 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobally Optimal Segmentation of Mutually Interacting Surfaces using Deep Learning
Jul 15, 2020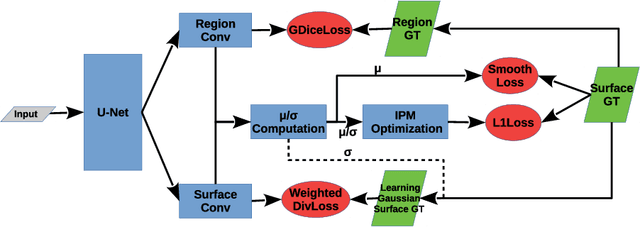
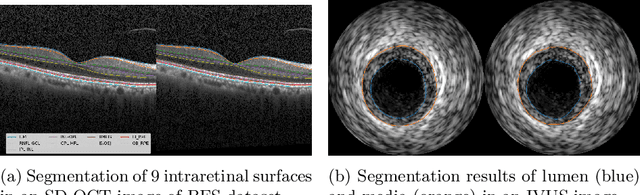
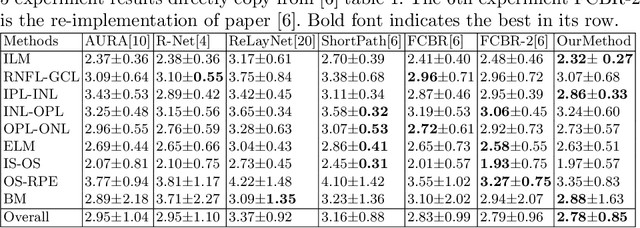

Segmentation of multiple surfaces in medical images is a challenging problem, further complicated by the frequent presence of weak boundary and mutual influence between adjacent objects. The traditional graph-based optimal surface segmentation method has proven its effectiveness with its ability of capturing various surface priors in a uniform graph model. However, its efficacy heavily relies on handcrafted features that are used to define the surface cost for the "goodness" of a surface. Recently, deep learning (DL) is emerging as powerful tools for medical image segmentation thanks to its superior feature learning capability. Unfortunately, due to the scarcity of training data in medical imaging, it is nontrivial for DL networks to implicitly learn the global structure of the target surfaces, including surface interactions. In this work, we propose to parameterize the surface cost functions in the graph model and leverage DL to learn those parameters. The multiple optimal surfaces are then simultaneously detected by minimizing the total surface cost while explicitly enforcing the mutual surface interaction constraints. The optimization problem is solved by the primal-dual Internal Point Method, which can be implemented by a layer of neural networks, enabling efficient end-to-end training of the whole network. Experiments on Spectral Domain Optical Coherence Tomography (SD-OCT) retinal layer segmentation and Intravascular Ultrasound (IVUS) vessel wall segmentation demonstrated very promising results. All source code is public to facilitate further research at this direction.
Globally Optimal Surface Segmentation using Deep Learning with Learnable Smoothness Priors
Jul 02, 2020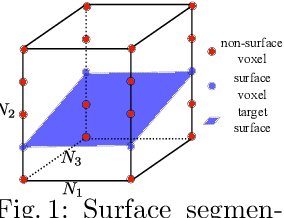



Automated surface segmentation is important and challenging in many medical image analysis applications. Recent deep learning based methods have been developed for various object segmentation tasks. Most of them are a classification based approach, e.g. U-net, which predicts the probability of being target object or background for each voxel. One problem of those methods is lacking of topology guarantee for segmented objects, and usually post processing is needed to infer the boundary surface of the object. In this paper, a novel model based on convolutional neural network (CNN) followed by a learnable surface smoothing block is proposed to tackle the surface segmentation problem with end-to-end training. To the best of our knowledge, this is the first study to learn smoothness priors end-to-end with CNN for direct surface segmentation with global optimality. Experiments carried out on Spectral Domain Optical Coherence Tomography (SD-OCT) retinal layer segmentation and Intravascular Ultrasound (IVUS) vessel wall segmentation demonstrated very promising results.
Unsupervised anomaly localization using VAE and beta-VAE
May 19, 2020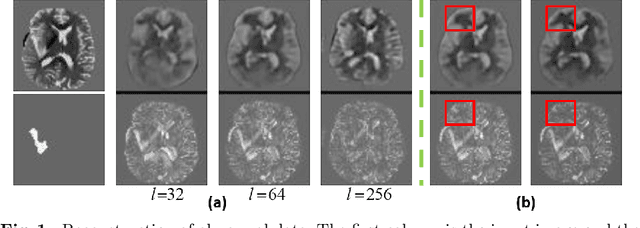
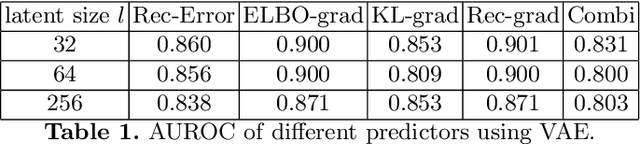
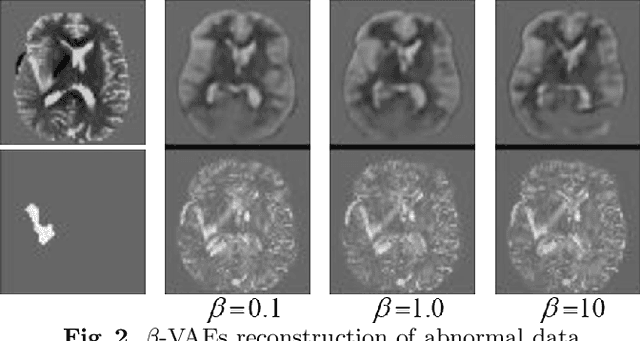
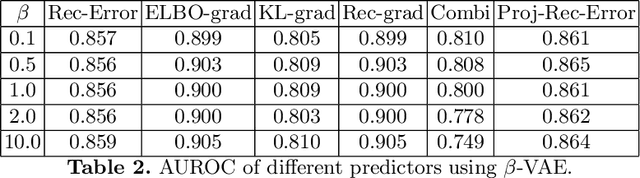
Variational Auto-Encoders (VAEs) have shown great potential in the unsupervised learning of data distributions. An VAE trained on normal images is expected to only be able to reconstruct normal images, allowing the localization of anomalous pixels in an image via manipulating information within the VAE ELBO loss. The ELBO consists of KL divergence loss (image-wise) and reconstruction loss (pixel-wise). It is natural and straightforward to use the later as the predictor. However, usually local anomaly added to a normal image can deteriorate the whole reconstructed image, causing segmentation using only naive pixel errors not accurate. Energy based projection was proposed to increase the reconstruction accuracy of normal regions/pixels, which achieved the state-of-the-art localization accuracy on simple natural images. Another possible predictors are ELBO and its components gradients with respect to each pixels. Previous work claimed that KL gradient is a robust predictor. In this paper, we argue that the energy based projection in medical imaging is not as useful as on natural images. Moreover, we observe that the robustness of KL gradient predictor totally depends on the setting of the VAE and dataset. We also explored the effect of the weight of KL loss within beta-VAE and predictor ensemble in anomaly localization.
3-D Surface Segmentation Meets Conditional Random Fields
Jun 11, 2019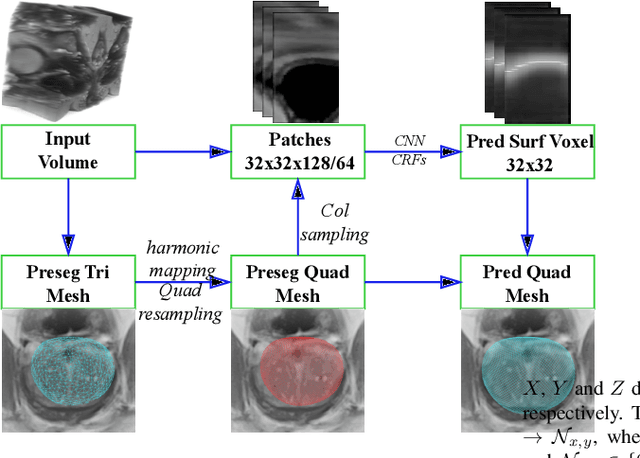
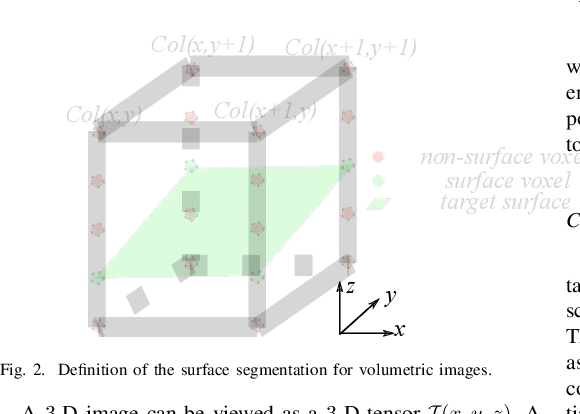
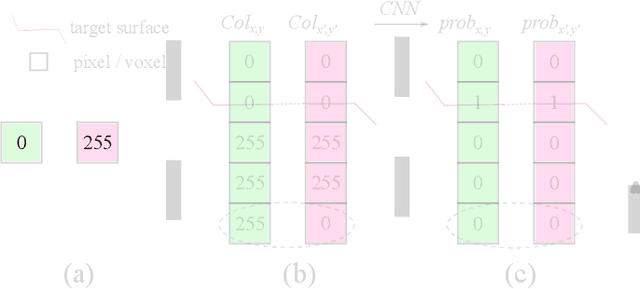
Automated surface segmentation is important and challenging in many medical image analysis applications. Recent deep learning based methods have been developed for various object segmentation tasks. Most of them are a classification based approach, e.g. U-net, which predicts the probability of being target object or background for each voxel. One problem of those methods is lacking of topology guarantee for segmented objects, and usually post processing is needed to infer the boundary surface of the object. In this paper, a novel model based on 3-D convolutional neural network (CNN) and Conditional Random Fields (CRFs) is proposed to tackle the surface segmentation problem with end-to-end training. To the best of our knowledge, this is the first study to apply a 3-D neural network with a CRFs model for direct surface segmentation. Experiments carried out on NCI-ISBI 2013 MR prostate dataset and Medical Segmentation Decathlon Spleen dataset demonstrated very promising segmentation results.
Trust but Verify: An Information-Theoretic Explanation for the Adversarial Fragility of Machine Learning Systems, and a General Defense against Adversarial Attacks
May 25, 2019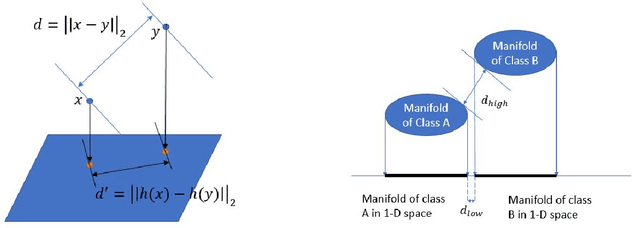
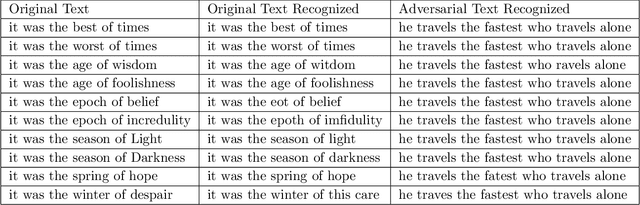
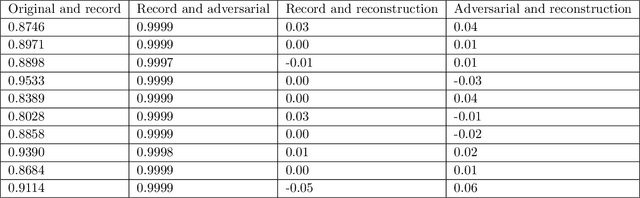
Deep-learning based classification algorithms have been shown to be susceptible to adversarial attacks: minor changes to the input of classifiers can dramatically change their outputs, while being imperceptible to humans. In this paper, we present a simple hypothesis about a feature compression property of artificial intelligence (AI) classifiers and present theoretical arguments to show that this hypothesis successfully accounts for the observed fragility of AI classifiers to small adversarial perturbations. Drawing on ideas from information and coding theory, we propose a general class of defenses for detecting classifier errors caused by abnormally small input perturbations. We further show theoretical guarantees for the performance of this detection method. We present experimental results with (a) a voice recognition system, and (b) a digit recognition system using the MNIST database, to demonstrate the effectiveness of the proposed defense methods. The ideas in this paper are motivated by a simple analogy between AI classifiers and the standard Shannon model of a communication system.
Robust Image Segmentation Quality Assessment without Ground Truth
Mar 20, 2019

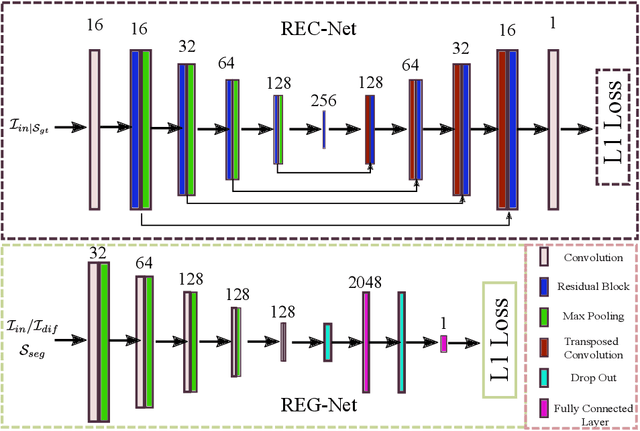
Deep learning based image segmentation methods have achieved great success, even having human-level accuracy in some applications. However, due to the black box nature of deep learning, the best method may fail in some situations. Thus predicting segmentation quality without ground truth would be very crucial especially in clinical practice. Recently, people proposed to train neural networks to estimate the quality score by regression. Although it can achieve promising prediction accuracy, the network suffers robustness problem, e.g. it is vulnerable to adversarial attacks. In this paper, we propose to alleviate this problem by utilizing the difference between the input image and the reconstructed image, which is reconstructed from the segmentation to be assessed. The deep learning based reconstruction network (REC-Net) is trained with the input image masked by the ground truth segmentation against the original input image as the target. The rationale behind is that the trained REC-Net can best reconstruct the input image masked by accurate segmentation. The quality score regression network (REG-Net) is then trained with difference images and the corresponding segmentations as input. In this way, the regression network may have lower chance to overfit to the undesired image features from the original input image, and thus is more robust. Results on ACDC17 dataset demonstrated our method is promising.