 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Shaping Strategies in Human-in-the-loop Interactive Reinforcement Learning
Nov 10, 2018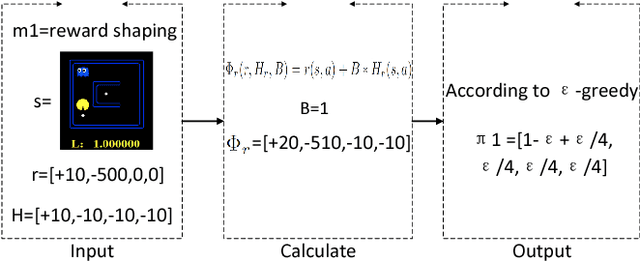
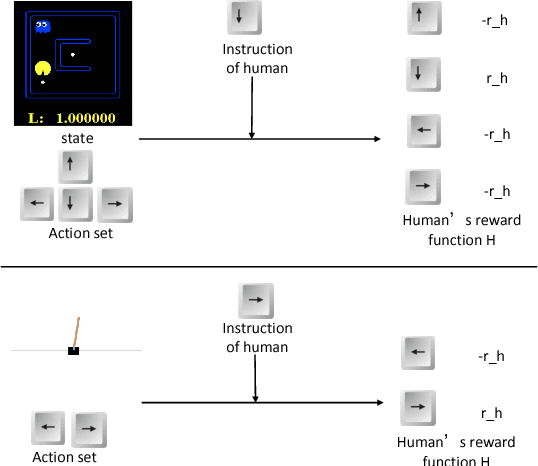
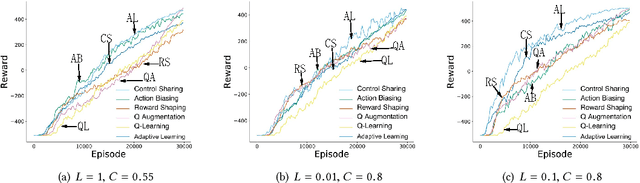
Providing reinforcement learning agents with informationally rich human knowledge can dramatically improve various aspects of learning. Prior work has developed different kinds of shaping methods that enable agents to learn efficiently in complex environments. All these methods, however, tailor human guidance to agents in specialized shaping procedures, thus embodying various characteristics and advantages in different domains. In this paper, we investigate the interplay between different shaping methods for more robust learning performance. We propose an adaptive shaping algorithm which is capable of learning the most suitable shaping method in an on-line manner. Results in two classic domains verify its effectiveness from both simulated and real human studies, shedding some light on the role and impact of human factors in human-robot collaborative learning.