 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Gradient Descent in Non-Convex Problems: Asymptotic Convergence with Relaxed Step-Size via Stopping Time Methods
Apr 17, 2025Stochastic Gradient Descent (SGD) is widely used in machine learning research. Previous convergence analyses of SGD under the vanishing step-size setting typically require Robbins-Monro conditions. However, in practice, a wider variety of step-size schemes are frequently employed, yet existing convergence results remain limited and often rely on strong assumptions. This paper bridges this gap by introducing a novel analytical framework based on a stopping-time method, enabling asymptotic convergence analysis of SGD under more relaxed step-size conditions and weaker assumptions. In the non-convex setting, we prove the almost sure convergence of SGD iterates for step-sizes $ \{ \epsilon_t \}_{t \geq 1} $ satisfying $\sum_{t=1}^{+\infty} \epsilon_t = +\infty$ and $\sum_{t=1}^{+\infty} \epsilon_t^p < +\infty$ for some $p > 2$. Compared with previous studies, our analysis eliminates the global Lipschitz continuity assumption on the loss function and relaxes the boundedness requirements for higher-order moments of stochastic gradients. Building upon the almost sure convergence results, we further establish $L_2$ convergence. These significantly relaxed assumptions make our theoretical results more general, thereby enhancing their applicability in practical scenarios.
Careful seeding for the k-medoids algorithm with incremental k++ cluster construction
Jul 06, 2022
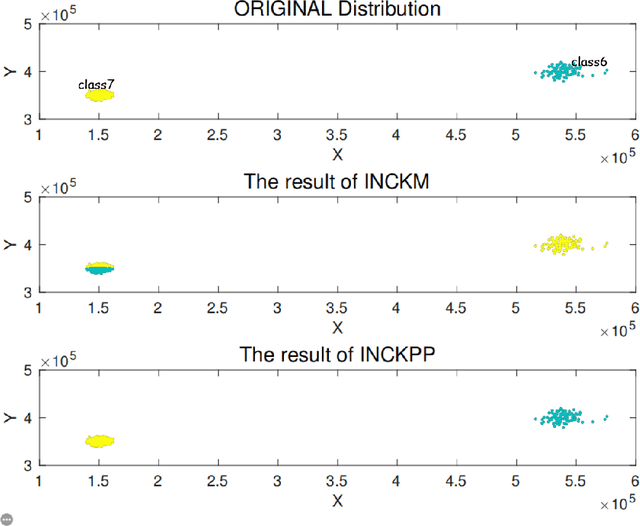
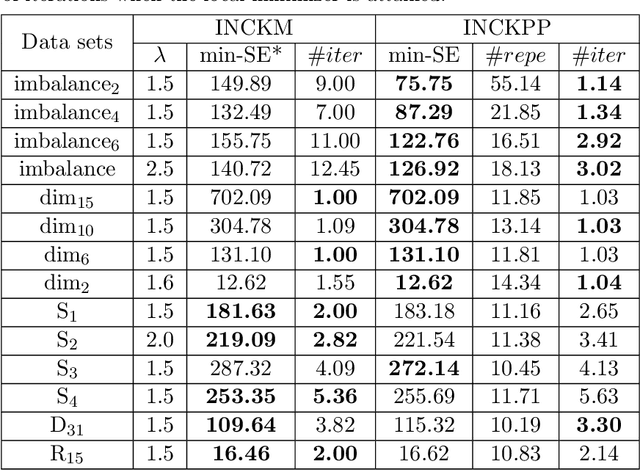

The k-medoids algorithm is a popular variant of the k-means algorithm and widely used in pattern recognition and machine learning. A main drawback of the k-medoids algorithm is that it can be trapped in local optima. An improved k-medoids algorithm (INCKM) was recently proposed to overcome this drawback, based on constructing a candidate medoids subset with a parameter choosing procedure, but it may fail when dealing with imbalanced datasets. In this paper, we propose a novel incremental k-medoids algorithm (INCKPP) which dynamically increases the number of clusters from 2 to k through a nonparametric and stochastic k-means++ search procedure. Our algorithm can overcome the parameter selection problem in the improved k-medoids algorithm, improve the clustering performance, and deal with imbalanced datasets very well. But our algorithm has a weakness in computation efficiency. To address this issue, we propose a fast INCKPP algorithm (called INCKPP$_{sample}$) which preserves the computational efficiency of the simple and fast k-medoids algorithm with an improved clustering performance. The proposed algorithm is compared with three state-of-the-art algorithms: the improved k-medoids algorithm (INCKM), the simple and fast k-medoids algorithm (FKM) and the k-means++ algorithm (KPP). Extensive experiments on both synthetic and real world datasets including imbalanced datasets illustrate the effectiveness of the proposed algorithm.
Fast Density Estimation for Density-based Clustering Methods
Sep 23, 2021



Density-based clustering algorithms are widely used for discovering clusters in pattern recognition and machine learning since they can deal with non-hyperspherical clusters and are robustness to handle outliers. However, the runtime of density-based algorithms is heavily dominated by finding neighbors and calculating the density of each point which is time-consuming. To address this issue, this paper proposes a density-based clustering framework by using the fast principal component analysis, which can be applied to density based methods to prune unnecessary distance calculations when finding neighbors and estimating densities. By applying this clustering framework to the Density Based Spatial Clustering of Applications with Noise (DBSCAN) algorithm, an improved DBSCAN (called IDBSCAN) is obtained, which preserves the advantage of DBSCAN and meanwhile, greatly reduces the computation of redundant distances. Experiments on five benchmark datasets demonstrate that the proposed IDBSCAN algorithm improves the computational efficiency significantly.