 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE-mem: Multi-agent based Episodic Context Reconstruction for LLM Agent Memory
Jan 29, 2026The evolution of Large Language Model (LLM) agents towards System~2 reasoning, characterized by deliberative, high-precision problem-solving, requires maintaining rigorous logical integrity over extended horizons. However, prevalent memory preprocessing paradigms suffer from destructive de-contextualization. By compressing complex sequential dependencies into pre-defined structures (e.g., embeddings or graphs), these methods sever the contextual integrity essential for deep reasoning. To address this, we propose E-mem, a framework shifting from Memory Preprocessing to Episodic Context Reconstruction. Inspired by biological engrams, E-mem employs a heterogeneous hierarchical architecture where multiple assistant agents maintain uncompressed memory contexts, while a central master agent orchestrates global planning. Unlike passive retrieval, our mechanism empowers assistants to locally reason within activated segments, extracting context-aware evidence before aggregation. Evaluations on the LoCoMo benchmark demonstrate that E-mem achieves over 54\% F1, surpassing the state-of-the-art GAM by 7.75\%, while reducing token cost by over 70\%.
AgentTutor: Empowering Personalized Learning with Multi-Turn Interactive Teaching in Intelligent Education Systems
Dec 24, 2025The rapid advancement of large-scale language models (LLMs) has shown their potential to transform intelligent education systems (IESs) through automated teaching and learning support applications. However, current IESs often rely on single-turn static question-answering, which fails to assess learners' cognitive levels, cannot adjust teaching strategies based on real-time feedback, and is limited to providing simple one-off responses. To address these issues, we introduce AgentTutor, a multi-turn interactive intelligent education system to empower personalized learning. It features an LLM-powered generative multi-agent system and a learner-specific personalized learning profile environment that dynamically optimizes and delivers teaching strategies based on learners' learning status, personalized goals, learning preferences, and multimodal study materials. It includes five key modules: curriculum decomposition, learner assessment, dynamic strategy, teaching reflection, and knowledge & experience memory. We conducted extensive experiments on multiple benchmark datasets, AgentTutor significantly enhances learners' performance while demonstrating strong effectiveness in multi-turn interactions and competitiveness in teaching quality among other baselines.
BAPFL: Exploring Backdoor Attacks Against Prototype-based Federated Learning
Sep 16, 2025Prototype-based federated learning (PFL) has emerged as a promising paradigm to address data heterogeneity problems in federated learning, as it leverages mean feature vectors as prototypes to enhance model generalization. However, its robustness against backdoor attacks remains largely unexplored. In this paper, we identify that PFL is inherently resistant to existing backdoor attacks due to its unique prototype learning mechanism and local data heterogeneity. To further explore the security of PFL, we propose BAPFL, the first backdoor attack method specifically designed for PFL frameworks. BAPFL integrates a prototype poisoning strategy with a trigger optimization mechanism. The prototype poisoning strategy manipulates the trajectories of global prototypes to mislead the prototype training of benign clients, pushing their local prototypes of clean samples away from the prototypes of trigger-embedded samples. Meanwhile, the trigger optimization mechanism learns a unique and stealthy trigger for each potential target label, and guides the prototypes of trigger-embedded samples to align closely with the global prototype of the target label. Experimental results across multiple datasets and PFL variants demonstrate that BAPFL achieves a 35\%-75\% improvement in attack success rate compared to traditional backdoor attacks, while preserving main task accuracy. These results highlight the effectiveness, stealthiness, and adaptability of BAPFL in PFL.
VELO: A Vector Database-Assisted Cloud-Edge Collaborative LLM QoS Optimization Framework
Jun 19, 2024



The Large Language Model (LLM) has gained significant popularity and is extensively utilized across various domains. Most LLM deployments occur within cloud data centers, where they encounter substantial response delays and incur high costs, thereby impacting the Quality of Services (QoS) at the network edge. Leveraging vector database caching to store LLM request results at the edge can substantially mitigate response delays and cost associated with similar requests, which has been overlooked by previous research. Addressing these gaps, this paper introduces a novel Vector database-assisted cloud-Edge collaborative LLM QoS Optimization (VELO) framework. Firstly, we propose the VELO framework, which ingeniously employs vector database to cache the results of some LLM requests at the edge to reduce the response time of subsequent similar requests. Diverging from direct optimization of the LLM, our VELO framework does not necessitate altering the internal structure of LLM and is broadly applicable to diverse LLMs. Subsequently, building upon the VELO framework, we formulate the QoS optimization problem as a Markov Decision Process (MDP) and devise an algorithm grounded in Multi-Agent Reinforcement Learning (MARL) to decide whether to request the LLM in the cloud or directly return the results from the vector database at the edge. Moreover, to enhance request feature extraction and expedite training, we refine the policy network of MARL and integrate expert demonstrations. Finally, we implement the proposed algorithm within a real edge system. Experimental findings confirm that our VELO framework substantially enhances user satisfaction by concurrently diminishing delay and resource consumption for edge users utilizing LLMs.
Robust and Communication-Efficient Federated Domain Adaptation via Random Features
Nov 08, 2023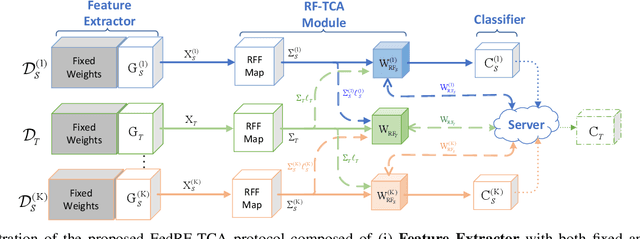

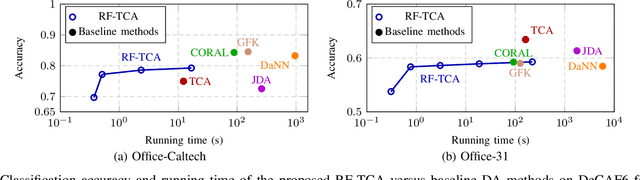
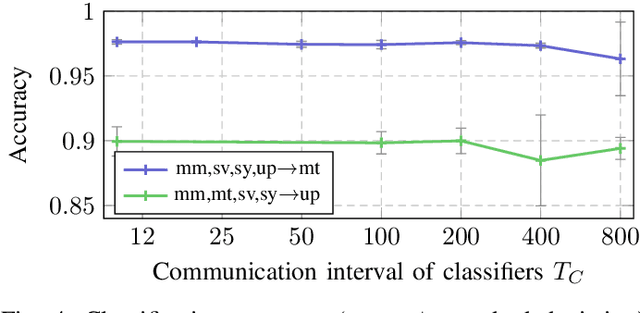
Modern machine learning (ML) models have grown to a scale where training them on a single machine becomes impractical. As a result, there is a growing trend to leverage federated learning (FL) techniques to train large ML models in a distributed and collaborative manner. These models, however, when deployed on new devices, might struggle to generalize well due to domain shifts. In this context, federated domain adaptation (FDA) emerges as a powerful approach to address this challenge. Most existing FDA approaches typically focus on aligning the distributions between source and target domains by minimizing their (e.g., MMD) distance. Such strategies, however, inevitably introduce high communication overheads and can be highly sensitive to network reliability. In this paper, we introduce RF-TCA, an enhancement to the standard Transfer Component Analysis approach that significantly accelerates computation without compromising theoretical and empirical performance. Leveraging the computational advantage of RF-TCA, we further extend it to FDA setting with FedRF-TCA. The proposed FedRF-TCA protocol boasts communication complexity that is \emph{independent} of the sample size, while maintaining performance that is either comparable to or even surpasses state-of-the-art FDA methods. We present extensive experiments to showcase the superior performance and robustness (to network condition) of FedRF-TCA.