 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA multimodal vision foundation model for generalizable knee pathology
Jan 26, 2026Musculoskeletal disorders represent a leading cause of global disability, creating an urgent demand for precise interpretation of medical imaging. Current artificial intelligence (AI) approaches in orthopedics predominantly rely on task-specific, supervised learning paradigms. These methods are inherently fragmented, require extensive annotated datasets, and often lack generalizability across different modalities and clinical scenarios. The development of foundation models in this field has been constrained by the scarcity of large-scale, curated, and open-source musculoskeletal datasets. To address these challenges, we introduce OrthoFoundation, a multimodal vision foundation model optimized for musculoskeletal pathology. We constructed a pre-training dataset of 1.2 million unlabeled knee X-ray and MRI images from internal and public databases. Utilizing a Dinov3 backbone, the model was trained via self-supervised contrastive learning to capture robust radiological representations. OrthoFoundation achieves state-of-the-art (SOTA) performance across 14 downstream tasks. It attained superior accuracy in X-ray osteoarthritis diagnosis and ranked first in MRI structural injury detection. The model demonstrated remarkable label efficiency, matching supervised baselines using only 50% of labeled data. Furthermore, despite being pre-trained on knee images, OrthoFoundation exhibited exceptional cross-anatomy generalization to the hip, shoulder, and ankle. OrthoFoundation represents a significant advancement toward general-purpose AI for musculoskeletal imaging. By learning fundamental, joint-agnostic radiological semantics from large-scale multimodal data, it overcomes the limitations of conventional models, which provides a robust framework for reducing annotation burdens and enhancing diagnostic accuracy in clinical practice.
The Illusion of Clinical Reasoning: A Benchmark Reveals the Pervasive Gap in Vision-Language Models for Clinical Competency
Dec 25, 2025Background: The rapid integration of foundation models into clinical practice and public health necessitates a rigorous evaluation of their true clinical reasoning capabilities beyond narrow examination success. Current benchmarks, typically based on medical licensing exams or curated vignettes, fail to capture the integrated, multimodal reasoning essential for real-world patient care. Methods: We developed the Bones and Joints (B&J) Benchmark, a comprehensive evaluation framework comprising 1,245 questions derived from real-world patient cases in orthopedics and sports medicine. This benchmark assesses models across 7 tasks that mirror the clinical reasoning pathway, including knowledge recall, text and image interpretation, diagnosis generation, treatment planning, and rationale provision. We evaluated eleven vision-language models (VLMs) and six large language models (LLMs), comparing their performance against expert-derived ground truth. Results: Our results demonstrate a pronounced performance gap between task types. While state-of-the-art models achieved high accuracy, exceeding 90%, on structured multiple-choice questions, their performance markedly declined on open-ended tasks requiring multimodal integration, with accuracy scarcely reaching 60%. VLMs demonstrated substantial limitations in interpreting medical images and frequently exhibited severe text-driven hallucinations, often ignoring contradictory visual evidence. Notably, models specifically fine-tuned for medical applications showed no consistent advantage over general-purpose counterparts. Conclusions: Current artificial intelligence models are not yet clinically competent for complex, multimodal reasoning. Their safe deployment should currently be limited to supportive, text-based roles. Future advancement in core clinical tasks awaits fundamental breakthroughs in multimodal integration and visual understanding.
FoMo4Wheat: Toward reliable crop vision foundation models with globally curated data
Sep 08, 2025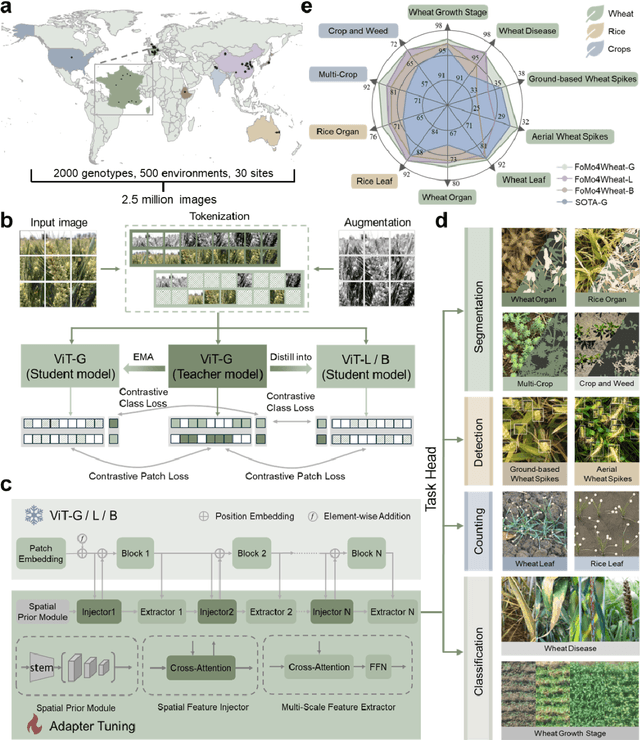

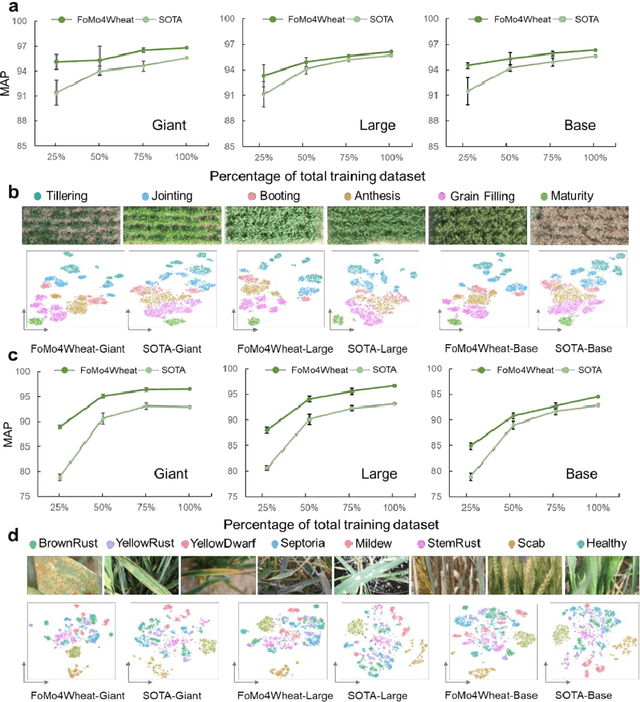
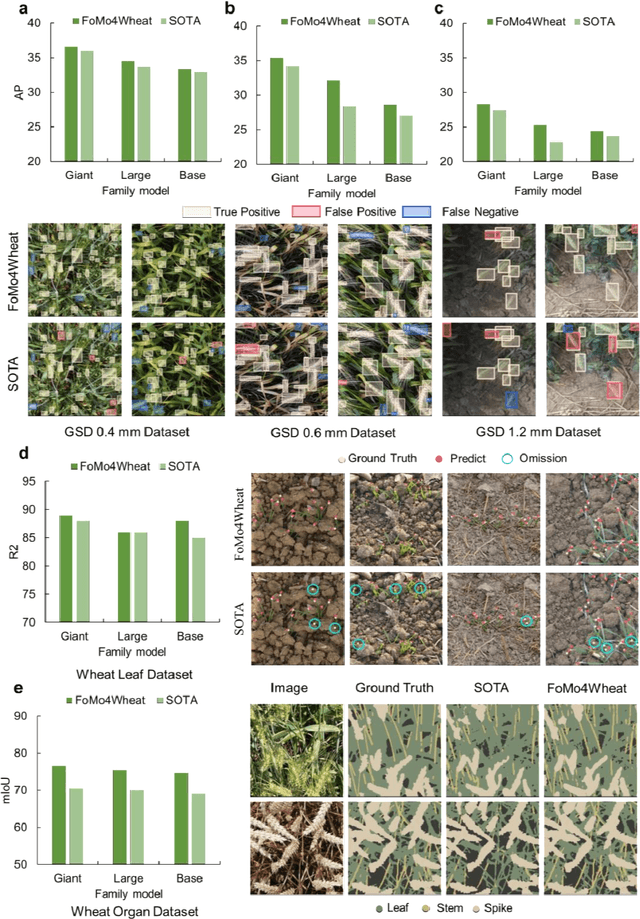
Vision-driven field monitoring is central to digital agriculture, yet models built on general-domain pretrained backbones often fail to generalize across tasks, owing to the interaction of fine, variable canopy structures with fluctuating field conditions. We present FoMo4Wheat, one of the first crop-domain vision foundation model pretrained with self-supervision on ImAg4Wheat, the largest and most diverse wheat image dataset to date (2.5 million high-resolution images collected over a decade at 30 global sites, spanning >2,000 genotypes and >500 environmental conditions). This wheat-specific pretraining yields representations that are robust for wheat and transferable to other crops and weeds. Across ten in-field vision tasks at canopy and organ levels, FoMo4Wheat models consistently outperform state-of-the-art models pretrained on general-domain dataset. These results demonstrate the value of crop-specific foundation models for reliable in-field perception and chart a path toward a universal crop foundation model with cross-species and cross-task capabilities. FoMo4Wheat models and the ImAg4Wheat dataset are publicly available online: https://github.com/PheniX-Lab/FoMo4Wheat and https://huggingface.co/PheniX-Lab/FoMo4Wheat. The demonstration website is: https://fomo4wheat.phenix-lab.com/.
Multi-Agent Generative Adversarial Interactive Self-Imitation Learning for AUV Formation Control and Obstacle Avoidance
Jan 21, 2024Multiple autonomous underwater vehicles (multi-AUV) can cooperatively accomplish tasks that a single AUV cannot complete. Recently, multi-agent reinforcement learning has been introduced to control of multi-AUV. However, designing efficient reward functions for various tasks of multi-AUV control is difficult or even impractical. Multi-agent generative adversarial imitation learning (MAGAIL) allows multi-AUV to learn from expert demonstration instead of pre-defined reward functions, but suffers from the deficiency of requiring optimal demonstrations and not surpassing provided expert demonstrations. This paper builds upon the MAGAIL algorithm by proposing multi-agent generative adversarial interactive self-imitation learning (MAGAISIL), which can facilitate AUVs to learn policies by gradually replacing the provided sub-optimal demonstrations with self-generated good trajectories selected by a human trainer. Our experimental results in a multi-AUV formation control and obstacle avoidance task on the Gazebo platform with AUV simulator of our lab show that AUVs trained via MAGAISIL can surpass the provided sub-optimal expert demonstrations and reach a performance close to or even better than MAGAIL with optimal demonstrations. Further results indicate that AUVs' policies trained via MAGAISIL can adapt to complex and different tasks as well as MAGAIL learning from optimal demonstrations.
Natural Adversarial Patch Generation Method Based on Latent Diffusion Model
Dec 27, 2023Recently, some research show that deep neural networks are vulnerable to the adversarial attacks, the well-trainned samples or patches could be used to trick the neural network detector or human visual perception. However, these adversarial patches, with their conspicuous and unusual patterns, lack camouflage and can easily raise suspicion in the real world. To solve this problem, this paper proposed a novel adversarial patch method called the Latent Diffusion Patch (LDP), in which, a pretrained encoder is first designed to compress the natural images into a feature space with key characteristics. Then trains the diffusion model using the above feature space. Finally, explore the latent space of the pretrained diffusion model using the image denoising technology. It polishes the patches and images through the powerful natural abilities of diffusion models, making them more acceptable to the human visual system. Experimental results, both digital and physical worlds, show that LDPs achieve a visual subjectivity score of 87.3%, while still maintaining effective attack capabilities.
NTIRE 2022 Challenge on Super-Resolution and Quality Enhancement of Compressed Video: Dataset, Methods and Results
Apr 25, 2022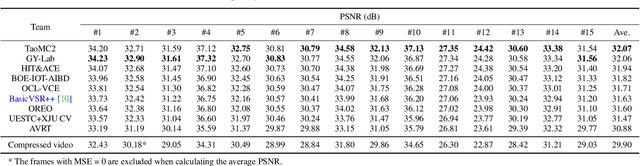
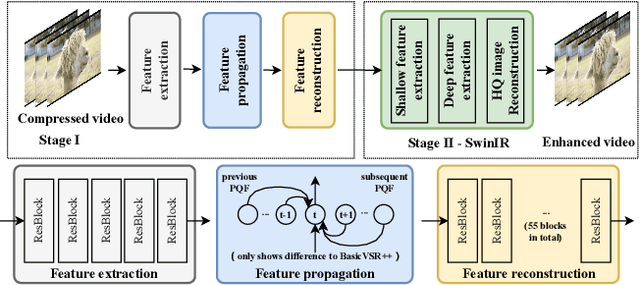
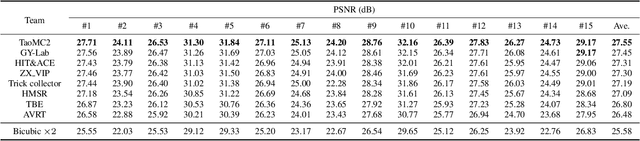

This paper reviews the NTIRE 2022 Challenge on Super-Resolution and Quality Enhancement of Compressed Video. In this challenge, we proposed the LDV 2.0 dataset, which includes the LDV dataset (240 videos) and 95 additional videos. This challenge includes three tracks. Track 1 aims at enhancing the videos compressed by HEVC at a fixed QP. Track 2 and Track 3 target both the super-resolution and quality enhancement of HEVC compressed video. They require x2 and x4 super-resolution, respectively. The three tracks totally attract more than 600 registrations. In the test phase, 8 teams, 8 teams and 12 teams submitted the final results to Tracks 1, 2 and 3, respectively. The proposed methods and solutions gauge the state-of-the-art of super-resolution and quality enhancement of compressed video. The proposed LDV 2.0 dataset is available at https://github.com/RenYang-home/LDV_dataset. The homepage of this challenge (including open-sourced codes) is at https://github.com/RenYang-home/NTIRE22_VEnh_SR.
FSD-10: A Dataset for Competitive Sports Content Analysis
Feb 09, 2020

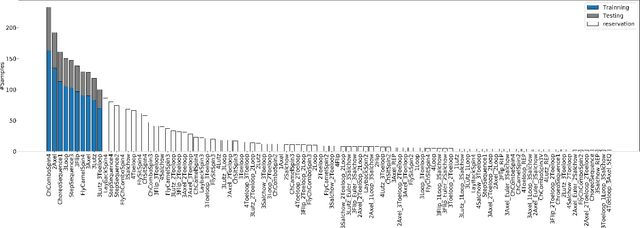
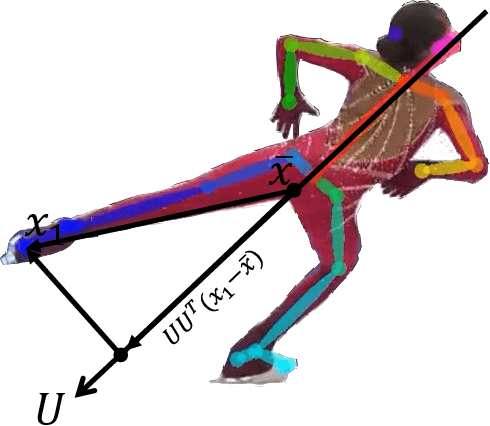
Action recognition is an important and challenging problem in video analysis. Although the past decade has witnessed progress in action recognition with the development of deep learning, such process has been slow in competitive sports content analysis. To promote the research on action recognition from competitive sports video clips, we introduce a Figure Skating Dataset (FSD-10) for finegrained sports content analysis. To this end, we collect 1484 clips from the worldwide figure skating championships in 2017-2018, which consist of 10 different actions in men/ladies programs. Each clip is at a rate of 30 frames per second with resolution 1080 $\times$ 720. These clips are then annotated by experts in type, grade of execution, skater info, .etc. To build a baseline for action recognition in figure skating, we evaluate state-of-the-art action recognition methods on FSD-10. Motivated by the idea that domain knowledge is of great concern in sports field, we propose a keyframe based temporal segment network (KTSN) for classification and achieve remarkable performance. Experimental results demonstrate that FSD-10 is an ideal dataset for benchmarking action recognition algorithms, as it requires to accurately extract action motions rather than action poses. We hope FSD-10, which is designed to have a large collection of finegrained actions, can serve as a new challenge to develop more robust and advanced action recognition models.
Color Recognition for Rubik's Cube Robot
Jan 11, 2019
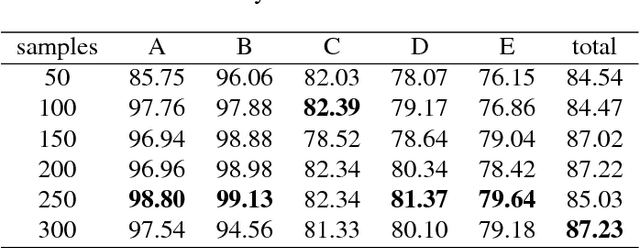
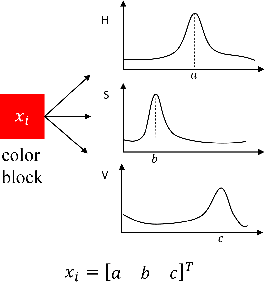
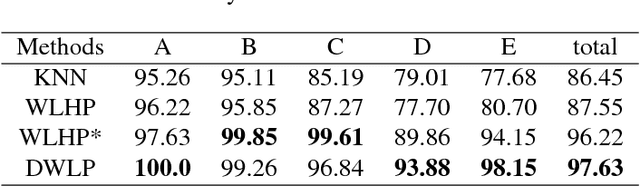
In this paper, we proposed three methods to solve color recognition of Rubik's cube, which includes one offline method and two online methods. Scatter balance \& extreme learning machine (SB-ELM), a offline method, is proposed to illustrate the efficiency of training based method. We also point out the conception of color drifting which indicates offline methods are always ineffectiveness and can not work well in continuous change circumstance. By contrast, dynamic weight label propagation is proposed for labeling blocks color by known center blocks color of Rubik's cube. Furthermore, weak label hierarchic propagation, another online method, is also proposed for unknown all color information but only utilizes weak label of center block in color recognition. We finally design a Rubik's cube robot and construct a dataset to illustrate the efficiency and effectiveness of our online methods and to indicate the ineffectiveness of offline method by color drifting in our dataset.