 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeST-Prompt Guided Histological Hypergraph Learning for Spatial Gene Expression Prediction
Mar 21, 2025
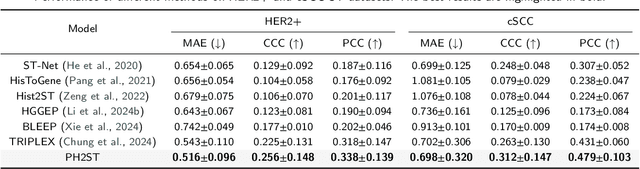


Spatial Transcriptomics (ST) reveals the spatial distribution of gene expression in tissues, offering critical insights into biological processes and disease mechanisms. However, predicting ST from H\&E-stained histology images is challenging due to the heterogeneous relationship between histomorphology and gene expression, which arises from substantial variability across different patients and tissue sections. A more practical and valuable approach is to utilize ST data from a few local regions to predict the spatial transcriptomic landscape across the remaining regions in H&E slides. In response, we propose PHG2ST, an ST-prompt guided histological hypergraph learning framework, which leverages sparse ST signals as prompts to guide histological hypergraph learning for global spatial gene expression prediction. Our framework fuses histological hypergraph representations at multiple scales through a masked ST-prompt encoding mechanism, improving robustness and generalizability. Benchmark evaluations on two public ST datasets demonstrate that PHG2ST outperforms the existing state-of-the-art methods and closely aligns with the ground truth. These results underscore the potential of leveraging sparse local ST data for scalable and cost-effective spatial gene expression mapping in real-world biomedical applications.
ViLa-MIL: Dual-scale Vision-Language Multiple Instance Learning for Whole Slide Image Classification
Feb 12, 2025



Multiple instance learning (MIL)-based framework has become the mainstream for processing the whole slide image (WSI) with giga-pixel size and hierarchical image context in digital pathology. However, these methods heavily depend on a substantial number of bag-level labels and solely learn from the original slides, which are easily affected by variations in data distribution. Recently, vision language model (VLM)-based methods introduced the language prior by pre-training on large-scale pathological image-text pairs. However, the previous text prompt lacks the consideration of pathological prior knowledge, therefore does not substantially boost the model's performance. Moreover, the collection of such pairs and the pre-training process are very time-consuming and source-intensive.To solve the above problems, we propose a dual-scale vision-language multiple instance learning (ViLa-MIL) framework for whole slide image classification. Specifically, we propose a dual-scale visual descriptive text prompt based on the frozen large language model (LLM) to boost the performance of VLM effectively. To transfer the VLM to process WSI efficiently, for the image branch, we propose a prototype-guided patch decoder to aggregate the patch features progressively by grouping similar patches into the same prototype; for the text branch, we introduce a context-guided text decoder to enhance the text features by incorporating the multi-granular image contexts. Extensive studies on three multi-cancer and multi-center subtyping datasets demonstrate the superiority of ViLa-MIL.
Meta Mask Correction for Nuclei Segmentation in Histopathological Image
Nov 24, 2021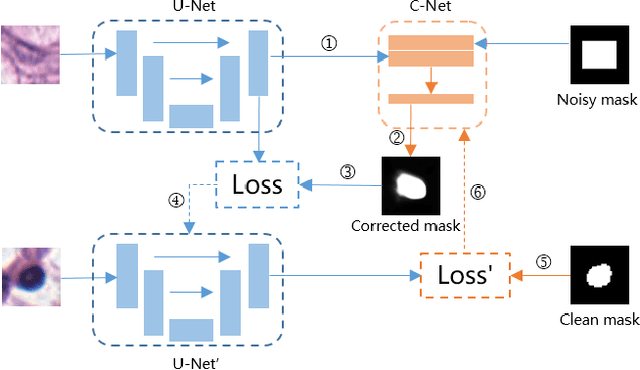

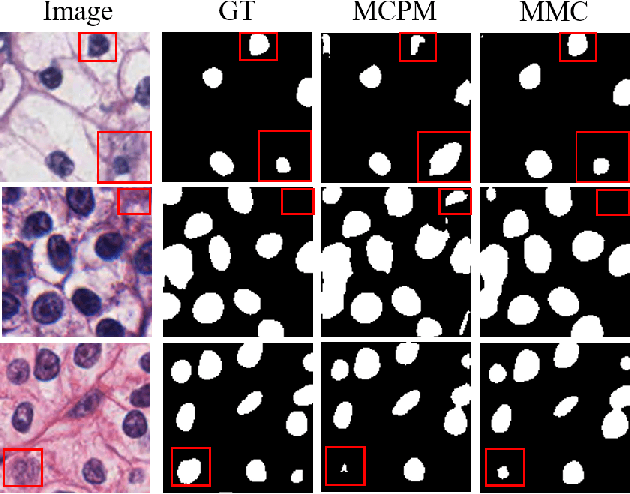
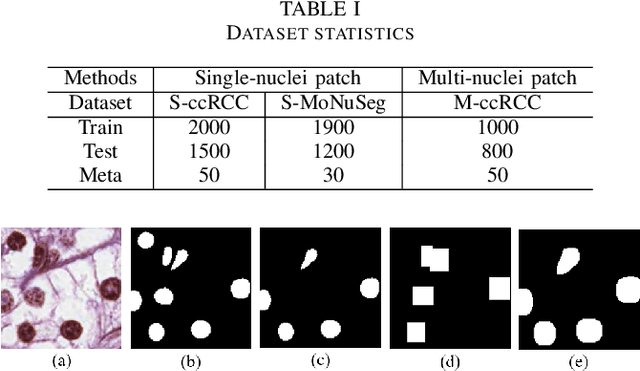
Nuclei segmentation is a fundamental task in digital pathology analysis and can be automated by deep learning-based methods. However, the development of such an automated method requires a large amount of data with precisely annotated masks which is hard to obtain. Training with weakly labeled data is a popular solution for reducing the workload of annotation. In this paper, we propose a novel meta-learning-based nuclei segmentation method which follows the label correction paradigm to leverage data with noisy masks. Specifically, we design a fully conventional meta-model that can correct noisy masks using a small amount of clean meta-data. Then the corrected masks can be used to supervise the training of the segmentation model. Meanwhile, a bi-level optimization method is adopted to alternately update the parameters of the main segmentation model and the meta-model in an end-to-end way. Extensive experimental results on two nuclear segmentation datasets show that our method achieves the state-of-the-art result. It even achieves comparable performance with the model training on supervised data in some noisy settings.
Nuclei Grading of Clear Cell Renal Cell Carcinoma in Histopathological Image by Composite High-Resolution Network
Jun 20, 2021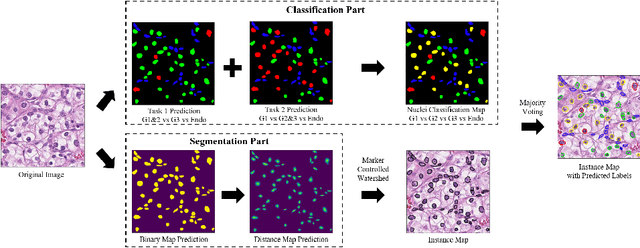

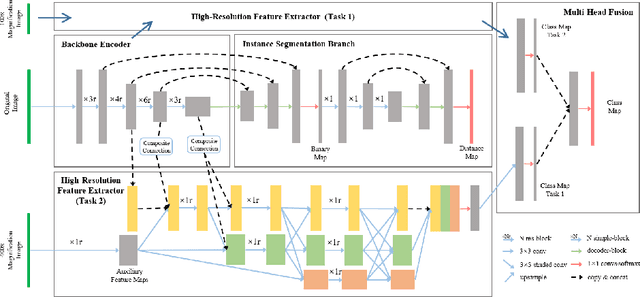

The grade of clear cell renal cell carcinoma (ccRCC) is a critical prognostic factor, making ccRCC nuclei grading a crucial task in RCC pathology analysis. Computer-aided nuclei grading aims to improve pathologists' work efficiency while reducing their misdiagnosis rate by automatically identifying the grades of tumor nuclei within histopathological images. Such a task requires precisely segment and accurately classify the nuclei. However, most of the existing nuclei segmentation and classification methods can not handle the inter-class similarity property of nuclei grading, thus can not be directly applied to the ccRCC grading task. In this paper, we propose a Composite High-Resolution Network for ccRCC nuclei grading. Specifically, we propose a segmentation network called W-Net that can separate the clustered nuclei. Then, we recast the fine-grained classification of nuclei to two cross-category classification tasks, based on two high-resolution feature extractors (HRFEs) which are proposed for learning these two tasks. The two HRFEs share the same backbone encoder with W-Net by a composite connection so that meaningful features for the segmentation task can be inherited for the classification task. Last, a head-fusion block is applied to generate the predicted label of each nucleus. Furthermore, we introduce a dataset for ccRCC nuclei grading, containing 1000 image patches with 70945 annotated nuclei. We demonstrate that our proposed method achieves state-of-the-art performance compared to existing methods on this large ccRCC grading dataset.
Renal Cell Carcinoma Detection and Subtyping with Minimal Point-Based Annotation in Whole-Slide Images
Aug 12, 2020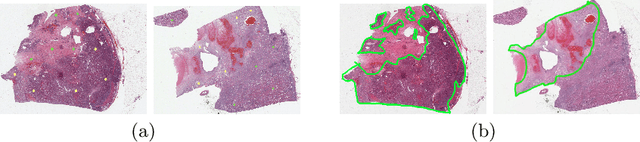
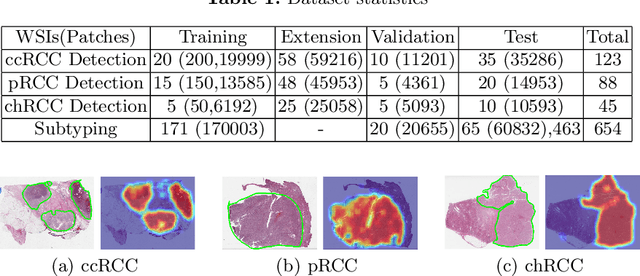
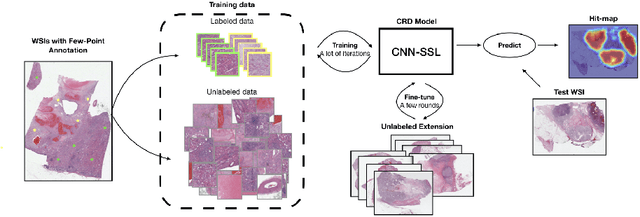
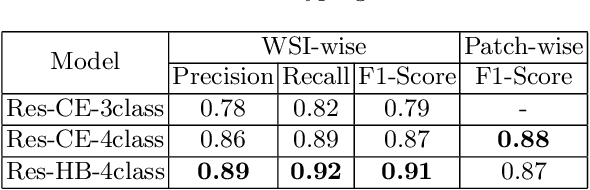
Obtaining a large amount of labeled data in medical imaging is laborious and time-consuming, especially for histopathology. However, it is much easier and cheaper to get unlabeled data from whole-slide images (WSIs). Semi-supervised learning (SSL) is an effective way to utilize unlabeled data and alleviate the need for labeled data. For this reason, we proposed a framework that employs an SSL method to accurately detect cancerous regions with a novel annotation method called Minimal Point-Based annotation, and then utilize the predicted results with an innovative hybrid loss to train a classification model for subtyping. The annotator only needs to mark a few points and label them are cancer or not in each WSI. Experiments on three significant subtypes of renal cell carcinoma (RCC) proved that the performance of the classifier trained with the Min-Point annotated dataset is comparable to a classifier trained with the segmentation annotated dataset for cancer region detection. And the subtyping model outperforms a model trained with only diagnostic labels by 12% in terms of f1-score for testing WSIs.
OpenHI2 -- Open source histopathological image platform
Jan 15, 2020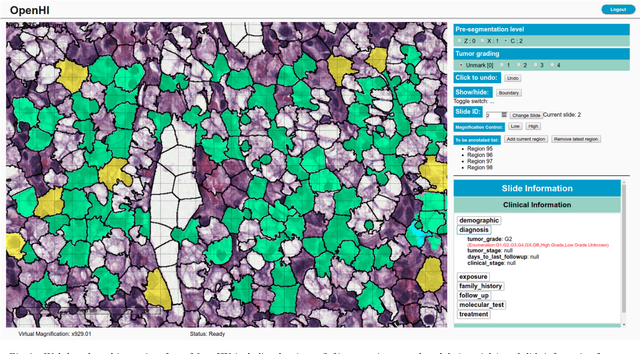
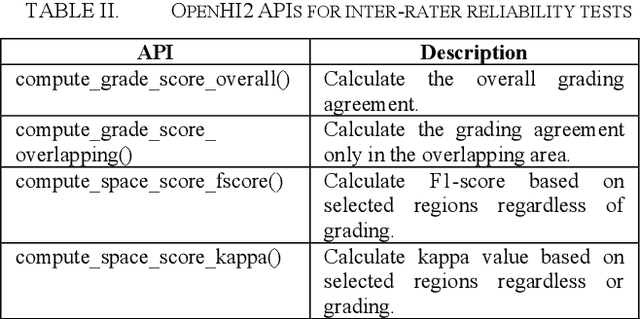
Transition from conventional to digital pathology requires a new category of biomedical informatic infrastructure which could facilitate delicate pathological routine. Pathological diagnoses are sensitive to many external factors and is known to be subjective. Only systems that can meet strict requirements in pathology would be able to run along pathological routines and eventually digitized the study area, and the developed platform should comply with existing pathological routines and international standards. Currently, there are a number of available software tools which can perform histopathological tasks including virtual slide viewing, annotating, and basic image analysis, however, none of them can serve as a digital platform for pathology. Here we describe OpenHI2, an enhanced version Open Histopathological Image platform which is capable of supporting all basic pathological tasks and file formats; ready to be deployed in medical institutions on a standard server environment or cloud computing infrastructure. In this paper, we also describe the development decisions for the platform and propose solutions to overcome technical challenges so that OpenHI2 could be used as a platform for histopathological images. Further addition can be made to the platform since each component is modularized and fully documented. OpenHI2 is free, open-source, and available at https://gitlab.com/BioAI/OpenHI.
Effects of annotation granularity in deep learning models for histopathological images
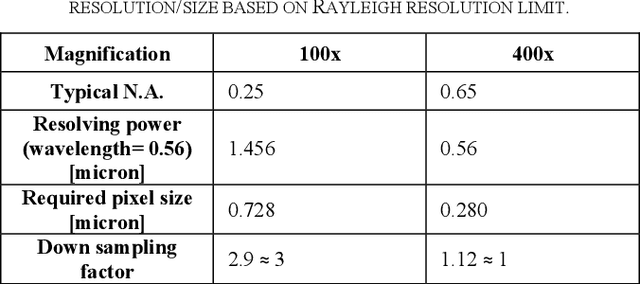
Jan 14, 2020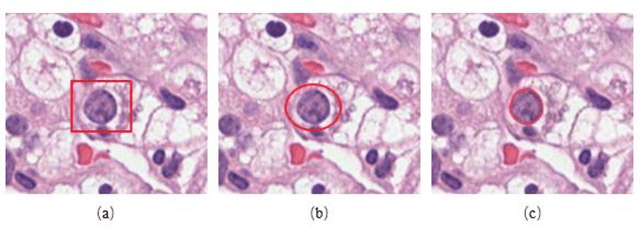

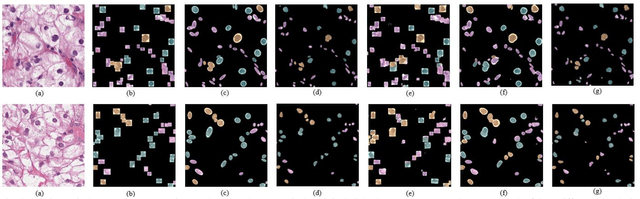

Pathological is crucial to cancer diagnosis. Usually, Pathologists draw their conclusion based on observed cell and tissue structure on histology slides. Rapid development in machine learning, especially deep learning have established robust and accurate classifiers. They are being used to analyze histopathological slides and assist pathologists in diagnosis. Most machine learning systems rely heavily on annotated data sets to gain experiences and knowledge to correctly and accurately perform various tasks such as classification and segmentation. This work investigates different granularity of annotations in histopathological data set including image-wise, bounding box, ellipse-wise, and pixel-wise to verify the influence of annotation in pathological slide on deep learning models. We design corresponding experiments to test classification and segmentation performance of deep learning models based on annotations with different annotation granularity. In classification, state-of-the-art deep learning-based classifiers perform better when trained by pixel-wise annotation dataset. On average, precision, recall and F1-score improves by 7.87%, 8.83% and 7.85% respectively. Thus, it is suggested that finer granularity annotations are better utilized by deep learning algorithms in classification tasks. Similarly, semantic segmentation algorithms can achieve 8.33% better segmentation accuracy when trained by pixel-wise annotations. Our study shows not only that finer-grained annotation can improve the performance of deep learning models, but also help extracts more accurate phenotypic information from histopathological slides. Intelligence systems trained on granular annotations may help pathologists inspecting certain regions for better diagnosis. The compartmentalized prediction approach similar to this work may contribute to phenotype and genotype association studies.