 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Butterfly Effect in Pathology: Exploring Security in Pathology Foundation Models
May 30, 2025With the widespread adoption of pathology foundation models in both research and clinical decision support systems, exploring their security has become a critical concern. However, despite their growing impact, the vulnerability of these models to adversarial attacks remains largely unexplored. In this work, we present the first systematic investigation into the security of pathology foundation models for whole slide image~(WSI) analysis against adversarial attacks. Specifically, we introduce the principle of \textit{local perturbation with global impact} and propose a label-free attack framework that operates without requiring access to downstream task labels. Under this attack framework, we revise four classical white-box attack methods and redefine the perturbation budget based on the characteristics of WSI. We conduct comprehensive experiments on three representative pathology foundation models across five datasets and six downstream tasks. Despite modifying only 0.1\% of patches per slide with imperceptible noise, our attack leads to downstream accuracy degradation that can reach up to 20\% in the worst cases. Furthermore, we analyze key factors that influence attack success, explore the relationship between patch-level vulnerability and semantic content, and conduct a preliminary investigation into potential defence strategies. These findings lay the groundwork for future research on the adversarial robustness and reliable deployment of pathology foundation models. Our code is publicly available at: https://github.com/Jiashuai-Liu-hmos/Attack-WSI-pathology-foundation-models.
ST-Prompt Guided Histological Hypergraph Learning for Spatial Gene Expression Prediction
Mar 21, 2025
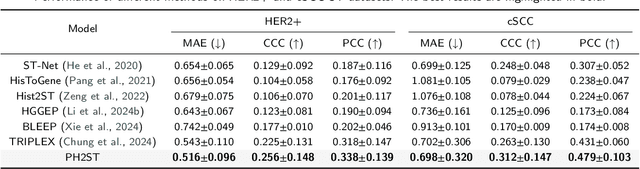


Spatial Transcriptomics (ST) reveals the spatial distribution of gene expression in tissues, offering critical insights into biological processes and disease mechanisms. However, predicting ST from H\&E-stained histology images is challenging due to the heterogeneous relationship between histomorphology and gene expression, which arises from substantial variability across different patients and tissue sections. A more practical and valuable approach is to utilize ST data from a few local regions to predict the spatial transcriptomic landscape across the remaining regions in H&E slides. In response, we propose PHG2ST, an ST-prompt guided histological hypergraph learning framework, which leverages sparse ST signals as prompts to guide histological hypergraph learning for global spatial gene expression prediction. Our framework fuses histological hypergraph representations at multiple scales through a masked ST-prompt encoding mechanism, improving robustness and generalizability. Benchmark evaluations on two public ST datasets demonstrate that PHG2ST outperforms the existing state-of-the-art methods and closely aligns with the ground truth. These results underscore the potential of leveraging sparse local ST data for scalable and cost-effective spatial gene expression mapping in real-world biomedical applications.
Step-Video-TI2V Technical Report: A State-of-the-Art Text-Driven Image-to-Video Generation Model
Mar 14, 2025We present Step-Video-TI2V, a state-of-the-art text-driven image-to-video generation model with 30B parameters, capable of generating videos up to 102 frames based on both text and image inputs. We build Step-Video-TI2V-Eval as a new benchmark for the text-driven image-to-video task and compare Step-Video-TI2V with open-source and commercial TI2V engines using this dataset. Experimental results demonstrate the state-of-the-art performance of Step-Video-TI2V in the image-to-video generation task. Both Step-Video-TI2V and Step-Video-TI2V-Eval are available at https://github.com/stepfun-ai/Step-Video-TI2V.
Step-Audio: Unified Understanding and Generation in Intelligent Speech Interaction
Feb 18, 2025Real-time speech interaction, serving as a fundamental interface for human-machine collaboration, holds immense potential. However, current open-source models face limitations such as high costs in voice data collection, weakness in dynamic control, and limited intelligence. To address these challenges, this paper introduces Step-Audio, the first production-ready open-source solution. Key contributions include: 1) a 130B-parameter unified speech-text multi-modal model that achieves unified understanding and generation, with the Step-Audio-Chat version open-sourced; 2) a generative speech data engine that establishes an affordable voice cloning framework and produces the open-sourced lightweight Step-Audio-TTS-3B model through distillation; 3) an instruction-driven fine control system enabling dynamic adjustments across dialects, emotions, singing, and RAP; 4) an enhanced cognitive architecture augmented with tool calling and role-playing abilities to manage complex tasks effectively. Based on our new StepEval-Audio-360 evaluation benchmark, Step-Audio achieves state-of-the-art performance in human evaluations, especially in terms of instruction following. On open-source benchmarks like LLaMA Question, shows 9.3% average performance improvement, demonstrating our commitment to advancing the development of open-source multi-modal language technologies. Our code and models are available at https://github.com/stepfun-ai/Step-Audio.
CoxKAN: Kolmogorov-Arnold Networks for Interpretable, High-Performance Survival Analysis
Sep 06, 2024Survival analysis is a branch of statistics used for modeling the time until a specific event occurs and is widely used in medicine, engineering, finance, and many other fields. When choosing survival models, there is typically a trade-off between performance and interpretability, where the highest performance is achieved by black-box models based on deep learning. This is a major problem in fields such as medicine where practitioners are reluctant to blindly trust black-box models to make important patient decisions. Kolmogorov-Arnold Networks (KANs) were recently proposed as an interpretable and accurate alternative to multi-layer perceptrons (MLPs). We introduce CoxKAN, a Cox proportional hazards Kolmogorov-Arnold Network for interpretable, high-performance survival analysis. We evaluate the proposed CoxKAN on 4 synthetic datasets and 9 real medical datasets. The synthetic experiments demonstrate that CoxKAN accurately recovers interpretable symbolic formulae for the hazard function, and effectively performs automatic feature selection. Evaluation on the 9 real datasets show that CoxKAN consistently outperforms the Cox proportional hazards model and achieves performance that is superior or comparable to that of tuned MLPs. Furthermore, we find that CoxKAN identifies complex interactions between predictor variables that would be extremely difficult to recognise using existing survival methods, and automatically finds symbolic formulae which uncover the precise effect of important biomarkers on patient risk.