 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReVEAL: GNN-Guided Reverse Engineering for Formal Verification of Optimized Multipliers
Dec 24, 2025We present ReVEAL, a graph-learning-based method for reverse engineering of multiplier architectures to improve algebraic circuit verification techniques. Our framework leverages structural graph features and learning-driven inference to identify architecture patterns at scale, enabling robust handling of large optimized multipliers. We demonstrate applicability across diverse multiplier benchmarks and show improvements in scalability and accuracy compared to traditional rule-based approaches. The method integrates smoothly with existing verification flows and supports downstream algebraic proof strategies.
Partition-based Nonrigid Registration for 3D Face Model
Jan 05, 2024This paper presents a partition-based surface registration for 3D morphable model(3DMM). In the 3DMM, it often requires to warp a handcrafted template model into different captured models. The proposed method first utilizes the landmarks to partition the template model then scale each part and finally smooth the boundaries. This method is especially effective when the disparity between the template model and the target model is huge. The experiment result shows the method perform well than the traditional warp method and robust to the local minima.
A Food Package Recognition and Sorting System Based on Structured Light and Deep Learning
Sep 07, 2023



Vision algorithm-based robotic arm grasping system is one of the robotic arm systems that can be applied to a wide range of scenarios. It uses algorithms to automatically identify the location of the target and guide the robotic arm to grasp it, which has more flexible features than the teachable robotic arm grasping system. However, for some food packages, their transparent packages or reflective materials bring challenges to the recognition of vision algorithms, and traditional vision algorithms cannot achieve high accuracy for these packages. In addition, in the process of robotic arm grasping, the positioning on the z-axis height still requires manual setting of parameters, which may cause errors. Based on the above two problems, we designed a sorting system for food packaging using deep learning algorithms and structured light 3D reconstruction technology. Using a pre-trained MASK R-CNN model to recognize the class of the object in the image and get its 2D coordinates, then using structured light 3D reconstruction technique to calculate its 3D coordinates, and finally after the coordinate system conversion to guide the robotic arm for grasping. After testing, it is shown that the method can fully automate the recognition and grasping of different kinds of food packages with high accuracy. Using this method, it can help food manufacturers to reduce production costs and improve production efficiency.
Benchmarks for Industrial Inspection Based on Structured Light
Jul 02, 2022
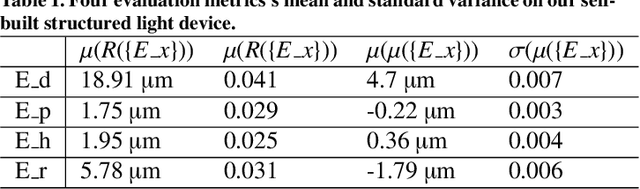
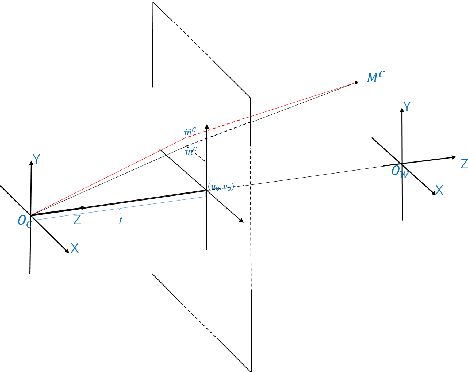
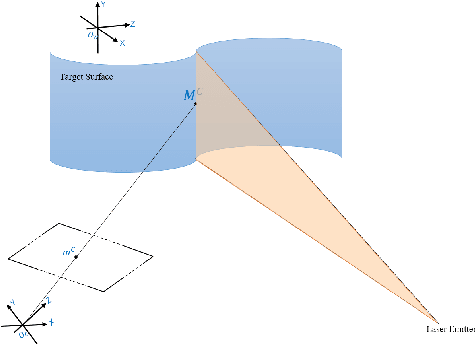
Robustness and accuracy are two critical metrics for industrial inspection. In this paper, we propose benchmarks that can evaluate the structured light method's performance. Our evaluation metric was learning from a lot of inspection tasks from the factories. The metric we proposed consists of four detailed criteria such as flatness, length, height and sphericity. Then we can judge whether the structured light method/device can be applied to a specified inspection task by our evaluation metric quickly. A structured light device built for TypeC pin needles inspection performance is evaluated via our metrics in the final experimental section.
Weakly Aligned Feature Fusion for Multimodal Object Detection
Apr 21, 2022
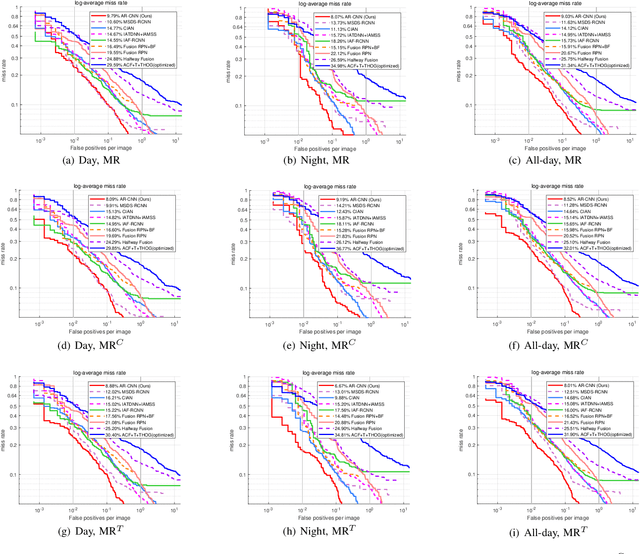


To achieve accurate and robust object detection in the real-world scenario, various forms of images are incorporated, such as color, thermal, and depth. However, multimodal data often suffer from the position shift problem, i.e., the image pair is not strictly aligned, making one object has different positions in different modalities. For the deep learning method, this problem makes it difficult to fuse multimodal features and puzzles the convolutional neural network (CNN) training. In this article, we propose a general multimodal detector named aligned region CNN (AR-CNN) to tackle the position shift problem. First, a region feature (RF) alignment module with adjacent similarity constraint is designed to consistently predict the position shift between two modalities and adaptively align the cross-modal RFs. Second, we propose a novel region of interest (RoI) jitter strategy to improve the robustness to unexpected shift patterns. Third, we present a new multimodal feature fusion method that selects the more reliable feature and suppresses the less useful one via feature reweighting. In addition, by locating bounding boxes in both modalities and building their relationships, we provide novel multimodal labeling named KAIST-Paired. Extensive experiments on 2-D and 3-D object detection, RGB-T, and RGB-D datasets demonstrate the effectiveness and robustness of our method.
Train Your Data Processor: Distribution-Aware and Error-Compensation Coordinate Decoding for Human Pose Estimation
Jul 17, 2020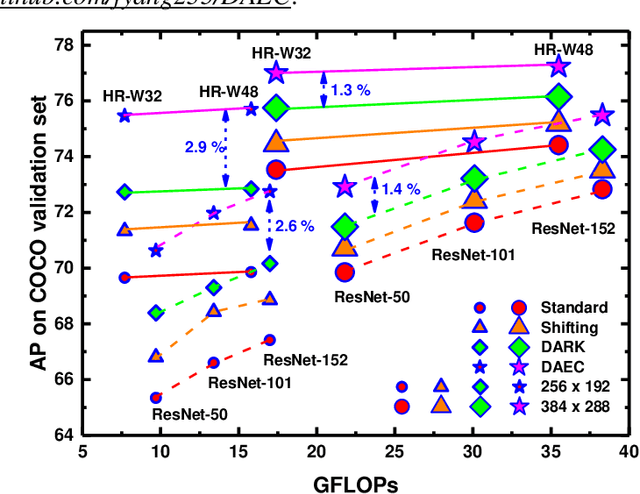
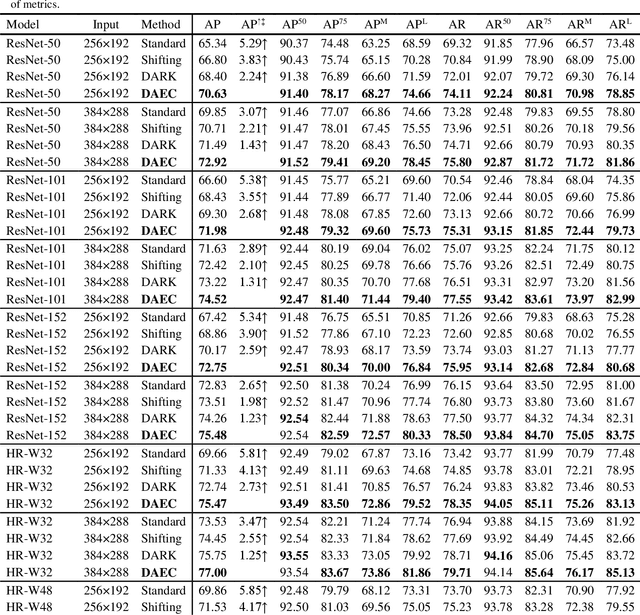
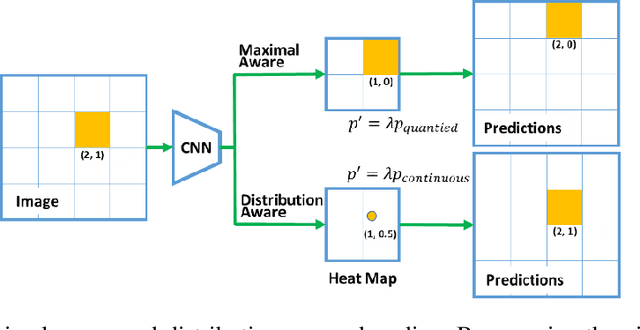
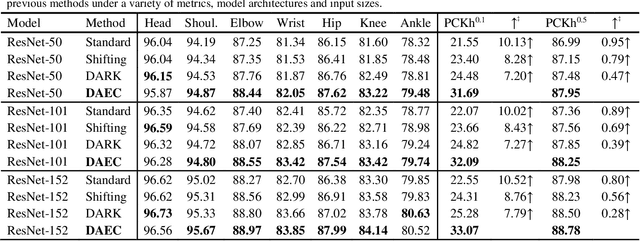
Recently, the leading performance of human pose estimation is dominated by heatmap based methods. While being a fundamental component of heatmap processing, heatmap decoding (i.e. transforming heatmaps to coordinates) receives only limited investigations, to our best knowledge. This work fills the gap by studying the heatmap decoding processing with a particular focus on the errors introduced throughout the prediction process. We found that the errors of heatmap based methods are surprisingly significant, which nevertheless was universally ignored before. In view of the discovered importance, we further reveal the intrinsic limitations of the previous widely used heatmap decoding methods and thereout propose a Distribution-Aware and Error-Compensation Coordinate Decoding (DAEC). Serving as a model-agnostic plug-in, DAEC learns its decoding strategy from training data and remarkably improves the performance of a variety of state-of-the-art human pose estimation models with negligible extra computation. Specifically, equipped with DAEC, the SimpleBaseline-ResNet152-256x192 and HRNet-W48-256x192 are significantly improved by 2.6 AP and 2.9 AP achieving 72.6 AP and 75.7 AP on COCO, respectively. Moreover, the HRNet-W32-256x256 and ResNet-152-256x256 frameworks enjoy even more dramatic promotions of 8.4% and 7.8% on MPII with PCKh0.1 metric. Extensive experiments performed on these two common benchmarks, demonstrates that DAEC exceeds its competitors by considerable margins, backing up the rationality and generality of our novel heatmap decoding idea. The project is available at https://github.com/fyang235/DAEC.