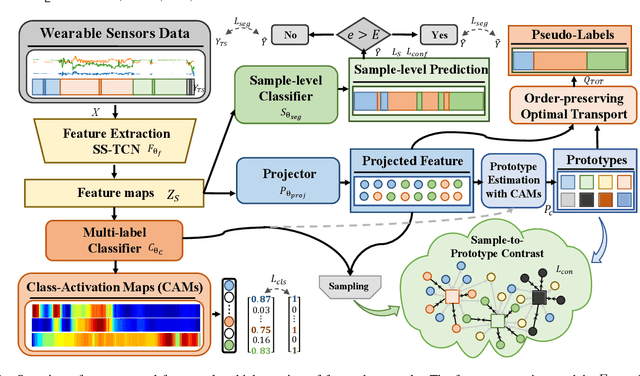
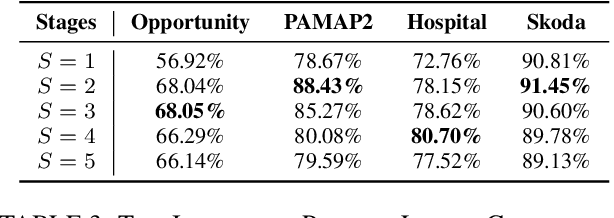
Human activity recognition (HAR) with wearables is one of the serviceable technologies in ubiquitous and mobile computing applications. The sliding-window scheme is widely adopted while suffering from the multi-class windows problem. As a result, there is a growing focus on joint segmentation and recognition with deep-learning methods, aiming at simultaneously dealing with HAR and time-series segmentation issues. However, obtaining the full activity annotations of wearable data sequences is resource-intensive or time-consuming, while unsupervised methods yield poor performance. To address these challenges, we propose a novel method for joint activity segmentation and recognition with timestamp supervision, in which only a single annotated sample is needed in each activity segment. However, the limited information of sparse annotations exacerbates the gap between recognition and segmentation tasks, leading to sub-optimal model performance. Therefore, the prototypes are estimated by class-activation maps to form a sample-to-prototype contrast module for well-structured embeddings. Moreover, with the optimal transport theory, our approach generates the sample-level pseudo-labels that take advantage of unlabeled data between timestamp annotations for further performance improvement. Comprehensive experiments on four public HAR datasets demonstrate that our model trained with timestamp supervision is superior to the state-of-the-art weakly-supervised methods and achieves comparable performance to the fully-supervised approaches.
On the Equivalence between Implicit and Explicit Neural Networks: A High-dimensional Viewpoint
Aug 31, 2023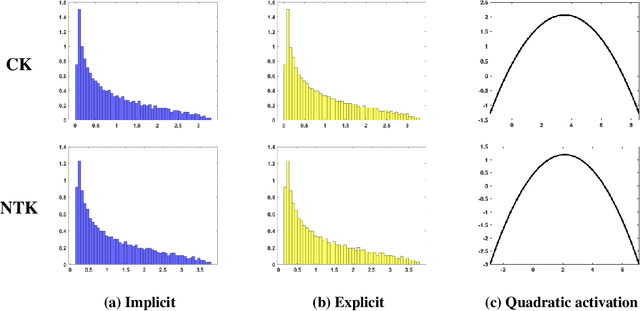
Implicit neural networks have demonstrated remarkable success in various tasks. However, there is a lack of theoretical analysis of the connections and differences between implicit and explicit networks. In this paper, we study high-dimensional implicit neural networks and provide the high dimensional equivalents for the corresponding conjugate kernels and neural tangent kernels. Built upon this, we establish the equivalence between implicit and explicit networks in high dimensions.
Zero-shot Inversion Process for Image Attribute Editing with Diffusion Models
Aug 30, 2023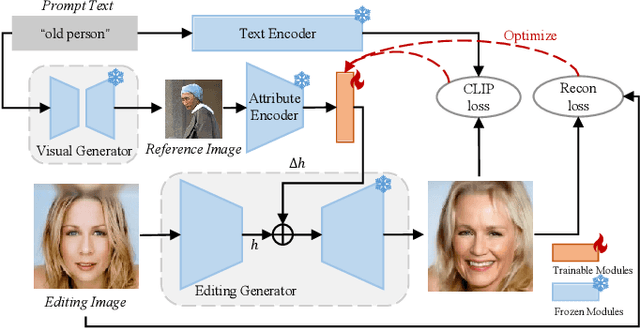



Denoising diffusion models have shown outstanding performance in image editing. Existing works tend to use either image-guided methods, which provide a visual reference but lack control over semantic coherence, or text-guided methods, which ensure faithfulness to text guidance but lack visual quality. To address the problem, we propose the Zero-shot Inversion Process (ZIP), a framework that injects a fusion of generated visual reference and text guidance into the semantic latent space of a \textit{frozen} pre-trained diffusion model. Only using a tiny neural network, the proposed ZIP produces diverse content and attributes under the intuitive control of the text prompt. Moreover, ZIP shows remarkable robustness for both in-domain and out-of-domain attribute manipulation on real images. We perform detailed experiments on various benchmark datasets. Compared to state-of-the-art methods, ZIP produces images of equivalent quality while providing a realistic editing effect.