 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Generative Adversarial Interactive Self-Imitation Learning for AUV Formation Control and Obstacle Avoidance
Jan 21, 2024Multiple autonomous underwater vehicles (multi-AUV) can cooperatively accomplish tasks that a single AUV cannot complete. Recently, multi-agent reinforcement learning has been introduced to control of multi-AUV. However, designing efficient reward functions for various tasks of multi-AUV control is difficult or even impractical. Multi-agent generative adversarial imitation learning (MAGAIL) allows multi-AUV to learn from expert demonstration instead of pre-defined reward functions, but suffers from the deficiency of requiring optimal demonstrations and not surpassing provided expert demonstrations. This paper builds upon the MAGAIL algorithm by proposing multi-agent generative adversarial interactive self-imitation learning (MAGAISIL), which can facilitate AUVs to learn policies by gradually replacing the provided sub-optimal demonstrations with self-generated good trajectories selected by a human trainer. Our experimental results in a multi-AUV formation control and obstacle avoidance task on the Gazebo platform with AUV simulator of our lab show that AUVs trained via MAGAISIL can surpass the provided sub-optimal expert demonstrations and reach a performance close to or even better than MAGAIL with optimal demonstrations. Further results indicate that AUVs' policies trained via MAGAISIL can adapt to complex and different tasks as well as MAGAIL learning from optimal demonstrations.
GAN-Based Interactive Reinforcement Learning from Demonstration and Human Evaluative Feedback
Apr 14, 2021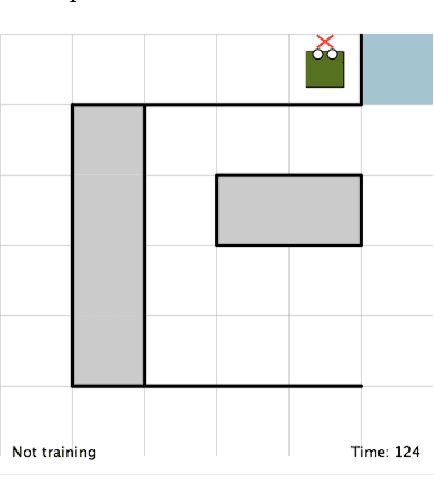
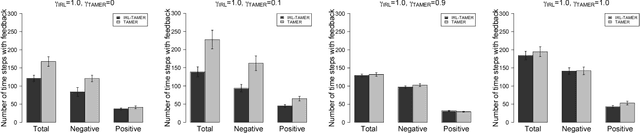
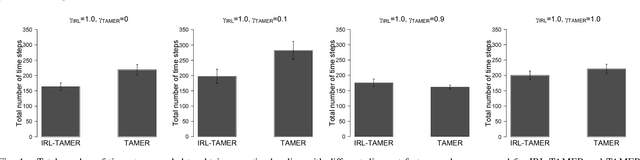
Deep reinforcement learning (DRL) has achieved great successes in many simulated tasks. The sample inefficiency problem makes applying traditional DRL methods to real-world robots a great challenge. Generative Adversarial Imitation Learning (GAIL) -- a general model-free imitation learning method, allows robots to directly learn policies from expert trajectories in large environments. However, GAIL shares the limitation of other imitation learning methods that they can seldom surpass the performance of demonstrations. In this paper, to address the limit of GAIL, we propose GAN-Based Interactive Reinforcement Learning (GAIRL) from demonstration and human evaluative feedback by combining the advantages of GAIL and interactive reinforcement learning. We tested our proposed method in six physics-based control tasks, ranging from simple low-dimensional control tasks -- Cart Pole and Mountain Car, to difficult high-dimensional tasks -- Inverted Double Pendulum, Lunar Lander, Hopper and HalfCheetah. Our results suggest that with both optimal and suboptimal demonstrations, a GAIRL agent can always learn a more stable policy with optimal or close to optimal performance, while the performance of the GAIL agent is upper bounded by the performance of demonstrations or even worse than it. In addition, our results indicate the reason that GAIRL is superior over GAIL is the complementary effect of demonstrations and human evaluative feedback.
Facial Feedback for Reinforcement Learning: A Case Study and Offline Analysis Using the TAMER Framework
Jan 23, 2020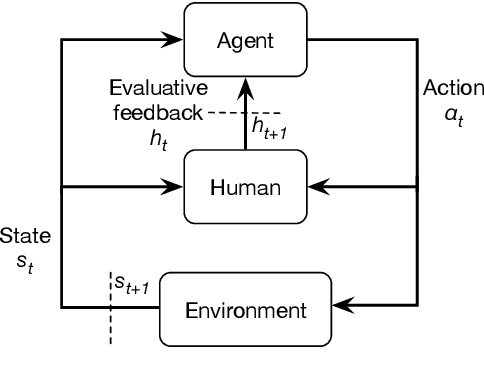
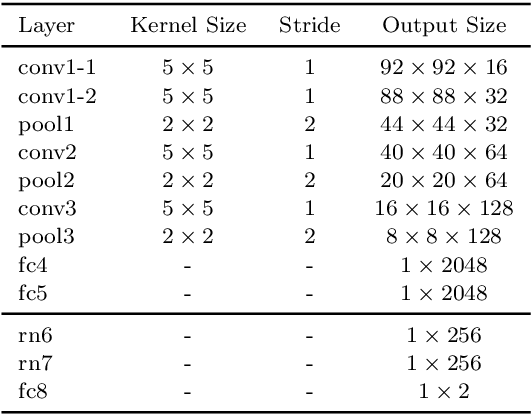
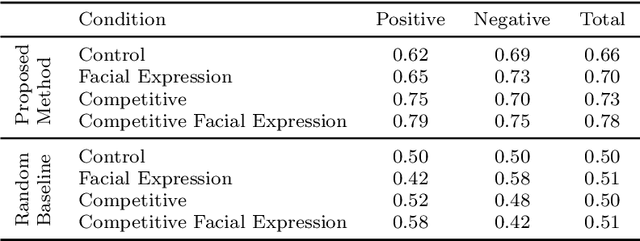
Interactive reinforcement learning provides a way for agents to learn to solve tasks from evaluative feedback provided by a human user. Previous research showed that humans give copious feedback early in training but very sparsely thereafter. In this article, we investigate the potential of agent learning from trainers' facial expressions via interpreting them as evaluative feedback. To do so, we implemented TAMER which is a popular interactive reinforcement learning method in a reinforcement-learning benchmark problem --- Infinite Mario, and conducted the first large-scale study of TAMER involving 561 participants. With designed CNN-RNN model, our analysis shows that telling trainers to use facial expressions and competition can improve the accuracies for estimating positive and negative feedback using facial expressions. In addition, our results with a simulation experiment show that learning solely from predicted feedback based on facial expressions is possible and using strong/effective prediction models or a regression method, facial responses would significantly improve the performance of agents. Furthermore, our experiment supports previous studies demonstrating the importance of bi-directional feedback and competitive elements in the training interface.
Deep Interactive Reinforcement Learning for Path Following of Autonomous Underwater Vehicle
Jan 10, 2020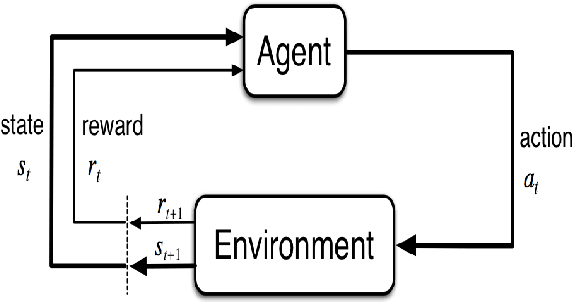
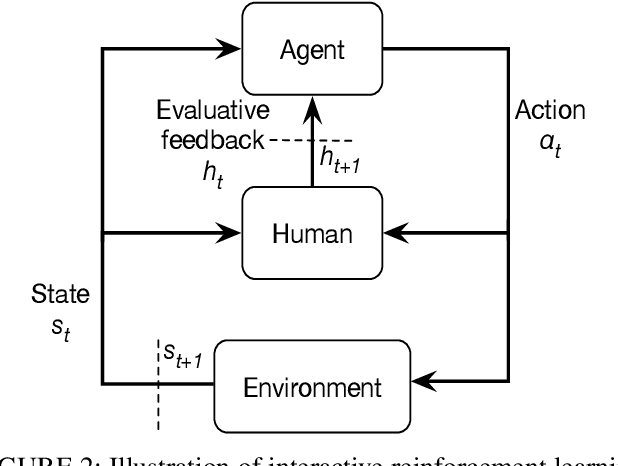
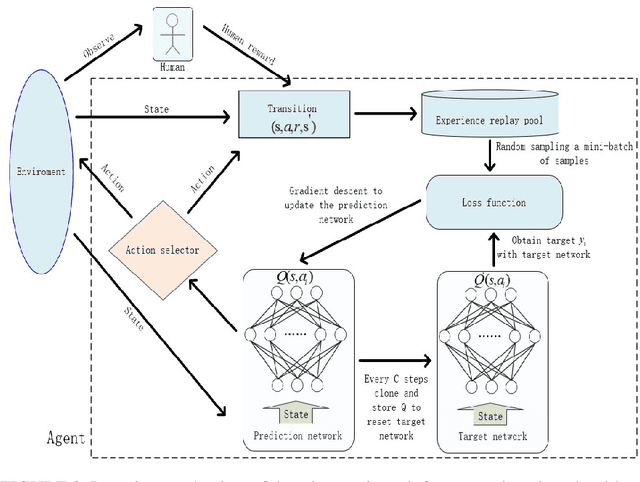
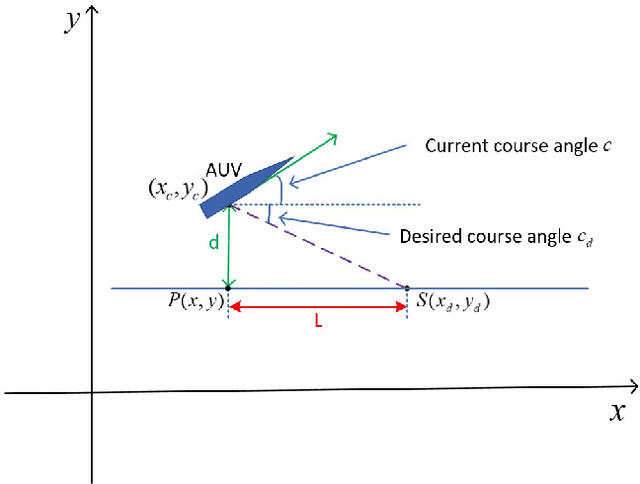
Autonomous underwater vehicle (AUV) plays an increasingly important role in ocean exploration. Existing AUVs are usually not fully autonomous and generally limited to pre-planning or pre-programming tasks. Reinforcement learning (RL) and deep reinforcement learning have been introduced into the AUV design and research to improve its autonomy. However, these methods are still difficult to apply directly to the actual AUV system because of the sparse rewards and low learning efficiency. In this paper, we proposed a deep interactive reinforcement learning method for path following of AUV by combining the advantages of deep reinforcement learning and interactive RL. In addition, since the human trainer cannot provide human rewards for AUV when it is running in the ocean and AUV needs to adapt to a changing environment, we further propose a deep reinforcement learning method that learns from both human rewards and environmental rewards at the same time. We test our methods in two path following tasks---straight line and sinusoids curve following of AUV by simulating in the Gazebo platform. Our experimental results show that with our proposed deep interactive RL method, AUV can converge faster than a DQN learner from only environmental reward. Moreover, AUV learning with our deep RL from both human and environmental rewards can also achieve a similar or even better performance than that with the deep interactive RL method and can adapt to the actual environment by further learning from environmental rewards.
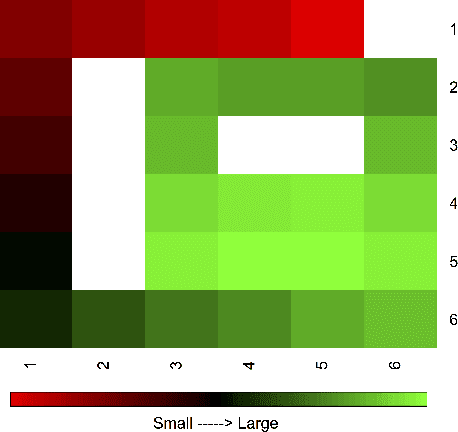
Improving Interactive Reinforcement Agent Planning with Human Demonstration
Apr 18, 2019
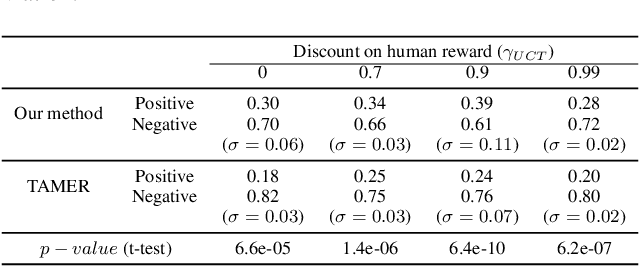

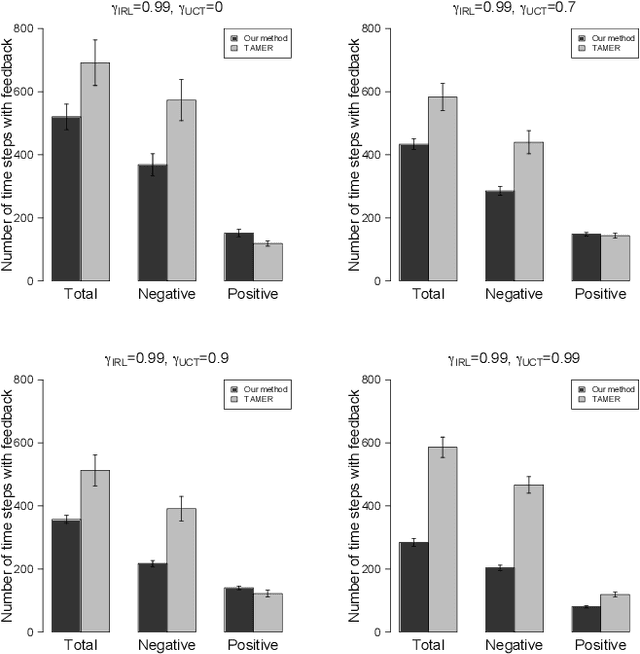
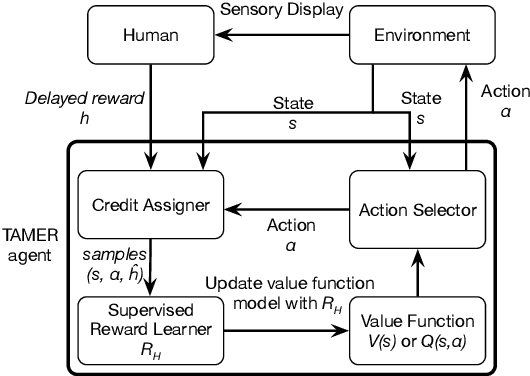
TAMER has proven to be a powerful interactive reinforcement learning method for allowing ordinary people to teach and personalize autonomous agents' behavior by providing evaluative feedback. However, a TAMER agent planning with UCT---a Monte Carlo Tree Search strategy, can only update states along its path and might induce high learning cost especially for a physical robot. In this paper, we propose to drive the agent's exploration along the optimal path and reduce the learning cost by initializing the agent's reward function via inverse reinforcement learning from demonstration. We test our proposed method in the RL benchmark domain---Grid World---with different discounts on human reward. Our results show that learning from demonstration can allow a TAMER agent to learn a roughly optimal policy up to the deepest search and encourage the agent to explore along the optimal path. In addition, we find that learning from demonstration can improve the learning efficiency by reducing total feedback, the number of incorrect actions and increasing the ratio of correct actions to obtain an optimal policy, allowing a TAMER agent to converge faster.
Learning Shaping Strategies in Human-in-the-loop Interactive Reinforcement Learning
Nov 10, 2018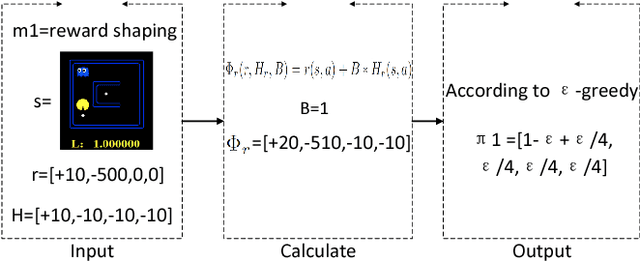
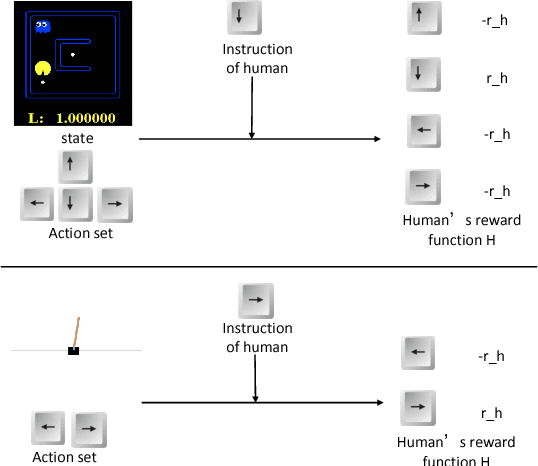
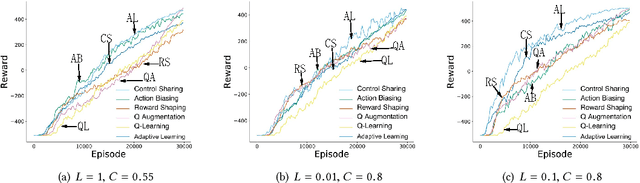
Providing reinforcement learning agents with informationally rich human knowledge can dramatically improve various aspects of learning. Prior work has developed different kinds of shaping methods that enable agents to learn efficiently in complex environments. All these methods, however, tailor human guidance to agents in specialized shaping procedures, thus embodying various characteristics and advantages in different domains. In this paper, we investigate the interplay between different shaping methods for more robust learning performance. We propose an adaptive shaping algorithm which is capable of learning the most suitable shaping method in an on-line manner. Results in two classic domains verify its effectiveness from both simulated and real human studies, shedding some light on the role and impact of human factors in human-robot collaborative learning.