 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking the Reference-based Distinctive Image Captioning
Jul 22, 2022
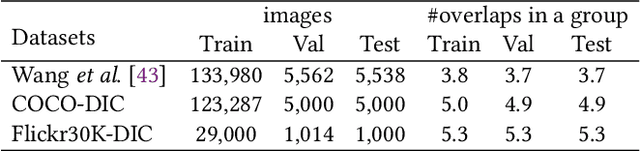
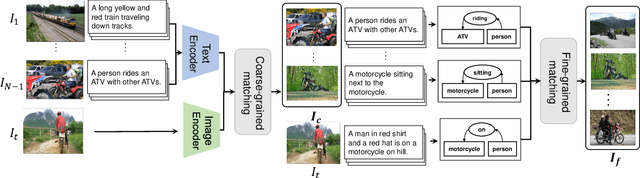
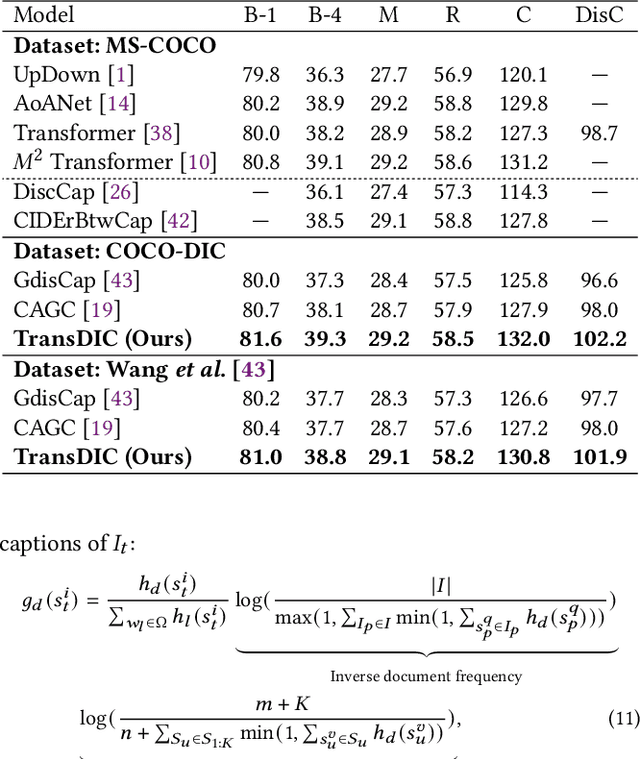
Distinctive Image Captioning (DIC) -- generating distinctive captions that describe the unique details of a target image -- has received considerable attention over the last few years. A recent DIC work proposes to generate distinctive captions by comparing the target image with a set of semantic-similar reference images, i.e., reference-based DIC (Ref-DIC). It aims to make the generated captions can tell apart the target and reference images. Unfortunately, reference images used by existing Ref-DIC works are easy to distinguish: these reference images only resemble the target image at scene-level and have few common objects, such that a Ref-DIC model can trivially generate distinctive captions even without considering the reference images. To ensure Ref-DIC models really perceive the unique objects (or attributes) in target images, we first propose two new Ref-DIC benchmarks. Specifically, we design a two-stage matching mechanism, which strictly controls the similarity between the target and reference images at object-/attribute- level (vs. scene-level). Secondly, to generate distinctive captions, we develop a strong Transformer-based Ref-DIC baseline, dubbed as TransDIC. It not only extracts visual features from the target image, but also encodes the differences between objects in the target and reference images. Finally, for more trustworthy benchmarking, we propose a new evaluation metric named DisCIDEr for Ref-DIC, which evaluates both the accuracy and distinctiveness of the generated captions. Experimental results demonstrate that our TransDIC can generate distinctive captions. Besides, it outperforms several state-of-the-art models on the two new benchmarks over different metrics.
Human-like Controllable Image Captioning with Verb-specific Semantic Roles
Mar 22, 2021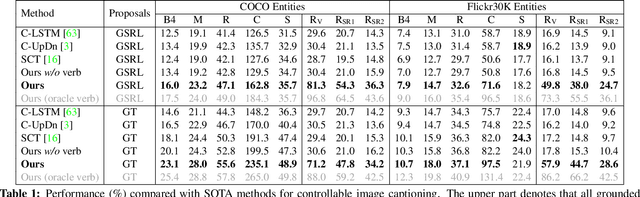

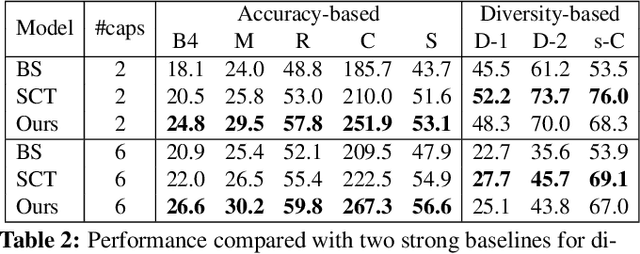
Controllable Image Captioning (CIC) -- generating image descriptions following designated control signals -- has received unprecedented attention over the last few years. To emulate the human ability in controlling caption generation, current CIC studies focus exclusively on control signals concerning objective properties, such as contents of interest or descriptive patterns. However, we argue that almost all existing objective control signals have overlooked two indispensable characteristics of an ideal control signal: 1) Event-compatible: all visual contents referred to in a single sentence should be compatible with the described activity. 2) Sample-suitable: the control signals should be suitable for a specific image sample. To this end, we propose a new control signal for CIC: Verb-specific Semantic Roles (VSR). VSR consists of a verb and some semantic roles, which represents a targeted activity and the roles of entities involved in this activity. Given a designated VSR, we first train a grounded semantic role labeling (GSRL) model to identify and ground all entities for each role. Then, we propose a semantic structure planner (SSP) to learn human-like descriptive semantic structures. Lastly, we use a role-shift captioning model to generate the captions. Extensive experiments and ablations demonstrate that our framework can achieve better controllability than several strong baselines on two challenging CIC benchmarks. Besides, we can generate multi-level diverse captions easily. The code is available at: https://github.com/mad-red/VSR-guided-CIC.
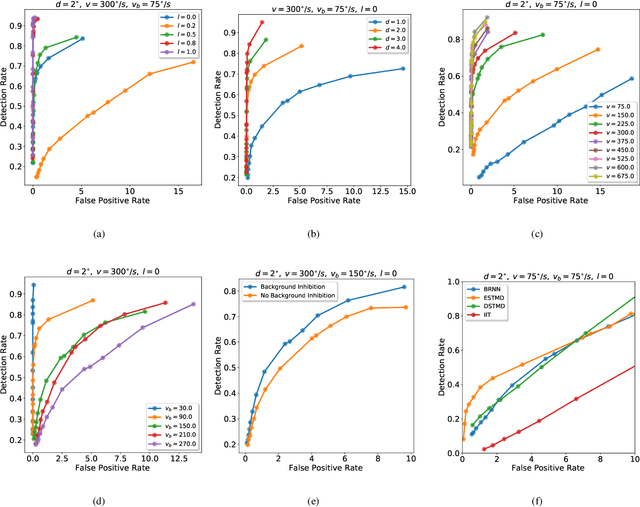
A Bioinspired Approach-Sensitive Neural Network for Collision Detection in Cluttered and Dynamic Backgrounds
Mar 01, 2021
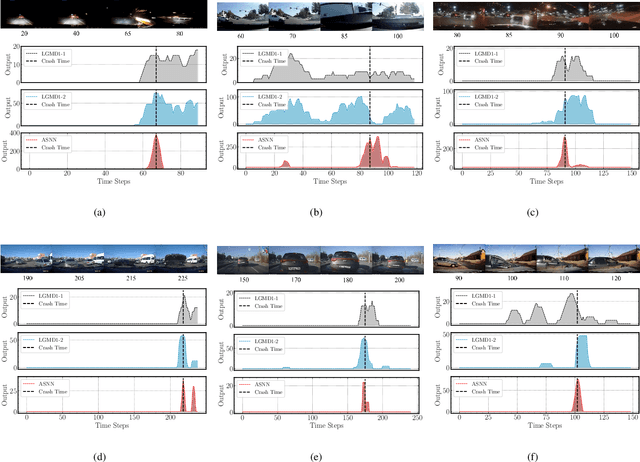
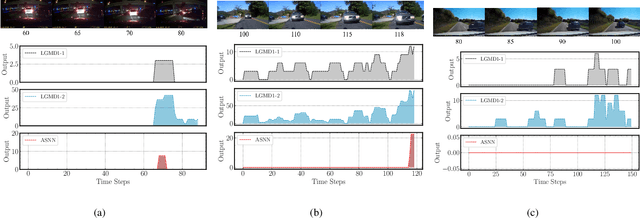

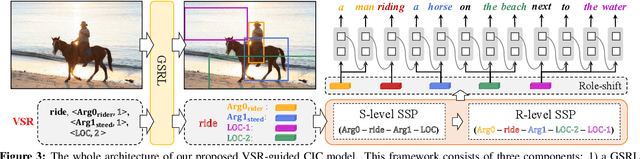
Rapid, accurate and robust detection of looming objects in cluttered moving backgrounds is a significant and challenging problem for robotic visual systems to perform collision detection and avoidance tasks. Inspired by the neural circuit of elementary motion vision in the mammalian retina, this paper proposes a bioinspired approach-sensitive neural network (ASNN) that contains three main contributions. Firstly, a direction-selective visual processing module is built based on the spatiotemporal energy framework, which can estimate motion direction accurately via only two mutually perpendicular spatiotemporal filtering channels. Secondly, a novel approach-sensitive neural network is modeled as a push-pull structure formed by ON and OFF pathways, which responds strongly to approaching motion while insensitivity to lateral motion. Finally, a method of directionally selective inhibition is introduced, which is able to suppress the translational backgrounds effectively. Extensive synthetic and real robotic experiments show that the proposed model is able to not only detect collision accurately and robustly in cluttered and dynamic backgrounds but also extract more collision information like position and direction, for guiding rapid decision making.
A Bioinspired Retinal Neural Network for Accurately Extracting Small-Target Motion Information in Cluttered Backgrounds
Mar 01, 2021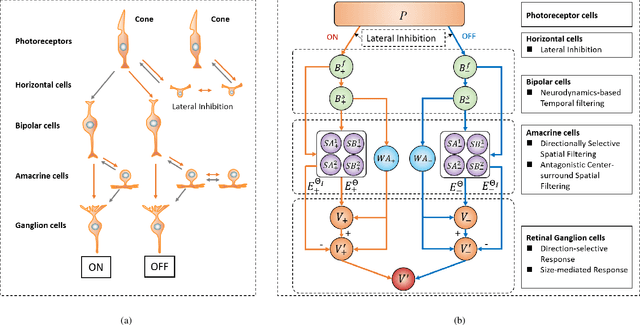
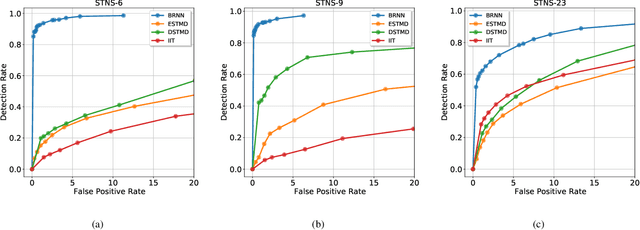

Robust and accurate detection of small moving targets in cluttered moving backgrounds is a significant and challenging problem for robotic visual systems to perform search and tracking tasks. Inspired by the neural circuitry of elementary motion vision in the mammalian retina, this paper proposes a bioinspired retinal neural network based on a new neurodynamics-based temporal filtering and multiform 2-D spatial Gabor filtering. This model can estimate motion direction accurately via only two perpendicular spatiotemporal filtering signals, and respond to small targets of different sizes and velocities by adjusting the dendrite field size of the spatial filter. Meanwhile, an algorithm of directionally selective inhibition is proposed to suppress the target-like features in the moving background, which can reduce the influence of background motion effectively. Extensive synthetic and real-data experiments show that the proposed model works stably for small targets of a wider size and velocity range, and has better detection performance than other bioinspired models. Additionally, it can also extract the information of motion direction and motion energy accurately and rapidly.