 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Model-Assisted Superconducting Qubit Experiments
Mar 09, 2026Superconducting circuits have demonstrated significant potential in quantum information processing and quantum sensing. Implementing novel control and measurement sequences for superconducting qubits is often a complex and time-consuming process, requiring extensive expertise in both the underlying physics and the specific hardware and software. In this work, we introduce a framework that leverages a large language model (LLM) to automate qubit control and measurement. Specifically, our framework conducts experiments by generating and invoking schema-less tools on demand via a knowledge base on instrumental usage and experimental procedures. We showcase this framework with two experiments: an autonomous resonator characterization and a direct reproduction of a quantum non-demolition (QND) characterization of a superconducting qubit from literature. This framework enables rapid deployment of standard control-and-measurement protocols and facilitates implementation of novel experimental procedures, offering a more flexible and user-friendly paradigm for controlling complex quantum hardware.
Stochastic Gradient Descent in Non-Convex Problems: Asymptotic Convergence with Relaxed Step-Size via Stopping Time Methods
Apr 17, 2025Stochastic Gradient Descent (SGD) is widely used in machine learning research. Previous convergence analyses of SGD under the vanishing step-size setting typically require Robbins-Monro conditions. However, in practice, a wider variety of step-size schemes are frequently employed, yet existing convergence results remain limited and often rely on strong assumptions. This paper bridges this gap by introducing a novel analytical framework based on a stopping-time method, enabling asymptotic convergence analysis of SGD under more relaxed step-size conditions and weaker assumptions. In the non-convex setting, we prove the almost sure convergence of SGD iterates for step-sizes $ \{ \epsilon_t \}_{t \geq 1} $ satisfying $\sum_{t=1}^{+\infty} \epsilon_t = +\infty$ and $\sum_{t=1}^{+\infty} \epsilon_t^p < +\infty$ for some $p > 2$. Compared with previous studies, our analysis eliminates the global Lipschitz continuity assumption on the loss function and relaxes the boundedness requirements for higher-order moments of stochastic gradients. Building upon the almost sure convergence results, we further establish $L_2$ convergence. These significantly relaxed assumptions make our theoretical results more general, thereby enhancing their applicability in practical scenarios.
Cog-GA: A Large Language Models-based Generative Agent for Vision-Language Navigation in Continuous Environments
Sep 04, 2024Vision Language Navigation in Continuous Environments (VLN-CE) represents a frontier in embodied AI, demanding agents to navigate freely in unbounded 3D spaces solely guided by natural language instructions. This task introduces distinct challenges in multimodal comprehension, spatial reasoning, and decision-making. To address these challenges, we introduce Cog-GA, a generative agent founded on large language models (LLMs) tailored for VLN-CE tasks. Cog-GA employs a dual-pronged strategy to emulate human-like cognitive processes. Firstly, it constructs a cognitive map, integrating temporal, spatial, and semantic elements, thereby facilitating the development of spatial memory within LLMs. Secondly, Cog-GA employs a predictive mechanism for waypoints, strategically optimizing the exploration trajectory to maximize navigational efficiency. Each waypoint is accompanied by a dual-channel scene description, categorizing environmental cues into 'what' and 'where' streams as the brain. This segregation enhances the agent's attentional focus, enabling it to discern pertinent spatial information for navigation. A reflective mechanism complements these strategies by capturing feedback from prior navigation experiences, facilitating continual learning and adaptive replanning. Extensive evaluations conducted on VLN-CE benchmarks validate Cog-GA's state-of-the-art performance and ability to simulate human-like navigation behaviors. This research significantly contributes to the development of strategic and interpretable VLN-CE agents.
Vision-Language Navigation with Continual Learning
Sep 04, 2024Vision-language navigation (VLN) is a critical domain within embedded intelligence, requiring agents to navigate 3D environments based on natural language instructions. Traditional VLN research has focused on improving environmental understanding and decision accuracy. However, these approaches often exhibit a significant performance gap when agents are deployed in novel environments, mainly due to the limited diversity of training data. Expanding datasets to cover a broader range of environments is impractical and costly. We propose the Vision-Language Navigation with Continual Learning (VLNCL) paradigm to address this challenge. In this paradigm, agents incrementally learn new environments while retaining previously acquired knowledge. VLNCL enables agents to maintain an environmental memory and extract relevant knowledge, allowing rapid adaptation to new environments while preserving existing information. We introduce a novel dual-loop scenario replay method (Dual-SR) inspired by brain memory replay mechanisms integrated with VLN agents. This method facilitates consolidating past experiences and enhances generalization across new tasks. By utilizing a multi-scenario memory buffer, the agent efficiently organizes and replays task memories, thereby bolstering its ability to adapt quickly to new environments and mitigating catastrophic forgetting. Our work pioneers continual learning in VLN agents, introducing a novel experimental setup and evaluation metrics. We demonstrate the effectiveness of our approach through extensive evaluations and establish a benchmark for the VLNCL paradigm. Comparative experiments with existing continual learning and VLN methods show significant improvements, achieving state-of-the-art performance in continual learning ability and highlighting the potential of our approach in enabling rapid adaptation while preserving prior knowledge.
Spiking Neural Network for Ultra-low-latency and High-accurate Object Detection
Jun 27, 2023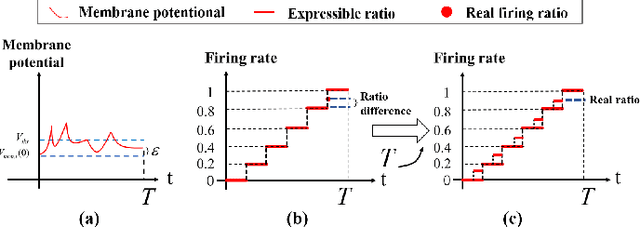
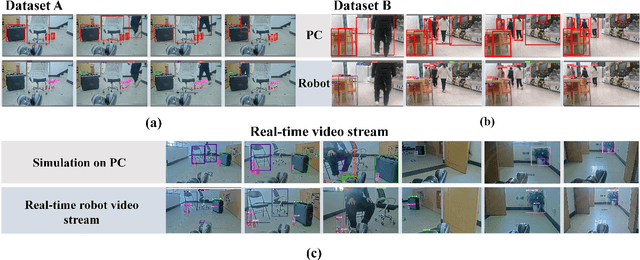
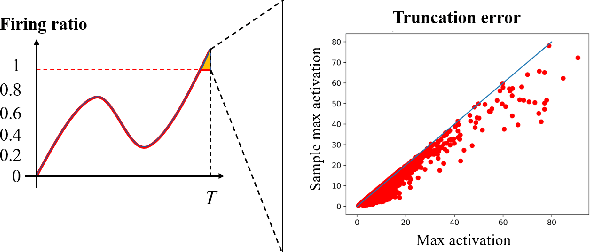
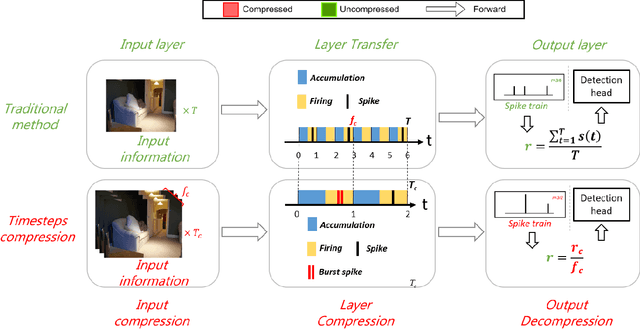
Spiking Neural Networks (SNNs) have garnered widespread interest for their energy efficiency and brain-inspired event-driven properties. While recent methods like Spiking-YOLO have expanded the SNNs to more challenging object detection tasks, they often suffer from high latency and low detection accuracy, making them difficult to deploy on latency sensitive mobile platforms. Furthermore, the conversion method from Artificial Neural Networks (ANNs) to SNNs is hard to maintain the complete structure of the ANNs, resulting in poor feature representation and high conversion errors. To address these challenges, we propose two methods: timesteps compression and spike-time-dependent integrated (STDI) coding. The former reduces the timesteps required in ANN-SNN conversion by compressing information, while the latter sets a time-varying threshold to expand the information holding capacity. We also present a SNN-based ultra-low latency and high accurate object detection model (SUHD) that achieves state-of-the-art performance on nontrivial datasets like PASCAL VOC and MS COCO, with about remarkable 750x fewer timesteps and 30% mean average precision (mAP) improvement, compared to the Spiking-YOLO on MS COCO datasets. To the best of our knowledge, SUHD is the deepest spike-based object detection model to date that achieves ultra low timesteps to complete the lossless conversion.
Automatically Discovering Novel Visual Categories with Self-supervised Prototype Learning
Aug 01, 2022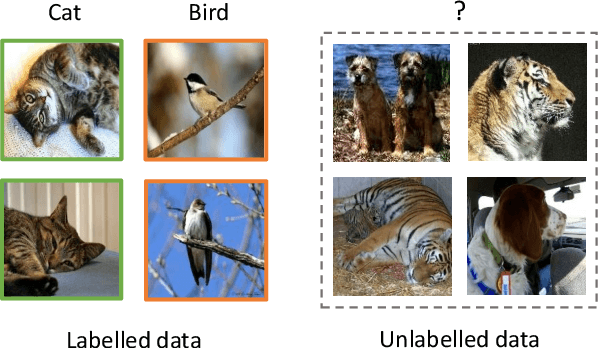
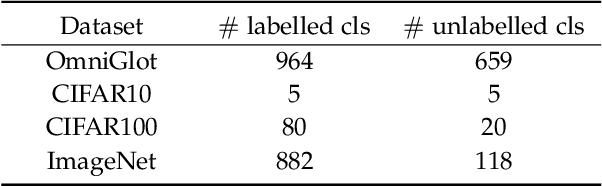
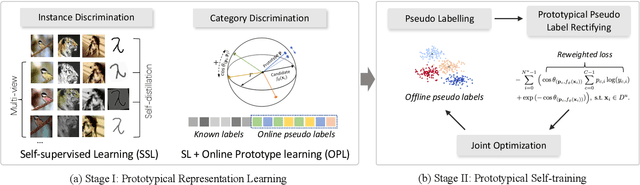
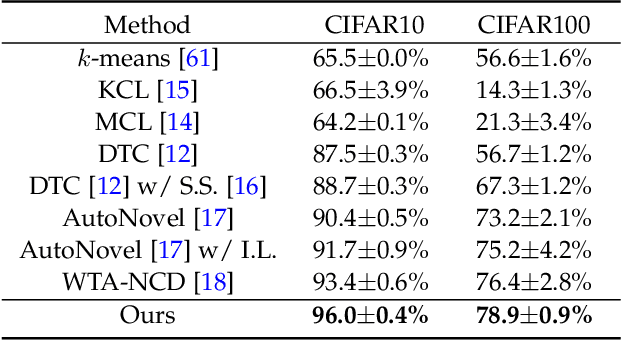
This paper tackles the problem of novel category discovery (NCD), which aims to discriminate unknown categories in large-scale image collections. The NCD task is challenging due to the closeness to the real-world scenarios, where we have only encountered some partial classes and images. Unlike other works on the NCD, we leverage the prototypes to emphasize the importance of category discrimination and alleviate the issue of missing annotations of novel classes. Concretely, we propose a novel adaptive prototype learning method consisting of two main stages: prototypical representation learning and prototypical self-training. In the first stage, we obtain a robust feature extractor, which could serve for all images with base and novel categories. This ability of instance and category discrimination of the feature extractor is boosted by self-supervised learning and adaptive prototypes. In the second stage, we utilize the prototypes again to rectify offline pseudo labels and train a final parametric classifier for category clustering. We conduct extensive experiments on four benchmark datasets and demonstrate the effectiveness and robustness of the proposed method with state-of-the-art performance.
Zero-shot object goal visual navigation
Jun 15, 2022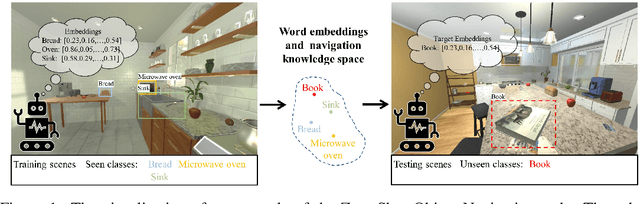
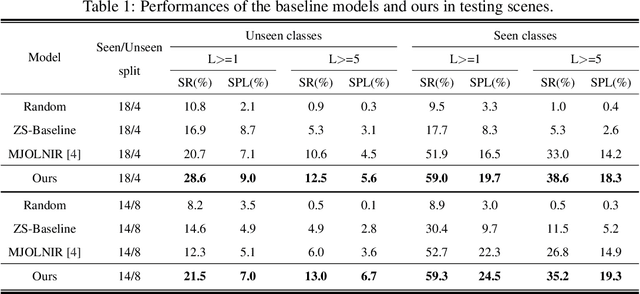
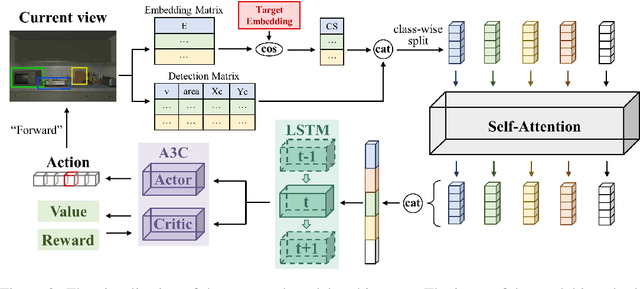
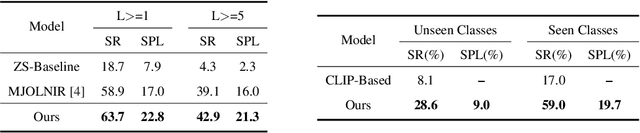
Object goal visual navigation is a challenging task that aims to guide a robot to find the target object only based on its visual observation, and the target is limited to the classes specified in the training stage. However, in real households, there may exist numerous object classes that the robot needs to deal with, and it is hard for all of these classes to be contained in the training stage. To address this challenge, we propose a zero-shot object navigation task by combining zero-shot learning with object goal visual navigation, which aims at guiding robots to find objects belonging to novel classes without any training samples. This task gives rise to the need to generalize the learned policy to novel classes, which is a less addressed issue of object navigation using deep reinforcement learning. To address this issue, we utilize "class-unrelated" data as input to alleviate the overfitting of the classes specified in the training stage. The class-unrelated input consists of detection results and cosine similarity of word embeddings, and does not contain any class-related visual features or knowledge graphs. Extensive experiments on the AI2-THOR platform show that our model outperforms the baseline models in both seen and unseen classes, which proves that our model is less class-sensitive and generalizes better. Our code is available at https://github.com/pioneer-innovation/Zero-Shot-Object-Navigation
Weakly Aligned Feature Fusion for Multimodal Object Detection
Apr 21, 2022
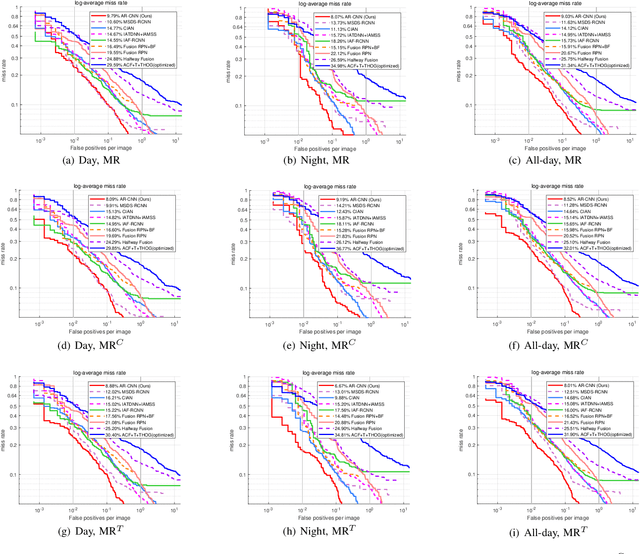


To achieve accurate and robust object detection in the real-world scenario, various forms of images are incorporated, such as color, thermal, and depth. However, multimodal data often suffer from the position shift problem, i.e., the image pair is not strictly aligned, making one object has different positions in different modalities. For the deep learning method, this problem makes it difficult to fuse multimodal features and puzzles the convolutional neural network (CNN) training. In this article, we propose a general multimodal detector named aligned region CNN (AR-CNN) to tackle the position shift problem. First, a region feature (RF) alignment module with adjacent similarity constraint is designed to consistently predict the position shift between two modalities and adaptively align the cross-modal RFs. Second, we propose a novel region of interest (RoI) jitter strategy to improve the robustness to unexpected shift patterns. Third, we present a new multimodal feature fusion method that selects the more reliable feature and suppresses the less useful one via feature reweighting. In addition, by locating bounding boxes in both modalities and building their relationships, we provide novel multimodal labeling named KAIST-Paired. Extensive experiments on 2-D and 3-D object detection, RGB-T, and RGB-D datasets demonstrate the effectiveness and robustness of our method.
Learning with Smooth Hinge Losses
Mar 15, 2021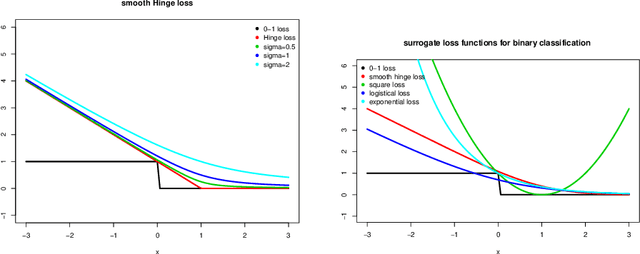
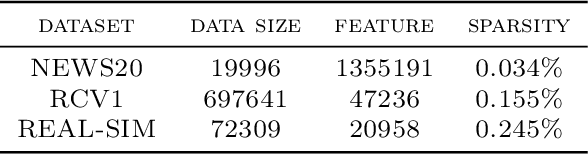
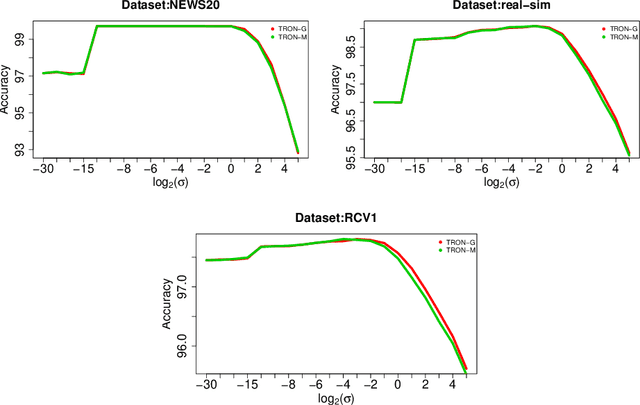

Due to the non-smoothness of the Hinge loss in SVM, it is difficult to obtain a faster convergence rate with modern optimization algorithms. In this paper, we introduce two smooth Hinge losses $\psi_G(\alpha;\sigma)$ and $\psi_M(\alpha;\sigma)$ which are infinitely differentiable and converge to the Hinge loss uniformly in $\alpha$ as $\sigma$ tends to $0$. By replacing the Hinge loss with these two smooth Hinge losses, we obtain two smooth support vector machines(SSVMs), respectively. Solving the SSVMs with the Trust Region Newton method (TRON) leads to two quadratically convergent algorithms. Experiments in text classification tasks show that the proposed SSVMs are effective in real-world applications. We also introduce a general smooth convex loss function to unify several commonly-used convex loss functions in machine learning. The general framework provides smooth approximation functions to non-smooth convex loss functions, which can be used to obtain smooth models that can be solved with faster convergent optimization algorithms.
A Minimax Probability Machine for Non-Decomposable Performance Measures
Mar 15, 2021

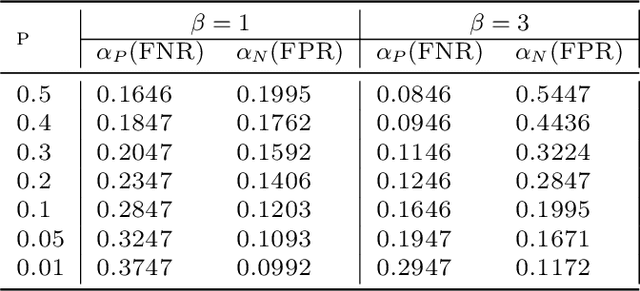
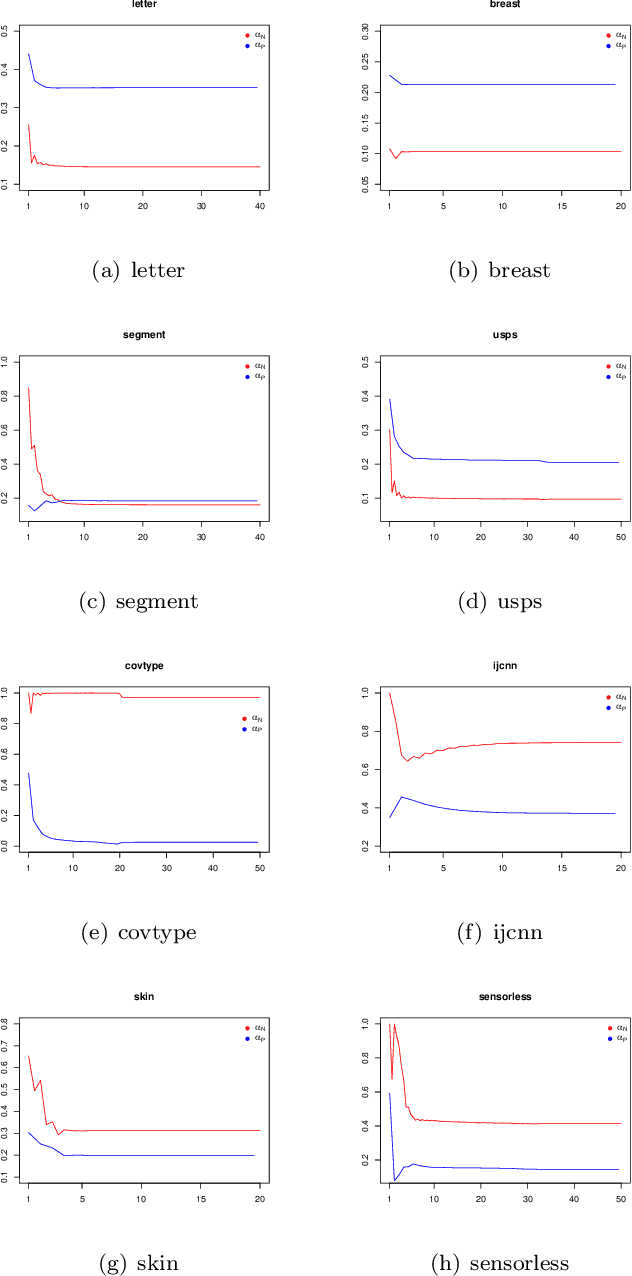
Imbalanced classification tasks are widespread in many real-world applications. For such classification tasks, in comparison with the accuracy rate, it is usually much more appropriate to use non-decomposable performance measures such as the Area Under the receiver operating characteristic Curve (AUC) and the $F_\beta$ measure as the classification criterion since the label class is imbalanced. On the other hand, the minimax probability machine is a popular method for binary classification problems and aims at learning a linear classifier by maximizing the accuracy rate, which makes it unsuitable to deal with imbalanced classification tasks. The purpose of this paper is to develop a new minimax probability machine for the $F_\beta$ measure, called MPMF, which can be used to deal with imbalanced classification tasks. A brief discussion is also given on how to extend the MPMF model for several other non-decomposable performance measures listed in the paper. To solve the MPMF model effectively, we derive its equivalent form which can then be solved by an alternating descent method to learn a linear classifier. Further, the kernel trick is employed to derive a nonlinear MPMF model to learn a nonlinear classifier. Several experiments on real-world benchmark datasets demonstrate the effectiveness of our new model.