 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Reference-based Distinctive Image Captioning with Contrastive Rewards
Jun 25, 2023



Distinctive Image Captioning (DIC) -- generating distinctive captions that describe the unique details of a target image -- has received considerable attention over the last few years. A recent DIC method proposes to generate distinctive captions by comparing the target image with a set of semantic-similar reference images, i.e., reference-based DIC (Ref-DIC). It aims to force the generated captions to distinguish between the target image and the reference image. To ensure Ref-DIC models really perceive the unique objects (or attributes) in target images, we propose two new Ref-DIC benchmarks and develop a Transformer-based Ref-DIC baseline TransDIC. The model only extracts visual features from the target image, but also encodes the differences between objects in the target and reference images. Taking one step further, we propose a stronger TransDIC++, which consists of an extra contrastive learning module to make full use of the reference images. This new module is model-agnostic, which can be easily incorporated into various Ref-DIC architectures. Finally, for more trustworthy benchmarking, we propose a new evaluation metric named DisCIDEr for Ref-DIC, which evaluates both the accuracy and distinctiveness of the generated captions. Experimental results demonstrate that our TransDIC++ can generate distinctive captions. Besides, it outperforms several state-of-the-art models on the two new benchmarks over different metrics.
Rethinking the Reference-based Distinctive Image Captioning
Jul 22, 2022
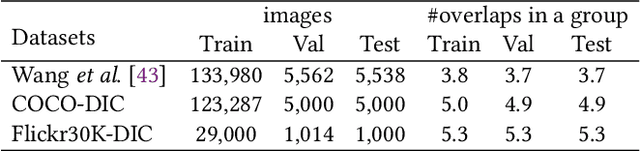
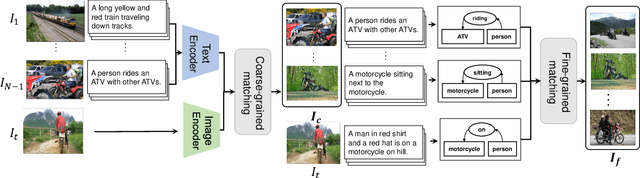
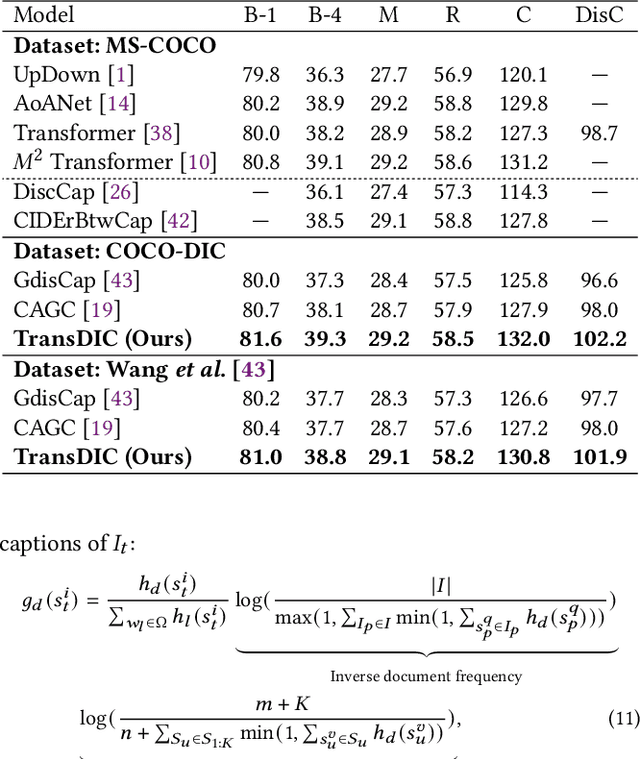
Distinctive Image Captioning (DIC) -- generating distinctive captions that describe the unique details of a target image -- has received considerable attention over the last few years. A recent DIC work proposes to generate distinctive captions by comparing the target image with a set of semantic-similar reference images, i.e., reference-based DIC (Ref-DIC). It aims to make the generated captions can tell apart the target and reference images. Unfortunately, reference images used by existing Ref-DIC works are easy to distinguish: these reference images only resemble the target image at scene-level and have few common objects, such that a Ref-DIC model can trivially generate distinctive captions even without considering the reference images. To ensure Ref-DIC models really perceive the unique objects (or attributes) in target images, we first propose two new Ref-DIC benchmarks. Specifically, we design a two-stage matching mechanism, which strictly controls the similarity between the target and reference images at object-/attribute- level (vs. scene-level). Secondly, to generate distinctive captions, we develop a strong Transformer-based Ref-DIC baseline, dubbed as TransDIC. It not only extracts visual features from the target image, but also encodes the differences between objects in the target and reference images. Finally, for more trustworthy benchmarking, we propose a new evaluation metric named DisCIDEr for Ref-DIC, which evaluates both the accuracy and distinctiveness of the generated captions. Experimental results demonstrate that our TransDIC can generate distinctive captions. Besides, it outperforms several state-of-the-art models on the two new benchmarks over different metrics.