 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Label Sentiment Analysis on 100 Languages with Dynamic Weighting for Label Imbalance
Aug 26, 2020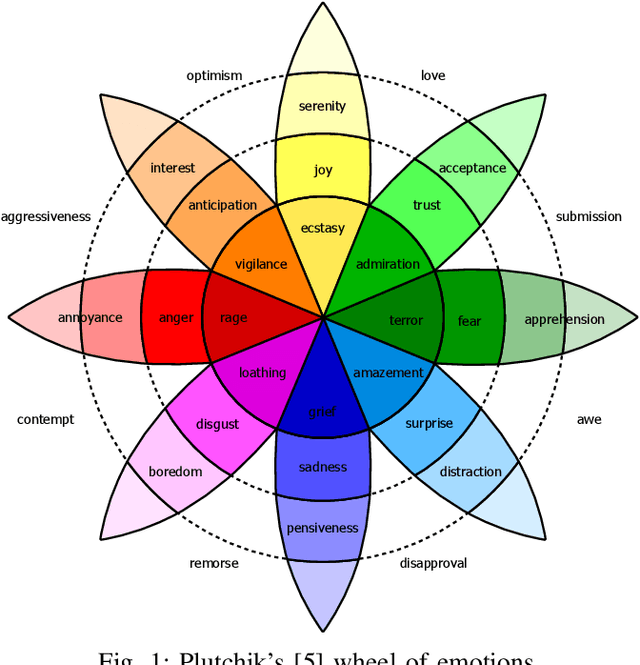
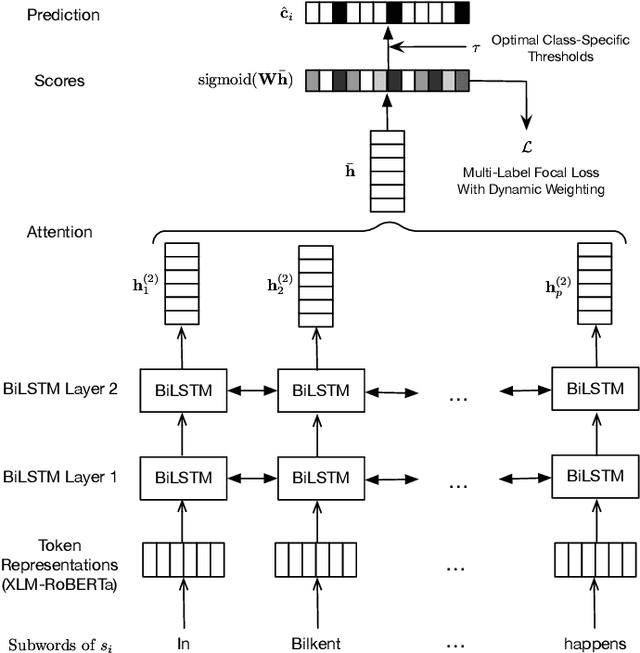
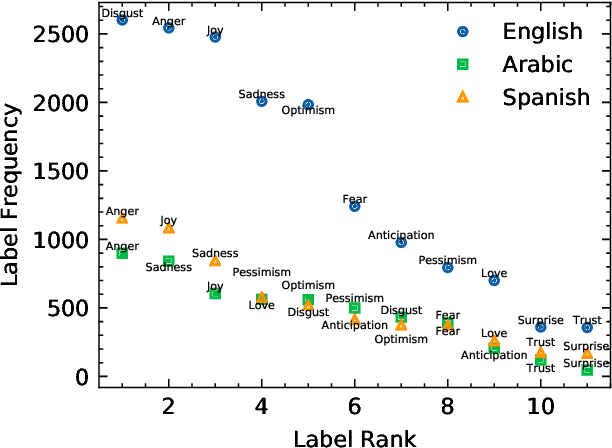
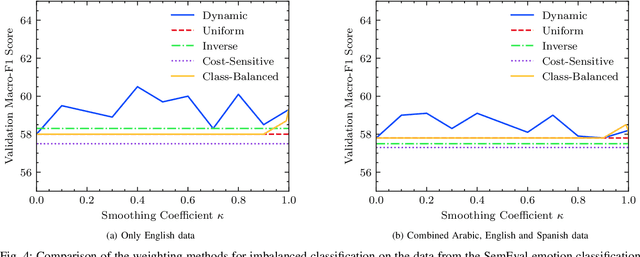
We investigate cross-lingual sentiment analysis, which has attracted significant attention due to its applications in various areas including market research, politics and social sciences. In particular, we introduce a sentiment analysis framework in multi-label setting as it obeys Plutchik wheel of emotions. We introduce a novel dynamic weighting method that balances the contribution from each class during training, unlike previous static weighting methods that assign non-changing weights based on their class frequency. Moreover, we adapt the focal loss that favors harder instances from single-label object recognition literature to our multi-label setting. Furthermore, we derive a method to choose optimal class-specific thresholds that maximize the macro-f1 score in linear time complexity. Through an extensive set of experiments, we show that our method obtains the state-of-the-art performance in 7 of 9 metrics in 3 different languages using a single model compared to the common baselines and the best-performing methods in the SemEval competition. We publicly share our code for our model, which can perform sentiment analysis in 100 languages, to facilitate further research.
Facial Feedback for Reinforcement Learning: A Case Study and Offline Analysis Using the TAMER Framework
Jan 23, 2020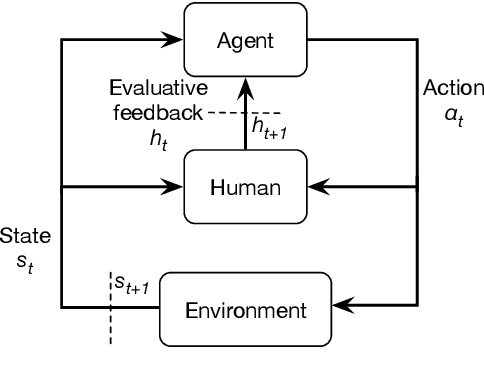
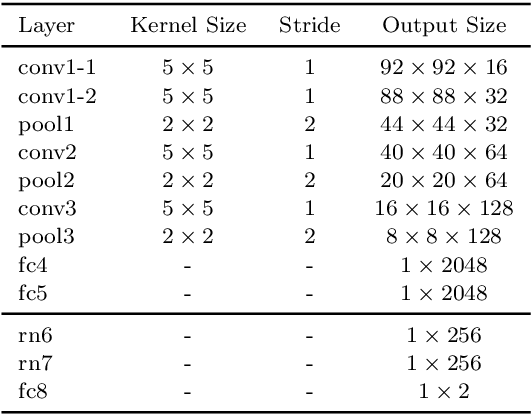
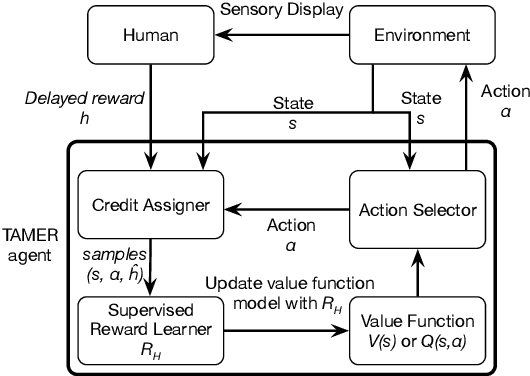
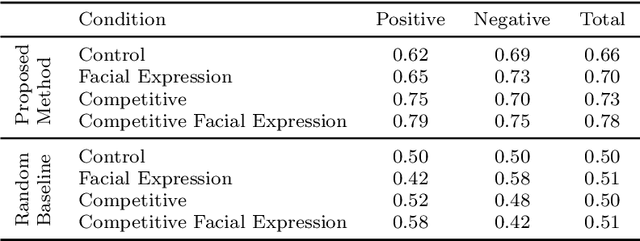
Interactive reinforcement learning provides a way for agents to learn to solve tasks from evaluative feedback provided by a human user. Previous research showed that humans give copious feedback early in training but very sparsely thereafter. In this article, we investigate the potential of agent learning from trainers' facial expressions via interpreting them as evaluative feedback. To do so, we implemented TAMER which is a popular interactive reinforcement learning method in a reinforcement-learning benchmark problem --- Infinite Mario, and conducted the first large-scale study of TAMER involving 561 participants. With designed CNN-RNN model, our analysis shows that telling trainers to use facial expressions and competition can improve the accuracies for estimating positive and negative feedback using facial expressions. In addition, our results with a simulation experiment show that learning solely from predicted feedback based on facial expressions is possible and using strong/effective prediction models or a regression method, facial responses would significantly improve the performance of agents. Furthermore, our experiment supports previous studies demonstrating the importance of bi-directional feedback and competitive elements in the training interface.
Attended End-to-end Architecture for Age Estimation from Facial Expression Videos
Nov 23, 2017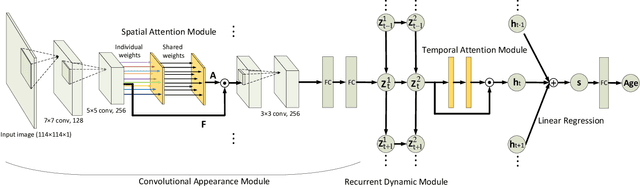
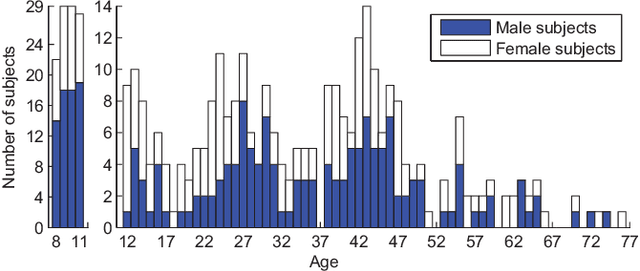
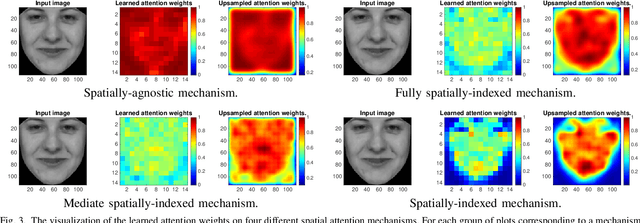
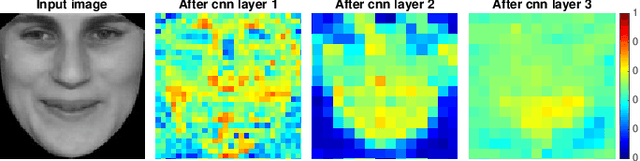
The main challenges of age estimation from facial expression videos lie not only in the modeling of the static facial appearance, but also in the capturing of the temporal facial dynamics. Traditional techniques to this problem focus on constructing handcrafted features to explore the discriminative information contained in facial appearance and dynamics separately. This relies on sophisticated feature-refinement and framework-design. In this paper, we present an end-to-end architecture for age estimation which is able to simultaneously learn both the appearance and dynamics of age from raw videos of facial expressions. Specifically, we employ convolutional neural networks to extract effective latent appearance representations and feed them into recurrent networks to model the temporal dynamics. More importantly, we propose to leverage attention models for salience detection in both the spatial domain for each single image and the temporal domain for the whole video as well. We design a specific spatially-indexed attention mechanism among the convolutional layers to extract the salient facial regions in each individual image, and a temporal attention layer to assign attention weights to each frame. This two-pronged approach not only improves the performance by allowing the model to focus on informative frames and facial areas, but it also offers an interpretable correspondence between the spatial facial regions as well as temporal frames, and the task of age estimation. We demonstrate the strong performance of our model in experiments on a large, gender-balanced database with 400 subjects with ages spanning from 8 to 76 years. Experiments reveal that our model exhibits significant superiority over the state-of-the-art methods given sufficient training data.
Time Series Classification using the Hidden-Unit Logistic Model
Jan 19, 2016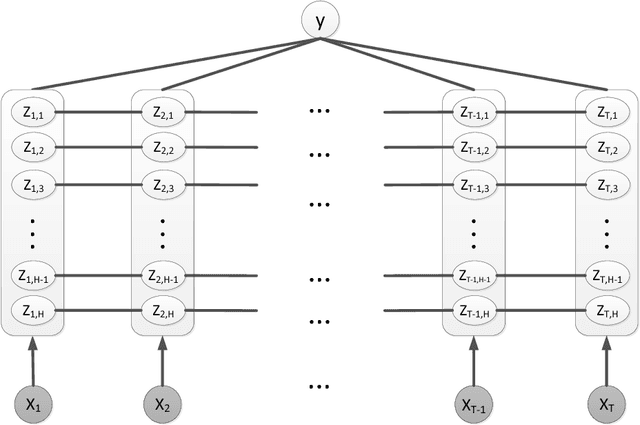
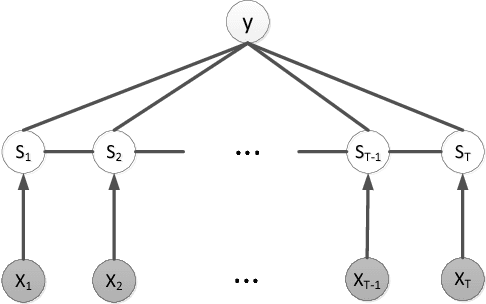
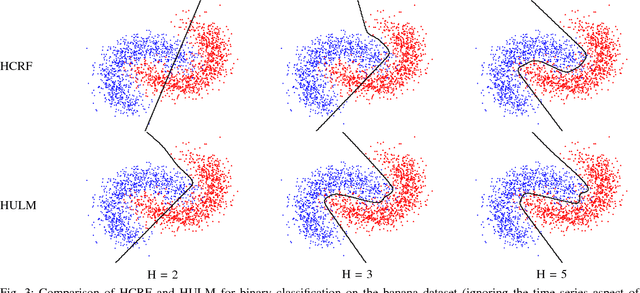
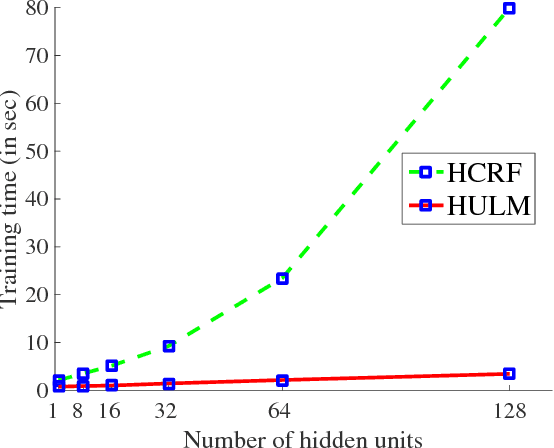
We present a new model for time series classification, called the hidden-unit logistic model, that uses binary stochastic hidden units to model latent structure in the data. The hidden units are connected in a chain structure that models temporal dependencies in the data. Compared to the prior models for time series classification such as the hidden conditional random field, our model can model very complex decision boundaries because the number of latent states grows exponentially with the number of hidden units. We demonstrate the strong performance of our model in experiments on a variety of (computer vision) tasks, including handwritten character recognition, speech recognition, facial expression, and action recognition. We also present a state-of-the-art system for facial action unit detection based on the hidden-unit logistic model.