 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGAN-Based Interactive Reinforcement Learning from Demonstration and Human Evaluative Feedback
Apr 14, 2021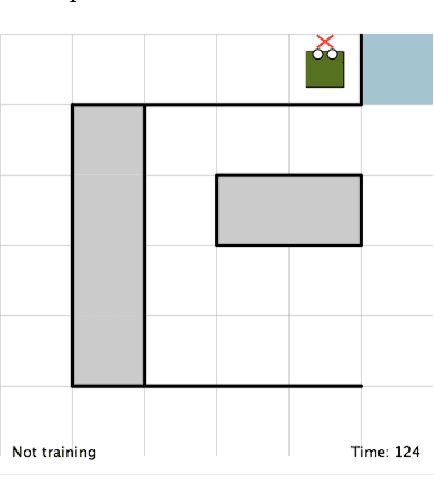
Deep reinforcement learning (DRL) has achieved great successes in many simulated tasks. The sample inefficiency problem makes applying traditional DRL methods to real-world robots a great challenge. Generative Adversarial Imitation Learning (GAIL) -- a general model-free imitation learning method, allows robots to directly learn policies from expert trajectories in large environments. However, GAIL shares the limitation of other imitation learning methods that they can seldom surpass the performance of demonstrations. In this paper, to address the limit of GAIL, we propose GAN-Based Interactive Reinforcement Learning (GAIRL) from demonstration and human evaluative feedback by combining the advantages of GAIL and interactive reinforcement learning. We tested our proposed method in six physics-based control tasks, ranging from simple low-dimensional control tasks -- Cart Pole and Mountain Car, to difficult high-dimensional tasks -- Inverted Double Pendulum, Lunar Lander, Hopper and HalfCheetah. Our results suggest that with both optimal and suboptimal demonstrations, a GAIRL agent can always learn a more stable policy with optimal or close to optimal performance, while the performance of the GAIL agent is upper bounded by the performance of demonstrations or even worse than it. In addition, our results indicate the reason that GAIRL is superior over GAIL is the complementary effect of demonstrations and human evaluative feedback.
Improving Interactive Reinforcement Agent Planning with Human Demonstration
Apr 18, 2019
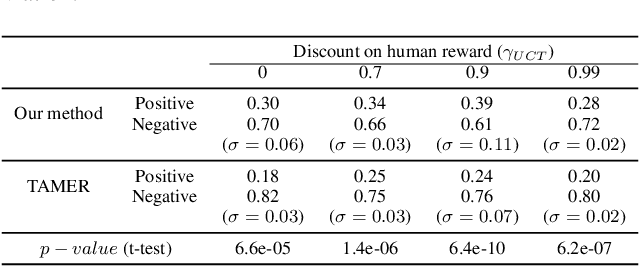

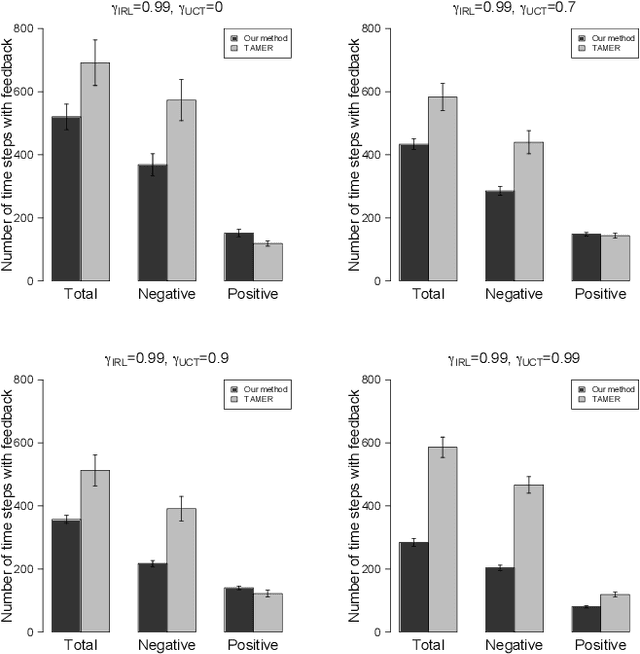
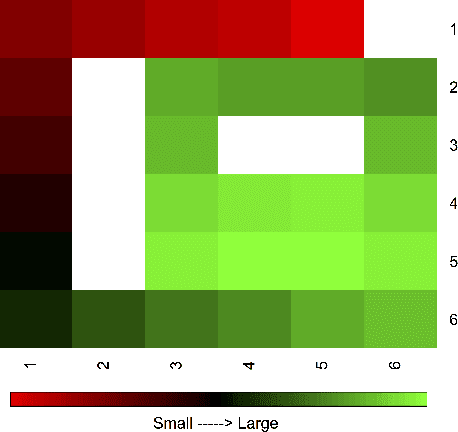
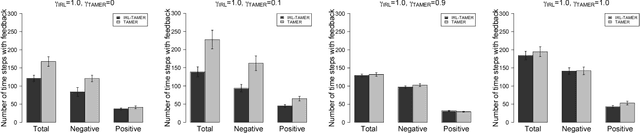
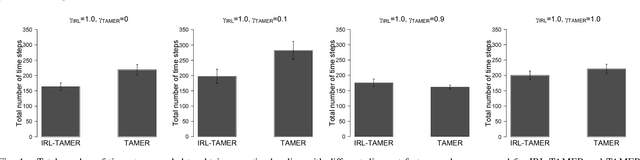
TAMER has proven to be a powerful interactive reinforcement learning method for allowing ordinary people to teach and personalize autonomous agents' behavior by providing evaluative feedback. However, a TAMER agent planning with UCT---a Monte Carlo Tree Search strategy, can only update states along its path and might induce high learning cost especially for a physical robot. In this paper, we propose to drive the agent's exploration along the optimal path and reduce the learning cost by initializing the agent's reward function via inverse reinforcement learning from demonstration. We test our proposed method in the RL benchmark domain---Grid World---with different discounts on human reward. Our results show that learning from demonstration can allow a TAMER agent to learn a roughly optimal policy up to the deepest search and encourage the agent to explore along the optimal path. In addition, we find that learning from demonstration can improve the learning efficiency by reducing total feedback, the number of incorrect actions and increasing the ratio of correct actions to obtain an optimal policy, allowing a TAMER agent to converge faster.