 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrain Your Data Processor: Distribution-Aware and Error-Compensation Coordinate Decoding for Human Pose Estimation
Jul 17, 2020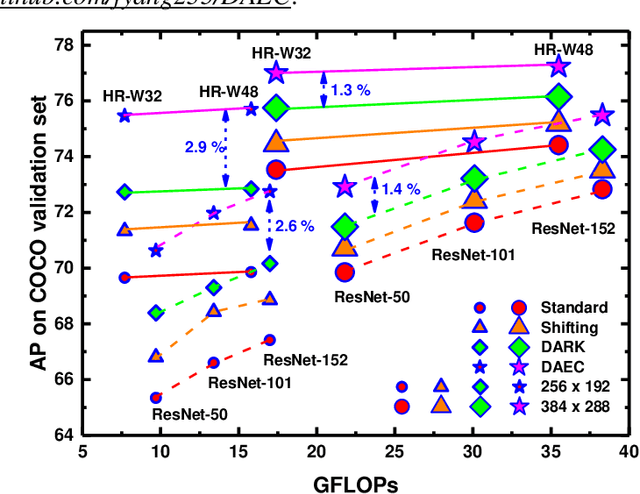
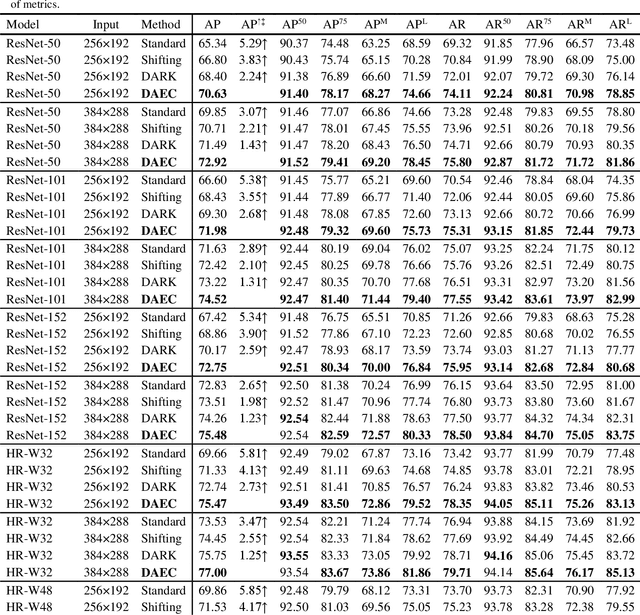
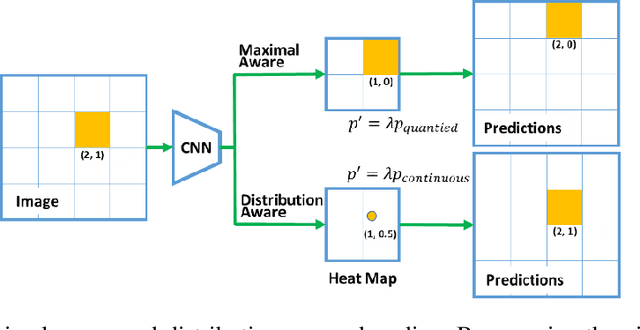
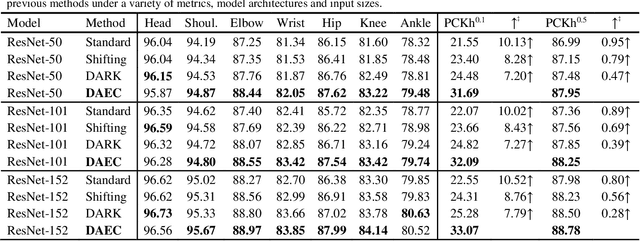
Recently, the leading performance of human pose estimation is dominated by heatmap based methods. While being a fundamental component of heatmap processing, heatmap decoding (i.e. transforming heatmaps to coordinates) receives only limited investigations, to our best knowledge. This work fills the gap by studying the heatmap decoding processing with a particular focus on the errors introduced throughout the prediction process. We found that the errors of heatmap based methods are surprisingly significant, which nevertheless was universally ignored before. In view of the discovered importance, we further reveal the intrinsic limitations of the previous widely used heatmap decoding methods and thereout propose a Distribution-Aware and Error-Compensation Coordinate Decoding (DAEC). Serving as a model-agnostic plug-in, DAEC learns its decoding strategy from training data and remarkably improves the performance of a variety of state-of-the-art human pose estimation models with negligible extra computation. Specifically, equipped with DAEC, the SimpleBaseline-ResNet152-256x192 and HRNet-W48-256x192 are significantly improved by 2.6 AP and 2.9 AP achieving 72.6 AP and 75.7 AP on COCO, respectively. Moreover, the HRNet-W32-256x256 and ResNet-152-256x256 frameworks enjoy even more dramatic promotions of 8.4% and 7.8% on MPII with PCKh0.1 metric. Extensive experiments performed on these two common benchmarks, demonstrates that DAEC exceeds its competitors by considerable margins, backing up the rationality and generality of our novel heatmap decoding idea. The project is available at https://github.com/fyang235/DAEC.
Globally Optimal Segmentation of Mutually Interacting Surfaces using Deep Learning
Jul 15, 2020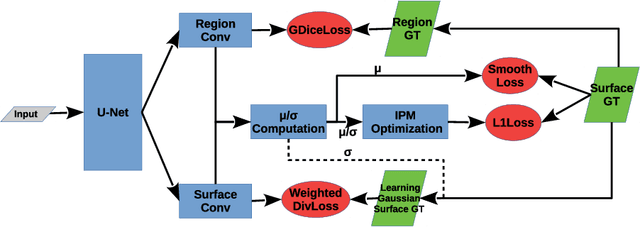
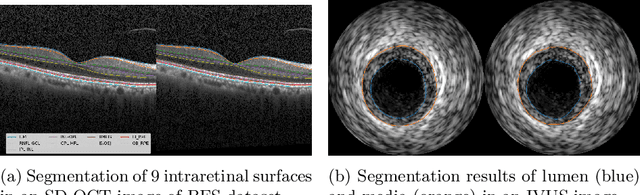
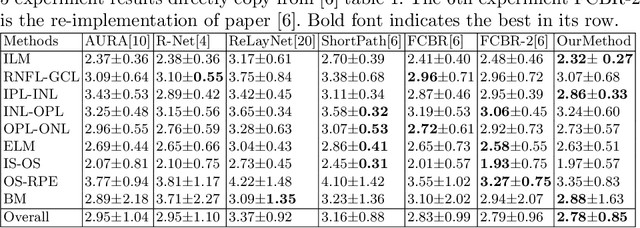

Segmentation of multiple surfaces in medical images is a challenging problem, further complicated by the frequent presence of weak boundary and mutual influence between adjacent objects. The traditional graph-based optimal surface segmentation method has proven its effectiveness with its ability of capturing various surface priors in a uniform graph model. However, its efficacy heavily relies on handcrafted features that are used to define the surface cost for the "goodness" of a surface. Recently, deep learning (DL) is emerging as powerful tools for medical image segmentation thanks to its superior feature learning capability. Unfortunately, due to the scarcity of training data in medical imaging, it is nontrivial for DL networks to implicitly learn the global structure of the target surfaces, including surface interactions. In this work, we propose to parameterize the surface cost functions in the graph model and leverage DL to learn those parameters. The multiple optimal surfaces are then simultaneously detected by minimizing the total surface cost while explicitly enforcing the mutual surface interaction constraints. The optimization problem is solved by the primal-dual Internal Point Method, which can be implemented by a layer of neural networks, enabling efficient end-to-end training of the whole network. Experiments on Spectral Domain Optical Coherence Tomography (SD-OCT) retinal layer segmentation and Intravascular Ultrasound (IVUS) vessel wall segmentation demonstrated very promising results. All source code is public to facilitate further research at this direction.