 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrust, but Verify: Robust Image Segmentation using Deep Learning
Paper and Code
Oct 29, 2023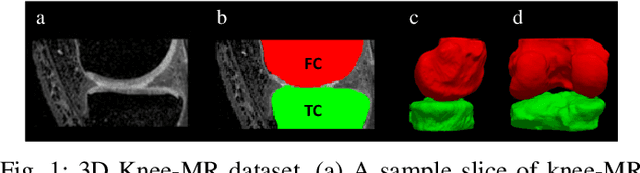
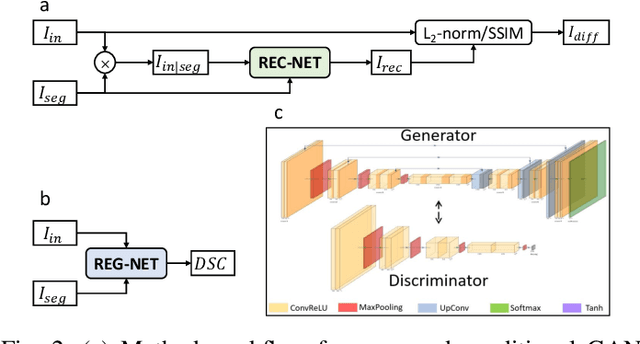
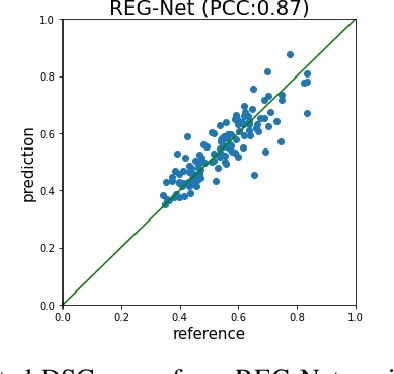

We describe a method for verifying the output of a deep neural network for medical image segmentation that is robust to several classes of random as well as worst-case perturbations i.e. adversarial attacks. This method is based on a general approach recently developed by the authors called "Trust, but Verify" wherein an auxiliary verification network produces predictions about certain masked features in the input image using the segmentation as an input. A well-designed auxiliary network will produce high-quality predictions when the input segmentations are accurate, but will produce low-quality predictions when the segmentations are incorrect. Checking the predictions of such a network with the original image allows us to detect bad segmentations. However, to ensure the verification method is truly robust, we need a method for checking the quality of the predictions that does not itself rely on a black-box neural network. Indeed, we show that previous methods for segmentation evaluation that do use deep neural regression networks are vulnerable to false negatives i.e. can inaccurately label bad segmentations as good. We describe the design of a verification network that avoids such vulnerability and present results to demonstrate its robustness compared to previous methods.