 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHAAF: Hierarchical Adaptation and Alignment of Foundation Models for Few-Shot Pathology Anomaly Detection
Jan 24, 2026Precision pathology relies on detecting fine-grained morphological abnormalities within specific Regions of Interest (ROIs), as these local, texture-rich cues - rather than global slide contexts - drive expert diagnostic reasoning. While Vision-Language (V-L) models promise data efficiency by leveraging semantic priors, adapting them faces a critical Granularity Mismatch, where generic representations fail to resolve such subtle defects. Current adaptation methods often treat modalities as independent streams, failing to ground semantic prompts in ROI-specific visual contexts. To bridge this gap, we propose the Hierarchical Adaptation and Alignment Framework (HAAF). At its core is a novel Cross-Level Scaled Alignment (CLSA) mechanism that enforces a sequential calibration order: visual features first inject context into text prompts to generate content-adaptive descriptors, which then spatially guide the visual encoder to spotlight anomalies. Additionally, a dual-branch inference strategy integrates semantic scores with geometric prototypes to ensure stability in few-shot settings. Experiments on four benchmarks show HAAF significantly outperforms state-of-the-art methods and effectively scales with domain-specific backbones (e.g., CONCH) in low-resource scenarios.
Unleashing the True Potential of LLMs: A Feedback-Triggered Self-Correction with Long-Term Multipath Decoding
Sep 09, 2025Large Language Models (LLMs) have achieved remarkable performance across diverse tasks, yet their susceptibility to generating incorrect content during inference remains a critical unsolved challenge. While self-correction methods offer potential solutions, their effectiveness is hindered by two inherent limitations: (1) the absence of reliable guidance signals for error localization, and (2) the restricted reasoning depth imposed by conventional next-token decoding paradigms. To address these issues, we propose Feedback-Triggered Regeneration (FTR), a novel framework that synergizes user feedback with enhanced decoding dynamics. Specifically, FTR activates response regeneration only upon receiving negative user feedback, thereby circumventing error propagation from faulty self-assessment while preserving originally correct outputs. Furthermore, we introduce Long-Term Multipath (LTM) decoding, which enables systematic exploration of multiple reasoning trajectories through delayed sequence evaluation, effectively overcoming the myopic decision-making characteristic of standard next-token prediction. Extensive experiments on mathematical reasoning and code generation benchmarks demonstrate that our framework achieves consistent and significant improvements over state-of-the-art prompt-based self-correction methods.
Integrating Pathology and CT Imaging for Personalized Recurrence Risk Prediction in Renal Cancer
Aug 29, 2025Recurrence risk estimation in clear cell renal cell carcinoma (ccRCC) is essential for guiding postoperative surveillance and treatment. The Leibovich score remains widely used for stratifying distant recurrence risk but offers limited patient-level resolution and excludes imaging information. This study evaluates multimodal recurrence prediction by integrating preoperative computed tomography (CT) and postoperative histopathology whole-slide images (WSIs). A modular deep learning framework with pretrained encoders and Cox-based survival modeling was tested across unimodal, late fusion, and intermediate fusion setups. In a real-world ccRCC cohort, WSI-based models consistently outperformed CT-only models, underscoring the prognostic strength of pathology. Intermediate fusion further improved performance, with the best model (TITAN-CONCH with ResNet-18) approaching the adjusted Leibovich score. Random tie-breaking narrowed the gap between the clinical baseline and learned models, suggesting discretization may overstate individualized performance. Using simple embedding concatenation, radiology added value primarily through fusion. These findings demonstrate the feasibility of foundation model-based multimodal integration for personalized ccRCC risk prediction. Future work should explore more expressive fusion strategies, larger multimodal datasets, and general-purpose CT encoders to better match pathology modeling capacity.
11Plus-Bench: Demystifying Multimodal LLM Spatial Reasoning with Cognitive-Inspired Analysis
Aug 27, 2025For human cognitive process, spatial reasoning and perception are closely entangled, yet the nature of this interplay remains underexplored in the evaluation of multimodal large language models (MLLMs). While recent MLLM advancements show impressive performance on reasoning, their capacity for human-like spatial cognition remains an open question. In this work, we introduce a systematic evaluation framework to assess the spatial reasoning abilities of state-of-the-art MLLMs relative to human performance. Central to our work is 11Plus-Bench, a high-quality benchmark derived from realistic standardized spatial aptitude tests. 11Plus-Bench also features fine-grained expert annotations of both perceptual complexity and reasoning process, enabling detailed instance-level analysis of model behavior. Through extensive experiments across 14 MLLMs and human evaluation, we find that current MLLMs exhibit early signs of spatial cognition. Despite a large performance gap compared to humans, MLLMs' cognitive profiles resemble those of humans in that cognitive effort correlates strongly with reasoning-related complexity. However, instance-level performance in MLLMs remains largely random, whereas human correctness is highly predictable and shaped by abstract pattern complexity. These findings highlight both emerging capabilities and limitations in current MLLMs' spatial reasoning capabilities and provide actionable insights for advancing model design.
4D Visual Pre-training for Robot Learning
Aug 24, 2025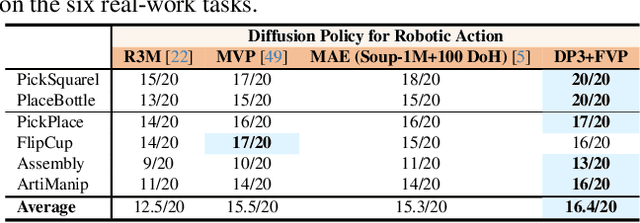
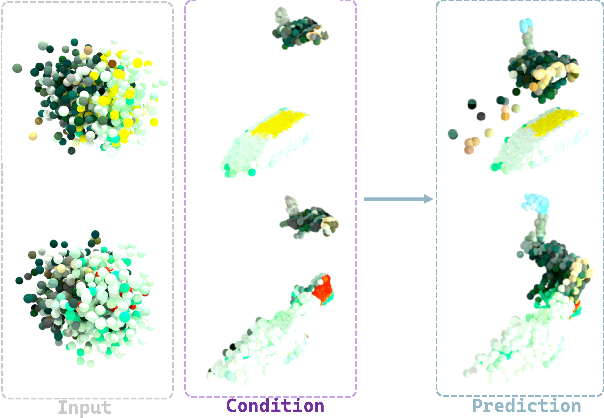
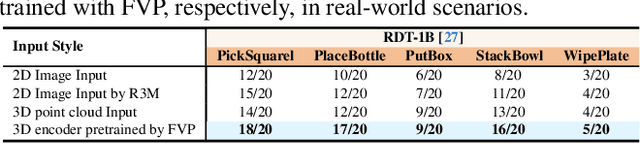
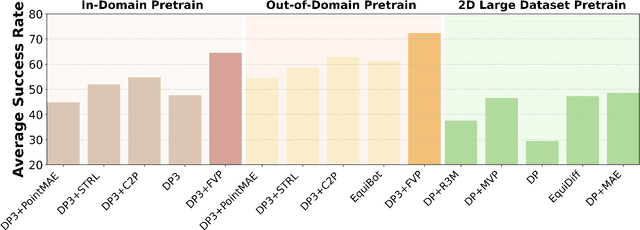
General visual representations learned from web-scale datasets for robotics have achieved great success in recent years, enabling data-efficient robot learning on manipulation tasks; yet these pre-trained representations are mostly on 2D images, neglecting the inherent 3D nature of the world. However, due to the scarcity of large-scale 3D data, it is still hard to extract a universal 3D representation from web datasets. Instead, we are seeking a general visual pre-training framework that could improve all 3D representations as an alternative. Our framework, called FVP, is a novel 4D Visual Pre-training framework for real-world robot learning. FVP frames the visual pre-training objective as a next-point-cloud-prediction problem, models the prediction model as a diffusion model, and pre-trains the model on the larger public datasets directly. Across twelve real-world manipulation tasks, FVP boosts the average success rate of 3D Diffusion Policy (DP3) for these tasks by 28%. The FVP pre-trained DP3 achieves state-of-the-art performance across imitation learning methods. Moreover, the efficacy of FVP adapts across various point cloud encoders and datasets. Finally, we apply FVP to the RDT-1B, a larger Vision-Language-Action robotic model, enhancing its performance on various robot tasks. Our project page is available at: https://4d- visual-pretraining.github.io/.
Tady: A Neural Disassembler without Structural Constraint Violations
Jun 16, 2025Disassembly is a crucial yet challenging step in binary analysis. While emerging neural disassemblers show promise for efficiency and accuracy, they frequently generate outputs violating fundamental structural constraints, which significantly compromise their practical usability. To address this critical problem, we regularize the disassembly solution space by formalizing and applying key structural constraints based on post-dominance relations. This approach systematically detects widespread errors in existing neural disassemblers' outputs. These errors often originate from models' limited context modeling and instruction-level decoding that neglect global structural integrity. We introduce Tady, a novel neural disassembler featuring an improved model architecture and a dedicated post-processing algorithm, specifically engineered to address these deficiencies. Comprehensive evaluations on diverse binaries demonstrate that Tady effectively eliminates structural constraint violations and functions with high efficiency, while maintaining instruction-level accuracy.
The Butterfly Effect in Pathology: Exploring Security in Pathology Foundation Models
May 30, 2025With the widespread adoption of pathology foundation models in both research and clinical decision support systems, exploring their security has become a critical concern. However, despite their growing impact, the vulnerability of these models to adversarial attacks remains largely unexplored. In this work, we present the first systematic investigation into the security of pathology foundation models for whole slide image~(WSI) analysis against adversarial attacks. Specifically, we introduce the principle of \textit{local perturbation with global impact} and propose a label-free attack framework that operates without requiring access to downstream task labels. Under this attack framework, we revise four classical white-box attack methods and redefine the perturbation budget based on the characteristics of WSI. We conduct comprehensive experiments on three representative pathology foundation models across five datasets and six downstream tasks. Despite modifying only 0.1\% of patches per slide with imperceptible noise, our attack leads to downstream accuracy degradation that can reach up to 20\% in the worst cases. Furthermore, we analyze key factors that influence attack success, explore the relationship between patch-level vulnerability and semantic content, and conduct a preliminary investigation into potential defence strategies. These findings lay the groundwork for future research on the adversarial robustness and reliable deployment of pathology foundation models. Our code is publicly available at: https://github.com/Jiashuai-Liu-hmos/Attack-WSI-pathology-foundation-models.
DecompileBench: A Comprehensive Benchmark for Evaluating Decompilers in Real-World Scenarios
May 16, 2025Decompilers are fundamental tools for critical security tasks, from vulnerability discovery to malware analysis, yet their evaluation remains fragmented. Existing approaches primarily focus on syntactic correctness through synthetic micro-benchmarks or subjective human ratings, failing to address real-world requirements for semantic fidelity and analyst usability. We present DecompileBench, the first comprehensive framework that enables effective evaluation of decompilers in reverse engineering workflows through three key components: \textit{real-world function extraction} (comprising 23,400 functions from 130 real-world programs), \textit{runtime-aware validation}, and \textit{automated human-centric assessment} using LLM-as-Judge to quantify the effectiveness of decompilers in reverse engineering workflows. Through a systematic comparison between six industrial-strength decompilers and six recent LLM-powered approaches, we demonstrate that LLM-based methods surpass commercial tools in code understandability despite 52.2% lower functionality correctness. These findings highlight the potential of LLM-based approaches to transform human-centric reverse engineering. We open source \href{https://github.com/Jennieett/DecompileBench}{DecompileBench} to provide a framework to advance research on decompilers and assist security experts in making informed tool selections based on their specific requirements.
Generalised Label-free Artefact Cleaning for Real-time Medical Pulsatile Time Series
Apr 29, 2025Artefacts compromise clinical decision-making in the use of medical time series. Pulsatile waveforms offer probabilities for accurate artefact detection, yet most approaches rely on supervised manners and overlook patient-level distribution shifts. To address these issues, we introduce a generalised label-free framework, GenClean, for real-time artefact cleaning and leverage an in-house dataset of 180,000 ten-second arterial blood pressure (ABP) samples for training. We first investigate patient-level generalisation, demonstrating robust performances under both intra- and inter-patient distribution shifts. We further validate its effectiveness through challenging cross-disease cohort experiments on the MIMIC-III database. Additionally, we extend our method to photoplethysmography (PPG), highlighting its applicability to diverse medical pulsatile signals. Finally, its integration into ICM+, a clinical research monitoring software, confirms the real-time feasibility of our framework, emphasising its practical utility in continuous physiological monitoring. This work provides a foundational step toward precision medicine in improving the reliability of high-resolution medical time series analysis
ST-Prompt Guided Histological Hypergraph Learning for Spatial Gene Expression Prediction
Mar 21, 2025
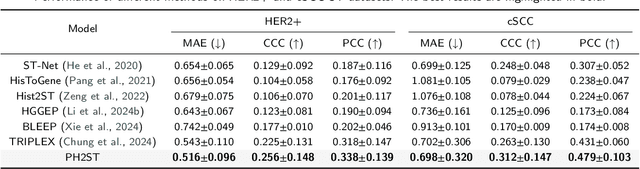


Spatial Transcriptomics (ST) reveals the spatial distribution of gene expression in tissues, offering critical insights into biological processes and disease mechanisms. However, predicting ST from H\&E-stained histology images is challenging due to the heterogeneous relationship between histomorphology and gene expression, which arises from substantial variability across different patients and tissue sections. A more practical and valuable approach is to utilize ST data from a few local regions to predict the spatial transcriptomic landscape across the remaining regions in H&E slides. In response, we propose PHG2ST, an ST-prompt guided histological hypergraph learning framework, which leverages sparse ST signals as prompts to guide histological hypergraph learning for global spatial gene expression prediction. Our framework fuses histological hypergraph representations at multiple scales through a masked ST-prompt encoding mechanism, improving robustness and generalizability. Benchmark evaluations on two public ST datasets demonstrate that PHG2ST outperforms the existing state-of-the-art methods and closely aligns with the ground truth. These results underscore the potential of leveraging sparse local ST data for scalable and cost-effective spatial gene expression mapping in real-world biomedical applications.