 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrust, but Verify: Robust Image Segmentation using Deep Learning
Oct 29, 2023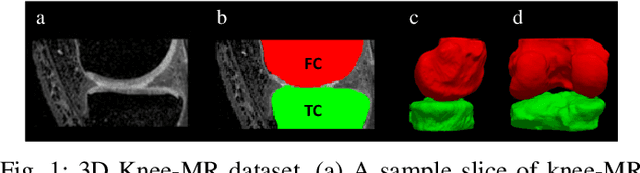
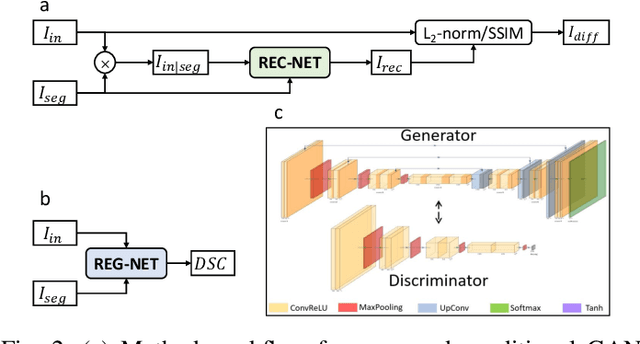
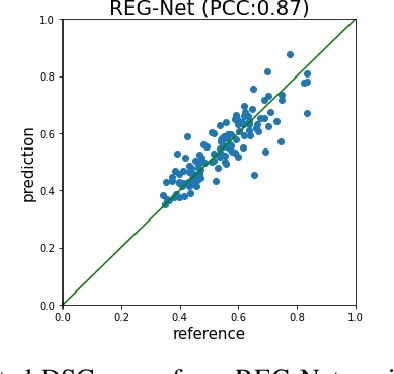

We describe a method for verifying the output of a deep neural network for medical image segmentation that is robust to several classes of random as well as worst-case perturbations i.e. adversarial attacks. This method is based on a general approach recently developed by the authors called "Trust, but Verify" wherein an auxiliary verification network produces predictions about certain masked features in the input image using the segmentation as an input. A well-designed auxiliary network will produce high-quality predictions when the input segmentations are accurate, but will produce low-quality predictions when the segmentations are incorrect. Checking the predictions of such a network with the original image allows us to detect bad segmentations. However, to ensure the verification method is truly robust, we need a method for checking the quality of the predictions that does not itself rely on a black-box neural network. Indeed, we show that previous methods for segmentation evaluation that do use deep neural regression networks are vulnerable to false negatives i.e. can inaccurately label bad segmentations as good. We describe the design of a verification network that avoids such vulnerability and present results to demonstrate its robustness compared to previous methods.
Trust but Verify: An Information-Theoretic Explanation for the Adversarial Fragility of Machine Learning Systems, and a General Defense against Adversarial Attacks
May 25, 2019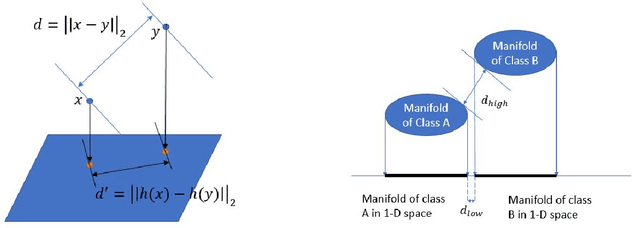
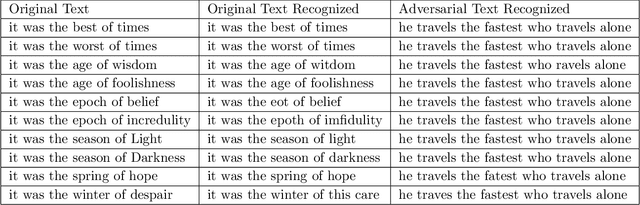
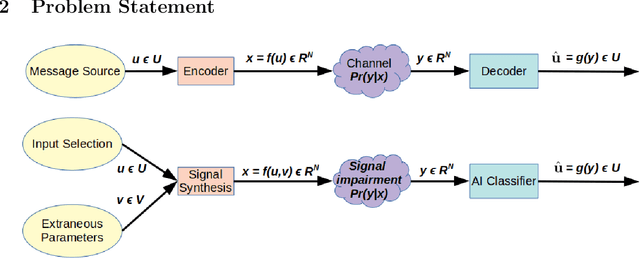
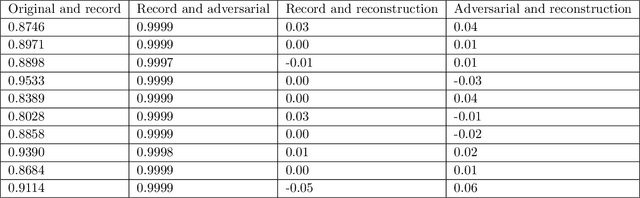
Deep-learning based classification algorithms have been shown to be susceptible to adversarial attacks: minor changes to the input of classifiers can dramatically change their outputs, while being imperceptible to humans. In this paper, we present a simple hypothesis about a feature compression property of artificial intelligence (AI) classifiers and present theoretical arguments to show that this hypothesis successfully accounts for the observed fragility of AI classifiers to small adversarial perturbations. Drawing on ideas from information and coding theory, we propose a general class of defenses for detecting classifier errors caused by abnormally small input perturbations. We further show theoretical guarantees for the performance of this detection method. We present experimental results with (a) a voice recognition system, and (b) a digit recognition system using the MNIST database, to demonstrate the effectiveness of the proposed defense methods. The ideas in this paper are motivated by a simple analogy between AI classifiers and the standard Shannon model of a communication system.
Two step recovery of jointly sparse and low-rank matrices: theoretical guarantees
Jun 02, 2015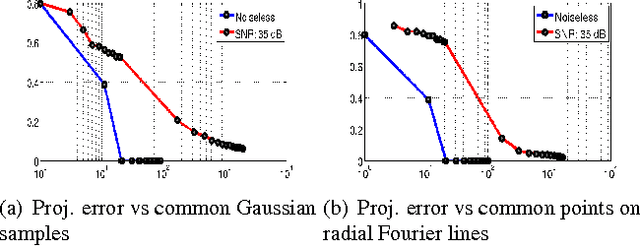
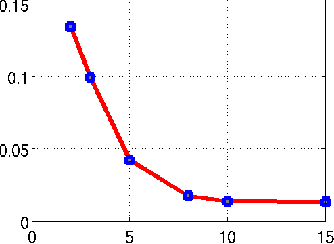
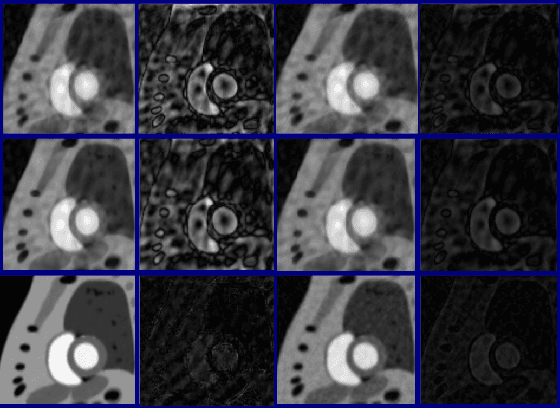
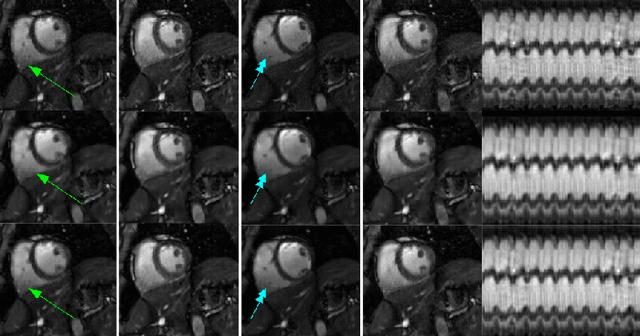
We introduce a two step algorithm with theoretical guarantees to recover a jointly sparse and low-rank matrix from undersampled measurements of its columns. The algorithm first estimates the row subspace of the matrix using a set of common measurements of the columns. In the second step, the subspace aware recovery of the matrix is solved using a simple least square algorithm. The results are verified in the context of recovering CINE data from undersampled measurements; we obtain good recovery when the sampling conditions are satisfied.
Subspace based low rank and joint sparse matrix recovery
Jun 02, 2015
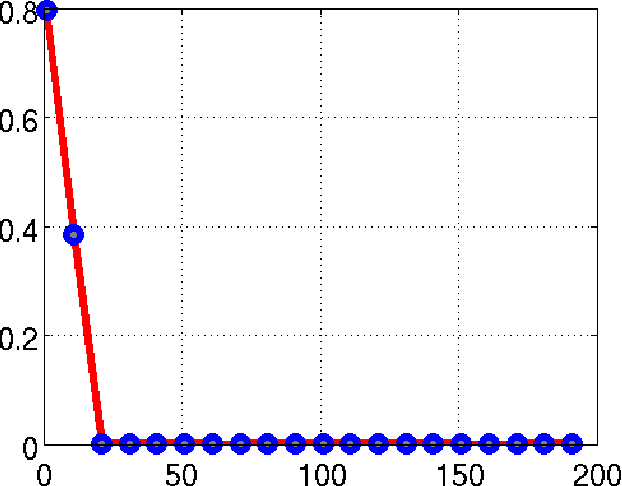
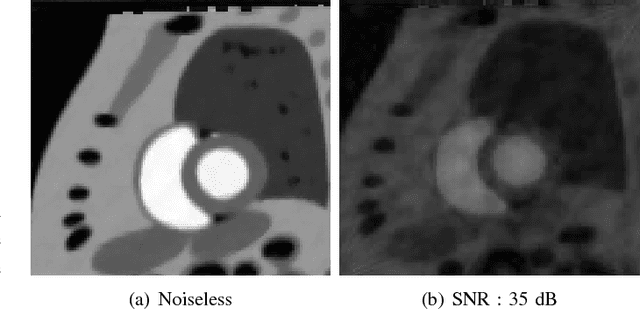
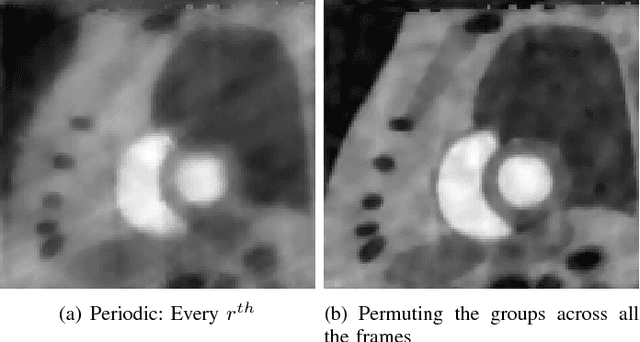
We consider the recovery of a low rank and jointly sparse matrix from under sampled measurements of its columns. This problem is highly relevant in the recovery of dynamic MRI data with high spatio-temporal resolution, where each column of the matrix corresponds to a frame in the image time series; the matrix is highly low-rank since the frames are highly correlated. Similarly the non-zero locations of the matrix in appropriate transform/frame domains (e.g. wavelet, gradient) are roughly the same in different frame. The superset of the support can be safely assumed to be jointly sparse. Unlike the classical multiple measurement vector (MMV) setup that measures all the snapshots using the same matrix, we consider each snapshot to be measured using a different measurement matrix. We show that this approach reduces the total number of measurements, especially when the rank of the matrix is much smaller than than its sparsity. Our experiments in the context of dynamic imaging shows that this approach is very useful in realizing free breathing cardiac MRI.