 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Automating Blockchain Consensus Verification with IsabeLLM
Jan 12, 2026Consensus protocols are crucial for a blockchain system as they are what allow agreement between the system's nodes in a potentially adversarial environment. For this reason, it is paramount to ensure their correct design and implementation to prevent such adversaries from carrying out malicious behaviour. Formal verification allows us to ensure the correctness of such protocols, but requires high levels of effort and expertise to carry out and thus is often omitted in the development process. In this paper, we present IsabeLLM, a tool that integrates the proof assistant Isabelle with a Large Language Model to assist and automate proofs. We demonstrate the effectiveness of IsabeLLM by using it to develop a novel model of Bitcoin's Proof of Work consensus protocol and verify its correctness. We use the DeepSeek R1 API for this demonstration and found that we were able to generate correct proofs for each of the non-trivial lemmas present in the verification.
Behavior Preference Regression for Offline Reinforcement Learning
Mar 02, 2025Offline reinforcement learning (RL) methods aim to learn optimal policies with access only to trajectories in a fixed dataset. Policy constraint methods formulate policy learning as an optimization problem that balances maximizing reward with minimizing deviation from the behavior policy. Closed form solutions to this problem can be derived as weighted behavioral cloning objectives that, in theory, must compute an intractable partition function. Reinforcement learning has gained popularity in language modeling to align models with human preferences; some recent works consider paired completions that are ranked by a preference model following which the likelihood of the preferred completion is directly increased. We adapt this approach of paired comparison. By reformulating the paired-sample optimization problem, we fit the maximum-mode of the Q function while maximizing behavioral consistency of policy actions. This yields our algorithm, Behavior Preference Regression for offline RL (BPR). We empirically evaluate BPR on the widely used D4RL Locomotion and Antmaze datasets, as well as the more challenging V-D4RL suite, which operates in image-based state spaces. BPR demonstrates state-of-the-art performance over all domains. Our on-policy experiments suggest that BPR takes advantage of the stability of on-policy value functions with minimal perceptible performance degradation on Locomotion datasets.
SoK: Decentralized AI (DeAI)
Nov 26, 2024The centralization of Artificial Intelligence (AI) poses significant challenges, including single points of failure, inherent biases, data privacy concerns, and scalability issues. These problems are especially prevalent in closed-source large language models (LLMs), where user data is collected and used without transparency. To mitigate these issues, blockchain-based decentralized AI (DeAI) has emerged as a promising solution. DeAI combines the strengths of both blockchain and AI technologies to enhance the transparency, security, decentralization, and trustworthiness of AI systems. However, a comprehensive understanding of state-of-the-art DeAI development, particularly for active industry solutions, is still lacking. In this work, we present a Systematization of Knowledge (SoK) for blockchain-based DeAI solutions. We propose a taxonomy to classify existing DeAI protocols based on the model lifecycle. Based on this taxonomy, we provide a structured way to clarify the landscape of DeAI protocols and identify their similarities and differences. We analyze the functionalities of blockchain in DeAI, investigating how blockchain features contribute to enhancing the security, transparency, and trustworthiness of AI processes, while also ensuring fair incentives for AI data and model contributors. In addition, we identify key insights and research gaps in developing DeAI protocols, highlighting several critical avenues for future research.
CoxKAN: Kolmogorov-Arnold Networks for Interpretable, High-Performance Survival Analysis
Sep 06, 2024Survival analysis is a branch of statistics used for modeling the time until a specific event occurs and is widely used in medicine, engineering, finance, and many other fields. When choosing survival models, there is typically a trade-off between performance and interpretability, where the highest performance is achieved by black-box models based on deep learning. This is a major problem in fields such as medicine where practitioners are reluctant to blindly trust black-box models to make important patient decisions. Kolmogorov-Arnold Networks (KANs) were recently proposed as an interpretable and accurate alternative to multi-layer perceptrons (MLPs). We introduce CoxKAN, a Cox proportional hazards Kolmogorov-Arnold Network for interpretable, high-performance survival analysis. We evaluate the proposed CoxKAN on 4 synthetic datasets and 9 real medical datasets. The synthetic experiments demonstrate that CoxKAN accurately recovers interpretable symbolic formulae for the hazard function, and effectively performs automatic feature selection. Evaluation on the 9 real datasets show that CoxKAN consistently outperforms the Cox proportional hazards model and achieves performance that is superior or comparable to that of tuned MLPs. Furthermore, we find that CoxKAN identifies complex interactions between predictor variables that would be extremely difficult to recognise using existing survival methods, and automatically finds symbolic formulae which uncover the precise effect of important biomarkers on patient risk.
Decoding SEC Actions: Enforcement Trends through Analyzing Blockchain litigation using LLM-based Thematic Factor Mapping
Aug 21, 2024

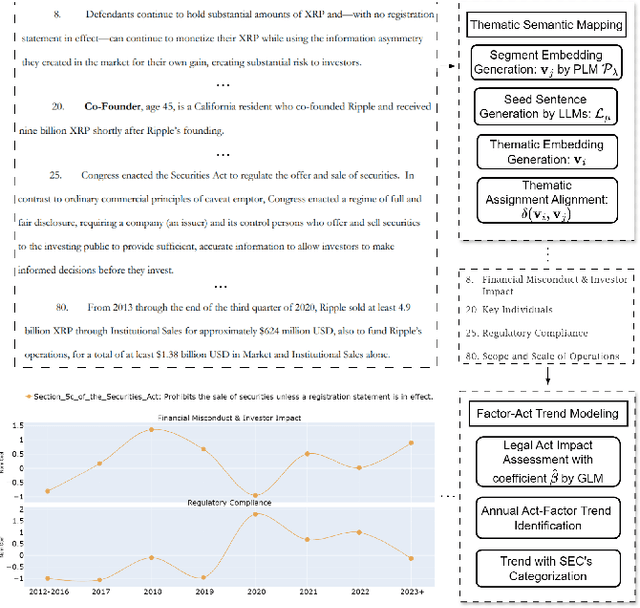

The proliferation of blockchain entities (persons or enterprises) exposes them to potential regulatory actions (e.g., being litigated) by regulatory authorities. Regulatory frameworks for crypto assets are actively being developed and refined, increasing the likelihood of such actions. The lack of systematic analysis of the factors driving litigation against blockchain entities leaves companies in need of clarity to navigate compliance risks. This absence of insight also deprives investors of the information for informed decision-making. This study focuses on U.S. litigation against blockchain entities, particularly by the U.S. Securities and Exchange Commission (SEC) given its influence on global crypto regulation. Utilizing frontier pretrained language models and large language models, we systematically map all SEC complaints against blockchain companies from 2012 to 2024 to thematic factors conceptualized by our study to delineate the factors driving SEC actions. We quantify the thematic factors and assess their influence on specific legal Acts cited within the complaints on an annual basis, allowing us to discern the regulatory emphasis, patterns and conduct trend analysis.
Offline Model-Based Reinforcement Learning with Anti-Exploration
Aug 20, 2024Model-based reinforcement learning (MBRL) algorithms learn a dynamics model from collected data and apply it to generate synthetic trajectories to enable faster learning. This is an especially promising paradigm in offline reinforcement learning (RL) where data may be limited in quantity, in addition to being deficient in coverage and quality. Practical approaches to offline MBRL usually rely on ensembles of dynamics models to prevent exploitation of any individual model and to extract uncertainty estimates that penalize values in states far from the dataset support. Uncertainty estimates from ensembles can vary greatly in scale, making it challenging to generalize hyperparameters well across even similar tasks. In this paper, we present Morse Model-based offline RL (MoMo), which extends the anti-exploration paradigm found in offline model-free RL to the model-based space. We develop model-free and model-based variants of MoMo and show how the model-free version can be extended to detect and deal with out-of-distribution (OOD) states using explicit uncertainty estimation without the need for large ensembles. MoMo performs offline MBRL using an anti-exploration bonus to counteract value overestimation in combination with a policy constraint, as well as a truncation function to terminate synthetic rollouts that are excessively OOD. Experimentally, we find that both model-free and model-based MoMo perform well, and the latter outperforms prior model-based and model-free baselines on the majority of D4RL datasets tested.
zkFL: Zero-Knowledge Proof-based Gradient Aggregation for Federated Learning
Oct 19, 2023Federated Learning (FL) is a machine learning paradigm, which enables multiple and decentralized clients to collaboratively train a model under the orchestration of a central aggregator. Traditional FL solutions rely on the trust assumption of the centralized aggregator, which forms cohorts of clients in a fair and honest manner. However, a malicious aggregator, in reality, could abandon and replace the client's training models, or launch Sybil attacks to insert fake clients. Such malicious behaviors give the aggregator more power to control clients in the FL setting and determine the final training results. In this work, we introduce zkFL, which leverages zero-knowledge proofs (ZKPs) to tackle the issue of a malicious aggregator during the training model aggregation process. To guarantee the correct aggregation results, the aggregator needs to provide a proof per round. The proof can demonstrate to the clients that the aggregator executes the intended behavior faithfully. To further reduce the verification cost of clients, we employ a blockchain to handle the proof in a zero-knowledge way, where miners (i.e., the nodes validating and maintaining the blockchain data) can verify the proof without knowing the clients' local and aggregated models. The theoretical analysis and empirical results show that zkFL can achieve better security and privacy than traditional FL, without modifying the underlying FL network structure or heavily compromising the training speed.
Defending Against Malicious Behaviors in Federated Learning with Blockchain
Jul 02, 2023



In the era of deep learning, federated learning (FL) presents a promising approach that allows multi-institutional data owners, or clients, to collaboratively train machine learning models without compromising data privacy. However, most existing FL approaches rely on a centralized server for global model aggregation, leading to a single point of failure. This makes the system vulnerable to malicious attacks when dealing with dishonest clients. In this work, we address this problem by proposing a secure and reliable FL system based on blockchain and distributed ledger technology. Our system incorporates a peer-to-peer voting mechanism and a reward-and-slash mechanism, which are powered by on-chain smart contracts, to detect and deter malicious behaviors. Both theoretical and empirical analyses are presented to demonstrate the effectiveness of the proposed approach, showing that our framework is robust against malicious client-side behaviors.
A Scalable Inference Method For Large Dynamic Economic Systems
Oct 27, 2021
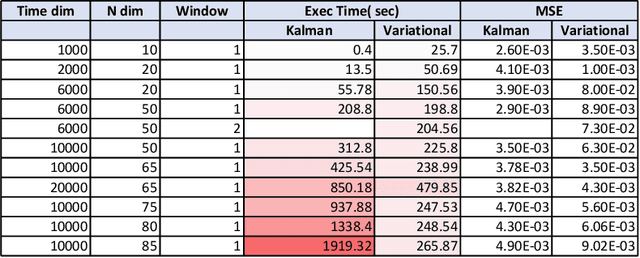
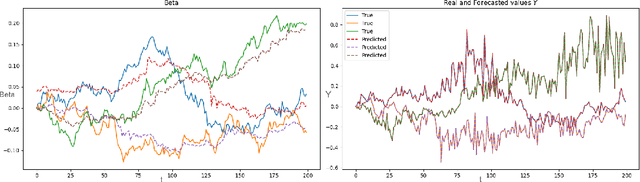
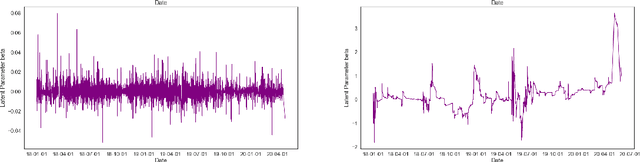
The nature of available economic data has changed fundamentally in the last decade due to the economy's digitisation. With the prevalence of often black box data-driven machine learning methods, there is a necessity to develop interpretable machine learning methods that can conduct econometric inference, helping policymakers leverage the new nature of economic data. We therefore present a novel Variational Bayesian Inference approach to incorporate a time-varying parameter auto-regressive model which is scalable for big data. Our model is applied to a large blockchain dataset containing prices, transactions of individual actors, analyzing transactional flows and price movements on a very granular level. The model is extendable to any dataset which can be modelled as a dynamical system. We further improve the simple state-space modelling by introducing non-linearities in the forward model with the help of machine learning architectures.
Neural NILM: Deep Neural Networks Applied to Energy Disaggregation
Sep 28, 2015
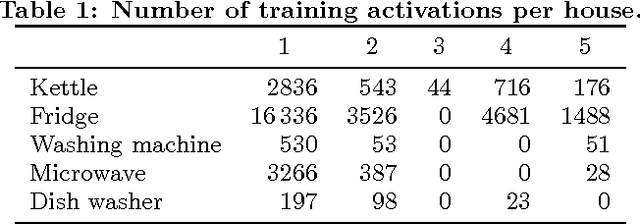

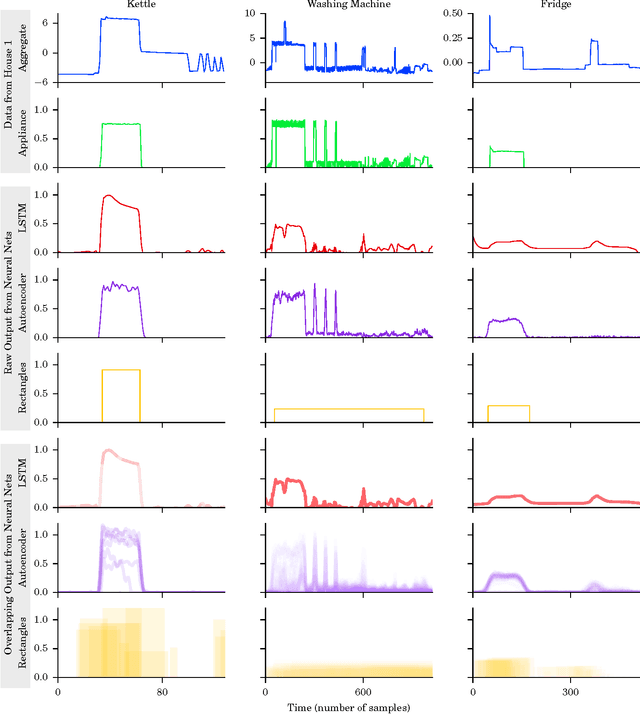
Energy disaggregation estimates appliance-by-appliance electricity consumption from a single meter that measures the whole home's electricity demand. Recently, deep neural networks have driven remarkable improvements in classification performance in neighbouring machine learning fields such as image classification and automatic speech recognition. In this paper, we adapt three deep neural network architectures to energy disaggregation: 1) a form of recurrent neural network called `long short-term memory' (LSTM); 2) denoising autoencoders; and 3) a network which regresses the start time, end time and average power demand of each appliance activation. We use seven metrics to test the performance of these algorithms on real aggregate power data from five appliances. Tests are performed against a house not seen during training and against houses seen during training. We find that all three neural nets achieve better F1 scores (averaged over all five appliances) than either combinatorial optimisation or factorial hidden Markov models and that our neural net algorithms generalise well to an unseen house.