 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeries-to-Series Diffusion Bridge Model
Nov 07, 2024



Diffusion models have risen to prominence in time series forecasting, showcasing their robust capability to model complex data distributions. However, their effectiveness in deterministic predictions is often constrained by instability arising from their inherent stochasticity. In this paper, we revisit time series diffusion models and present a comprehensive framework that encompasses most existing diffusion-based methods. Building on this theoretical foundation, we propose a novel diffusion-based time series forecasting model, the Series-to-Series Diffusion Bridge Model ($\mathrm{S^2DBM}$), which leverages the Brownian Bridge process to reduce randomness in reverse estimations and improves accuracy by incorporating informative priors and conditions derived from historical time series data. Experimental results demonstrate that $\mathrm{S^2DBM}$ delivers superior performance in point-to-point forecasting and competes effectively with other diffusion-based models in probabilistic forecasting.
IGNN-Solver: A Graph Neural Solver for Implicit Graph Neural Networks
Oct 11, 2024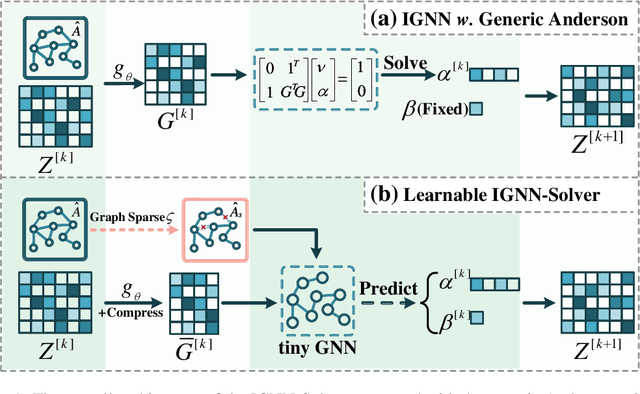
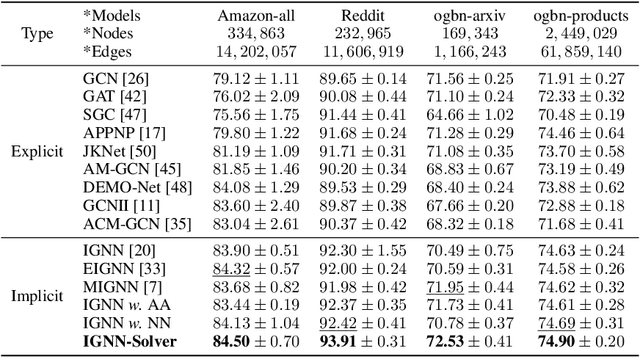
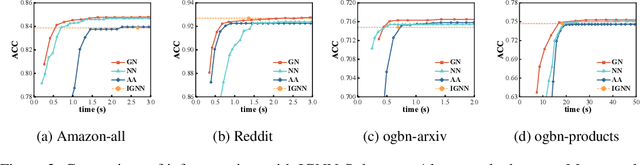
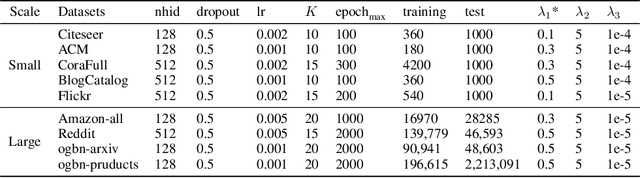
Implicit graph neural networks (IGNNs), which exhibit strong expressive power with a single layer, have recently demonstrated remarkable performance in capturing long-range dependencies (LRD) in underlying graphs while effectively mitigating the over-smoothing problem. However, IGNNs rely on computationally expensive fixed-point iterations, which lead to significant speed and scalability limitations, hindering their application to large-scale graphs. To achieve fast fixed-point solving for IGNNs, we propose a novel graph neural solver, IGNN-Solver, which leverages the generalized Anderson Acceleration method, parameterized by a small GNN, and learns iterative updates as a graph-dependent temporal process. Extensive experiments demonstrate that the IGNN-Solver significantly accelerates inference, achieving a $1.5\times$ to $8\times$ speedup without sacrificing accuracy. Moreover, this advantage becomes increasingly pronounced as the graph scale grows, facilitating its large-scale deployment in real-world applications.
Dreamer: Dual-RIS-aided Imager in Complementary Modes
Jul 20, 2024Reconfigurable intelligent surfaces (RISs) have emerged as a promising auxiliary technology for radio frequency imaging. However, existing works face challenges of faint and intricate back-scattered waves and the restricted field-of-view (FoV), both resulting from complex target structures and a limited number of antennas. The synergistic benefits of multi-RIS-aided imaging hold promise for addressing these challenges. Here, we propose a dual-RIS-aided imaging system, Dreamer, which operates collaboratively in complementary modes (reflection-mode and transmission-mode). Dreamer significantly expands the FoV and enhances perception by deploying dual-RIS across various spatial and measurement patterns. Specifically, we perform a fine-grained analysis of how radio-frequency (RF) signals encode scene information in the scattered object modeling. Based on this modeling, we design illumination strategies to balance spatial resolution and observation scale, and implement a prototype system in a typical indoor environment. Moreover, we design a novel artificial neural network with a CNN-external-attention mechanism to translate RF signals into high-resolution images of human contours. Our approach achieves an impressive SSIM score exceeding 0.83, validating its effectiveness in broadening perception modes and enhancing imaging capabilities. The code to reproduce our results is available at https://github.com/fuhaiwang/Dreamer.
Deep Equilibrium Models are Almost Equivalent to Not-so-deep Explicit Models for High-dimensional Gaussian Mixtures
Feb 05, 2024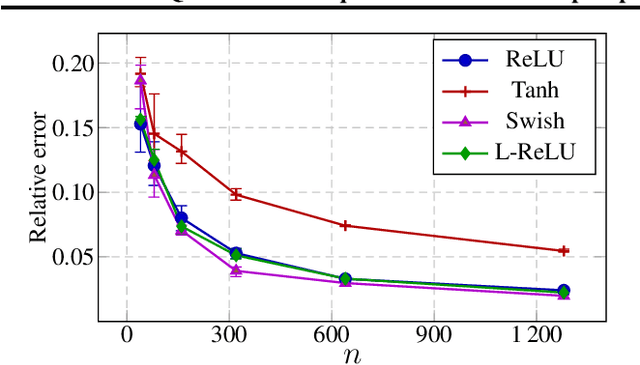
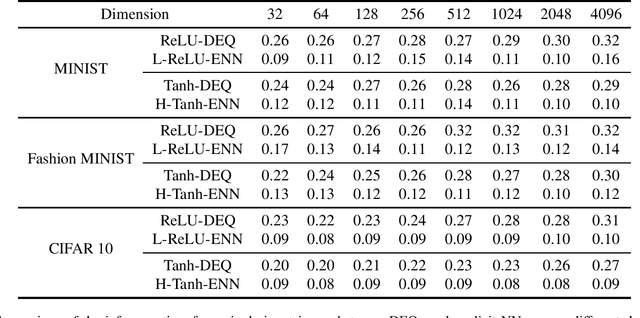
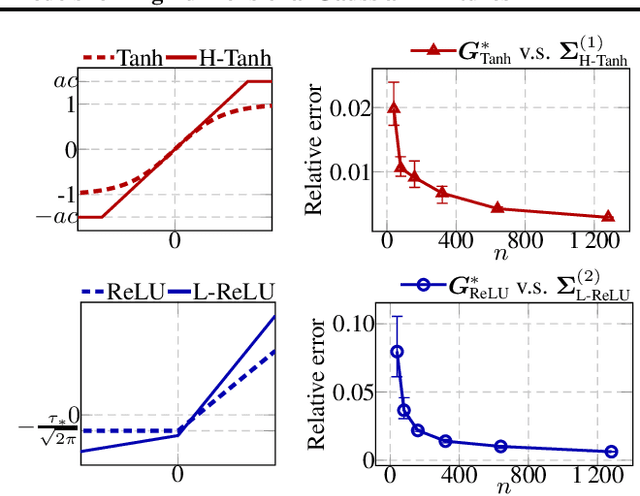
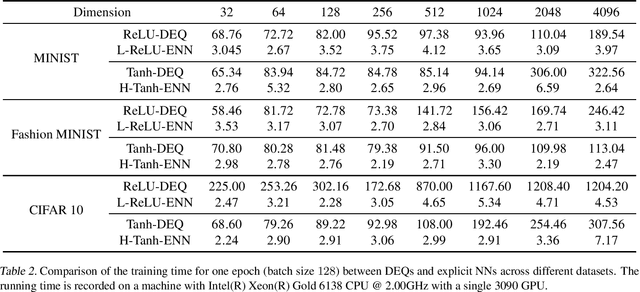
Deep equilibrium models (DEQs), as a typical implicit neural network, have demonstrated remarkable success on various tasks. There is, however, a lack of theoretical understanding of the connections and differences between implicit DEQs and explicit neural network models. In this paper, leveraging recent advances in random matrix theory (RMT), we perform an in-depth analysis on the eigenspectra of the conjugate kernel (CK) and neural tangent kernel (NTK) matrices for implicit DEQs, when the input data are drawn from a high-dimensional Gaussian mixture. We prove, in this setting, that the spectral behavior of these Implicit-CKs and NTKs depend on the DEQ activation function and initial weight variances, but only via a system of four nonlinear equations. As a direct consequence of this theoretical result, we demonstrate that a shallow explicit network can be carefully designed to produce the same CK or NTK as a given DEQ. Despite derived here for Gaussian mixture data, empirical results show the proposed theory and design principle also apply to popular real-world datasets.
Robust and Communication-Efficient Federated Domain Adaptation via Random Features
Nov 08, 2023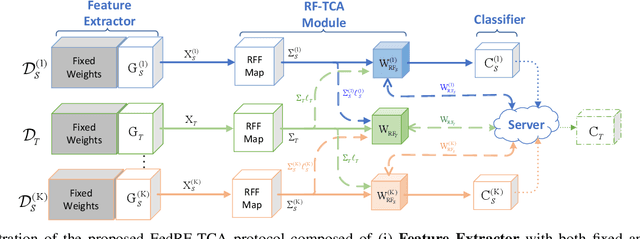

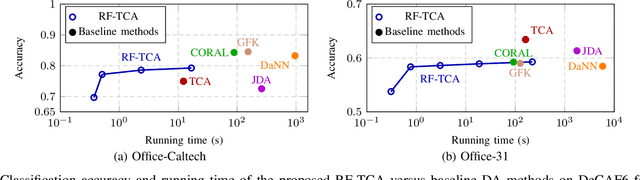
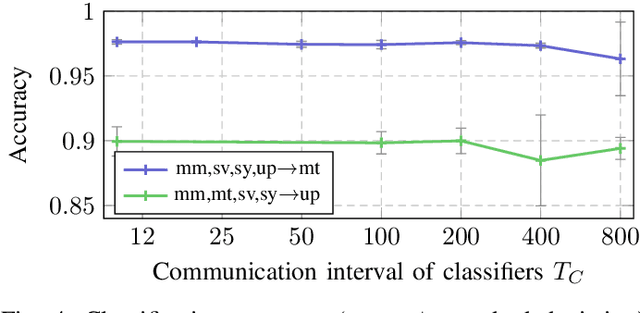
Modern machine learning (ML) models have grown to a scale where training them on a single machine becomes impractical. As a result, there is a growing trend to leverage federated learning (FL) techniques to train large ML models in a distributed and collaborative manner. These models, however, when deployed on new devices, might struggle to generalize well due to domain shifts. In this context, federated domain adaptation (FDA) emerges as a powerful approach to address this challenge. Most existing FDA approaches typically focus on aligning the distributions between source and target domains by minimizing their (e.g., MMD) distance. Such strategies, however, inevitably introduce high communication overheads and can be highly sensitive to network reliability. In this paper, we introduce RF-TCA, an enhancement to the standard Transfer Component Analysis approach that significantly accelerates computation without compromising theoretical and empirical performance. Leveraging the computational advantage of RF-TCA, we further extend it to FDA setting with FedRF-TCA. The proposed FedRF-TCA protocol boasts communication complexity that is \emph{independent} of the sample size, while maintaining performance that is either comparable to or even surpasses state-of-the-art FDA methods. We present extensive experiments to showcase the superior performance and robustness (to network condition) of FedRF-TCA.
Zero-shot Inversion Process for Image Attribute Editing with Diffusion Models
Aug 30, 2023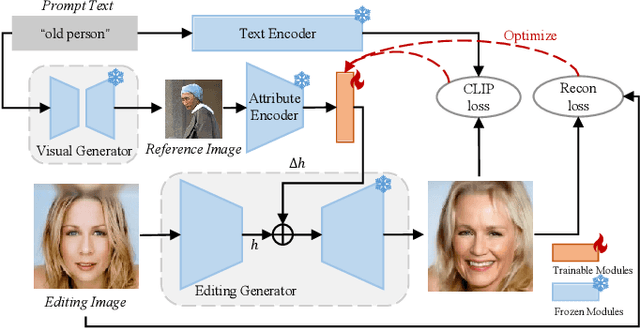



Denoising diffusion models have shown outstanding performance in image editing. Existing works tend to use either image-guided methods, which provide a visual reference but lack control over semantic coherence, or text-guided methods, which ensure faithfulness to text guidance but lack visual quality. To address the problem, we propose the Zero-shot Inversion Process (ZIP), a framework that injects a fusion of generated visual reference and text guidance into the semantic latent space of a \textit{frozen} pre-trained diffusion model. Only using a tiny neural network, the proposed ZIP produces diverse content and attributes under the intuitive control of the text prompt. Moreover, ZIP shows remarkable robustness for both in-domain and out-of-domain attribute manipulation on real images. We perform detailed experiments on various benchmark datasets. Compared to state-of-the-art methods, ZIP produces images of equivalent quality while providing a realistic editing effect.
Adaptive incentive for cross-silo federated learning: A multi-agent reinforcement learning approach
Feb 15, 2023


Cross-silo federated learning (FL) is a typical FL that enables organizations(e.g., financial or medical entities) to train global models on isolated data. Reasonable incentive is key to encouraging organizations to contribute data. However, existing works on incentivizing cross-silo FL lack consideration of the environmental dynamics (e.g., precision of the trained global model and data owned by uncertain clients during the training processes). Moreover, most of them assume that organizations share private information, which is unrealistic. To overcome these limitations, we propose a novel adaptive mechanism for cross-silo FL, towards incentivizing organizations to contribute data to maximize their long-term payoffs in a real dynamic training environment. The mechanism is based on multi-agent reinforcement learning, which learns near-optimal data contribution strategy from the history of potential games without organizations' private information. Experiments demonstrate that our mechanism achieves adaptive incentive and effectively improves the long-term payoffs for organizations.
Color Recognition for Rubik's Cube Robot
Jan 11, 2019
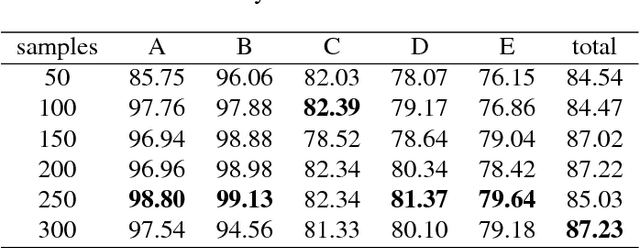
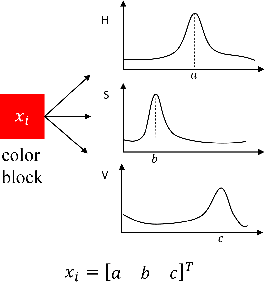
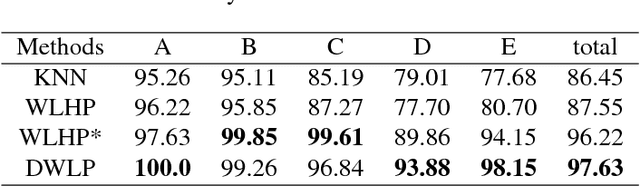
In this paper, we proposed three methods to solve color recognition of Rubik's cube, which includes one offline method and two online methods. Scatter balance \& extreme learning machine (SB-ELM), a offline method, is proposed to illustrate the efficiency of training based method. We also point out the conception of color drifting which indicates offline methods are always ineffectiveness and can not work well in continuous change circumstance. By contrast, dynamic weight label propagation is proposed for labeling blocks color by known center blocks color of Rubik's cube. Furthermore, weak label hierarchic propagation, another online method, is also proposed for unknown all color information but only utilizes weak label of center block in color recognition. We finally design a Rubik's cube robot and construct a dataset to illustrate the efficiency and effectiveness of our online methods and to indicate the ineffectiveness of offline method by color drifting in our dataset.