 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgent2World: Learning to Generate Symbolic World Models via Adaptive Multi-Agent Feedback
Dec 26, 2025Symbolic world models (e.g., PDDL domains or executable simulators) are central to model-based planning, but training LLMs to generate such world models is limited by the lack of large-scale verifiable supervision. Current approaches rely primarily on static validation methods that fail to catch behavior-level errors arising from interactive execution. In this paper, we propose Agent2World, a tool-augmented multi-agent framework that achieves strong inference-time world-model generation and also serves as a data engine for supervised fine-tuning, by grounding generation in multi-agent feedback. Agent2World follows a three-stage pipeline: (i) A Deep Researcher agent performs knowledge synthesis by web searching to address specification gaps; (ii) A Model Developer agent implements executable world models; And (iii) a specialized Testing Team conducts adaptive unit testing and simulation-based validation. Agent2World demonstrates superior inference-time performance across three benchmarks spanning both Planning Domain Definition Language (PDDL) and executable code representations, achieving consistent state-of-the-art results. Beyond inference, Testing Team serves as an interactive environment for the Model Developer, providing behavior-aware adaptive feedback that yields multi-turn training trajectories. The model fine-tuned on these trajectories substantially improves world-model generation, yielding an average relative gain of 30.95% over the same model before training. Project page: https://agent2world.github.io.
Text2World: Benchmarking Large Language Models for Symbolic World Model Generation
Feb 18, 2025


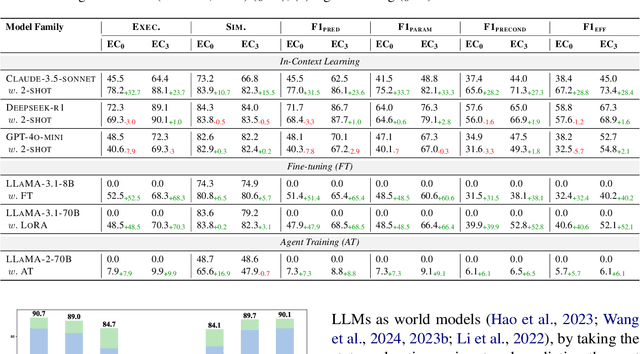
Recently, there has been growing interest in leveraging large language models (LLMs) to generate symbolic world models from textual descriptions. Although LLMs have been extensively explored in the context of world modeling, prior studies encountered several challenges, including evaluation randomness, dependence on indirect metrics, and a limited domain scope. To address these limitations, we introduce a novel benchmark, Text2World, based on planning domain definition language (PDDL), featuring hundreds of diverse domains and employing multi-criteria, execution-based metrics for a more robust evaluation. We benchmark current LLMs using Text2World and find that reasoning models trained with large-scale reinforcement learning outperform others. However, even the best-performing model still demonstrates limited capabilities in world modeling. Building on these insights, we examine several promising strategies to enhance the world modeling capabilities of LLMs, including test-time scaling, agent training, and more. We hope that Text2World can serve as a crucial resource, laying the groundwork for future research in leveraging LLMs as world models. The project page is available at https://text-to-world.github.io/.
RoboTwin: Dual-Arm Robot Benchmark with Generative Digital Twins (early version)
Sep 04, 2024



Effective collaboration of dual-arm robots and their tool use capabilities are increasingly important areas in the advancement of robotics. These skills play a significant role in expanding robots' ability to operate in diverse real-world environments. However, progress is impeded by the scarcity of specialized training data. This paper introduces RoboTwin, a novel benchmark dataset combining real-world teleoperated data with synthetic data from digital twins, designed for dual-arm robotic scenarios. Using the COBOT Magic platform, we have collected diverse data on tool usage and human-robot interaction. We present a innovative approach to creating digital twins using AI-generated content, transforming 2D images into detailed 3D models. Furthermore, we utilize large language models to generate expert-level training data and task-specific pose sequences oriented toward functionality. Our key contributions are: 1) the RoboTwin benchmark dataset, 2) an efficient real-to-simulation pipeline, and 3) the use of language models for automatic expert-level data generation. These advancements are designed to address the shortage of robotic training data, potentially accelerating the development of more capable and versatile robotic systems for a wide range of real-world applications. The project page is available at https://robotwin-benchmark.github.io/early-version/