 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust and Communication-Efficient Federated Domain Adaptation via Random Features
Paper and Code
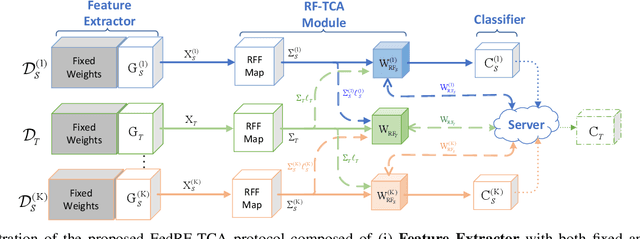

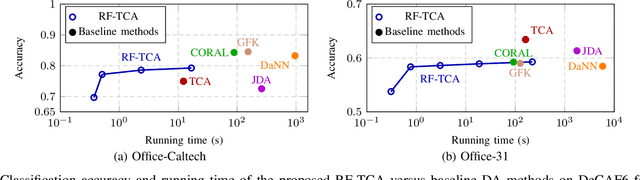
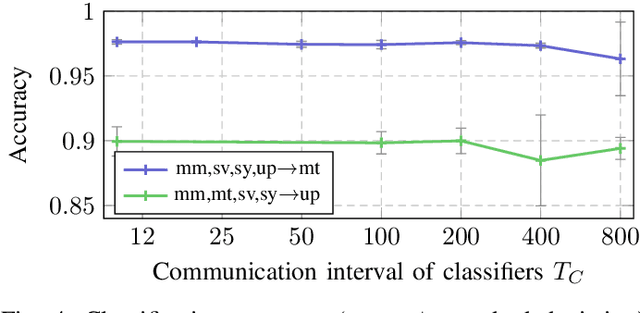
Modern machine learning (ML) models have grown to a scale where training them on a single machine becomes impractical. As a result, there is a growing trend to leverage federated learning (FL) techniques to train large ML models in a distributed and collaborative manner. These models, however, when deployed on new devices, might struggle to generalize well due to domain shifts. In this context, federated domain adaptation (FDA) emerges as a powerful approach to address this challenge. Most existing FDA approaches typically focus on aligning the distributions between source and target domains by minimizing their (e.g., MMD) distance. Such strategies, however, inevitably introduce high communication overheads and can be highly sensitive to network reliability. In this paper, we introduce RF-TCA, an enhancement to the standard Transfer Component Analysis approach that significantly accelerates computation without compromising theoretical and empirical performance. Leveraging the computational advantage of RF-TCA, we further extend it to FDA setting with FedRF-TCA. The proposed FedRF-TCA protocol boasts communication complexity that is \emph{independent} of the sample size, while maintaining performance that is either comparable to or even surpasses state-of-the-art FDA methods. We present extensive experiments to showcase the superior performance and robustness (to network condition) of FedRF-TCA.