 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-shot Inversion Process for Image Attribute Editing with Diffusion Models
Aug 30, 2023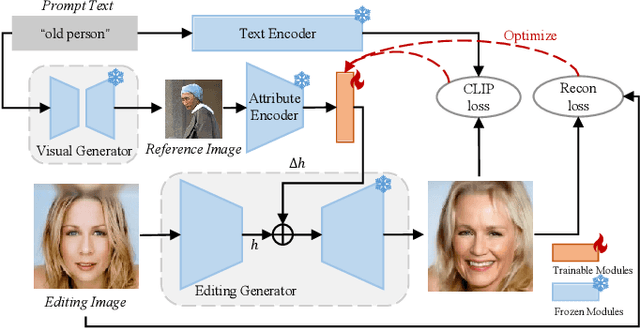



Denoising diffusion models have shown outstanding performance in image editing. Existing works tend to use either image-guided methods, which provide a visual reference but lack control over semantic coherence, or text-guided methods, which ensure faithfulness to text guidance but lack visual quality. To address the problem, we propose the Zero-shot Inversion Process (ZIP), a framework that injects a fusion of generated visual reference and text guidance into the semantic latent space of a \textit{frozen} pre-trained diffusion model. Only using a tiny neural network, the proposed ZIP produces diverse content and attributes under the intuitive control of the text prompt. Moreover, ZIP shows remarkable robustness for both in-domain and out-of-domain attribute manipulation on real images. We perform detailed experiments on various benchmark datasets. Compared to state-of-the-art methods, ZIP produces images of equivalent quality while providing a realistic editing effect.