 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProtoX-AD: Self-Explainable Time Series Anomaly Detection and Characterization
Jun 11, 2026Recent advances in time series anomaly detection (TSAD) have highlighted the effectiveness of self-supervised classification-based approaches. These methods apply transformations to normal training samples, training a classifier to recognize transformation-specific patterns that help identify anomalies through increased classification errors. Despite their strong performance, a significant challenge is their lack of explainability, as they provide limited insight into the characteristics of flagged anomalies. To address this limitation, we propose ProtoX-AD, a prototype-based self-explainable framework for self-supervised TSAD. ProtoX-AD learns transformation-aware latent representations alongside interpretable prototypes, enabling both accurate anomaly detection and the identification of distinct anomalous profiles through prototype-based explanations. Additionally, it allows for systematic analysis of how transformation design impacts detection performance and explainability. Experimental results on synthetic and real-world datasets demonstrate that ProtoX-AD achieves detection performance comparable to its black-box counterparts while offering more consistent and semantically meaningful explanations than existing explainable baselines. Our code is publicly available at https://github.com/Aitorzan3/ProtoX-AD.
AnyCrowd: Instance-Isolated Identity-Pose Binding for Arbitrary Multi-Character Animation
Mar 16, 2026Controllable character animation has advanced rapidly in recent years, yet multi-character animation remains underexplored. As the number of characters grows, multi-character reference encoding becomes more susceptible to latent identity entanglement, resulting in identity bleeding and reduced controllability. Moreover, learning precise and spatio-temporally consistent correspondences between reference identities and driving pose sequences becomes increasingly challenging, often leading to identity-pose mis-binding and inconsistency in generated videos. To address these challenges, we propose AnyCrowd, a Diffusion Transformer (DiT)-based video generation framework capable of scaling to an arbitrary number of characters. Specifically, we first introduce an Instance-Isolated Latent Representation (IILR), which encodes character instances independently prior to DiT processing to prevent latent identity entanglement. Building on this disentangled representation, we further propose Tri-Stage Decoupled Attention (TSDA) to bind identities to driving poses by decomposing self-attention into: (i) instance-aware foreground attention, (ii) background-centric interaction, and (iii) global foreground-background coordination. Furthermore, to mitigate token ambiguity in overlapping regions, an Adaptive Gated Fusion (AGF) module is integrated within TSDA to predict identity-aware weights, effectively fusing competing token groups into identity-consistent representations...
ERGO: Excess-Risk-Guided Optimization for High-Fidelity Monocular 3D Gaussian Splatting
Feb 10, 2026Generating 3D content from a single image remains a fundamentally challenging and ill-posed problem due to the inherent absence of geometric and textural information in occluded regions. While state-of-the-art generative models can synthesize auxiliary views to provide additional supervision, these views inevitably contain geometric inconsistencies and textural misalignments that propagate and amplify artifacts during 3D reconstruction. To effectively harness these imperfect supervisory signals, we propose an adaptive optimization framework guided by excess risk decomposition, termed ERGO. Specifically, ERGO decomposes the optimization losses in 3D Gaussian splatting into two components, i.e., excess risk that quantifies the suboptimality gap between current and optimal parameters, and Bayes error that models the irreducible noise inherent in synthesized views. This decomposition enables ERGO to dynamically estimate the view-specific excess risk and adaptively adjust loss weights during optimization. Furthermore, we introduce geometry-aware and texture-aware objectives that complement the excess-risk-derived weighting mechanism, establishing a synergistic global-local optimization paradigm. Consequently, ERGO demonstrates robustness against supervision noise while consistently enhancing both geometric fidelity and textural quality of the reconstructed 3D content. Extensive experiments on the Google Scanned Objects dataset and the OmniObject3D dataset demonstrate the superiority of ERGO over existing state-of-the-art methods.
THOR: A Versatile Foundation Model for Earth Observation Climate and Society Applications
Jan 22, 2026Current Earth observation foundation models are architecturally rigid, struggle with heterogeneous sensors and are constrained to fixed patch sizes. This limits their deployment in real-world scenarios requiring flexible computeaccuracy trade-offs. We propose THOR, a "computeadaptive" foundation model that solves both input heterogeneity and deployment rigidity. THOR is the first architecture to unify data from Copernicus Sentinel-1, -2, and -3 (OLCI & SLSTR) satellites, processing their native 10 m to 1000 m resolutions in a single model. We pre-train THOR with a novel randomized patch and input image size strategy. This allows a single set of pre-trained weights to be deployed at inference with any patch size, enabling a dynamic trade-off between computational cost and feature resolution without retraining. We pre-train THOR on THOR Pretrain, a new, large-scale multi-sensor dataset and demonstrate state-of-the-art performance on downstream benchmarks, particularly in data-limited regimes like the PANGAEA 10% split, validating that THOR's flexible feature generation excels for diverse climate and society applications.
Keypoint Counting Classifiers: Turning Vision Transformers into Self-Explainable Models Without Training
Dec 19, 2025
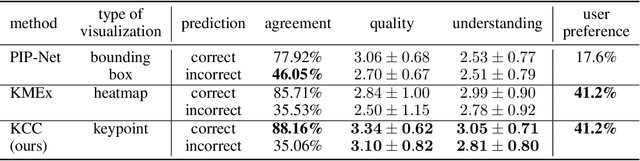

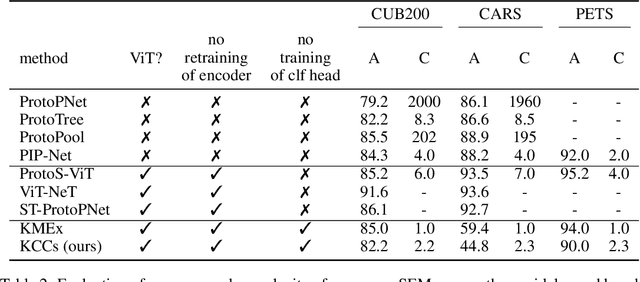
Current approaches for designing self-explainable models (SEMs) require complicated training procedures and specific architectures which makes them impractical. With the advance of general purpose foundation models based on Vision Transformers (ViTs), this impracticability becomes even more problematic. Therefore, new methods are necessary to provide transparency and reliability to ViT-based foundation models. In this work, we present a new method for turning any well-trained ViT-based model into a SEM without retraining, which we call Keypoint Counting Classifiers (KCCs). Recent works have shown that ViTs can automatically identify matching keypoints between images with high precision, and we build on these results to create an easily interpretable decision process that is inherently visualizable in the input. We perform an extensive evaluation which show that KCCs improve the human-machine communication compared to recent baselines. We believe that KCCs constitute an important step towards making ViT-based foundation models more transparent and reliable.
The Impact of Longitudinal Mammogram Alignment on Breast Cancer Risk Assessment
Nov 11, 2025Regular mammography screening is crucial for early breast cancer detection. By leveraging deep learning-based risk models, screening intervals can be personalized, especially for high-risk individuals. While recent methods increasingly incorporate longitudinal information from prior mammograms, accurate spatial alignment across time points remains a key challenge. Misalignment can obscure meaningful tissue changes and degrade model performance. In this study, we provide insights into various alignment strategies, image-based registration, feature-level (representation space) alignment with and without regularization, and implicit alignment methods, for their effectiveness in longitudinal deep learning-based risk modeling. Using two large-scale mammography datasets, we assess each method across key metrics, including predictive accuracy, precision, recall, and deformation field quality. Our results show that image-based registration consistently outperforms the more recently favored feature-based and implicit approaches across all metrics, enabling more accurate, temporally consistent predictions and generating smooth, anatomically plausible deformation fields. Although regularizing the deformation field improves deformation quality, it reduces the risk prediction performance of feature-level alignment. Applying image-based deformation fields within the feature space yields the best risk prediction performance. These findings underscore the importance of image-based deformation fields for spatial alignment in longitudinal risk modeling, offering improved prediction accuracy and robustness. This approach has strong potential to enhance personalized screening and enable earlier interventions for high-risk individuals. The code is available at https://github.com/sot176/Mammogram_Alignment_Study_Risk_Prediction.git, allowing full reproducibility of the results.
ProPy: Building Interactive Prompt Pyramids upon CLIP for Partially Relevant Video Retrieval
Aug 26, 2025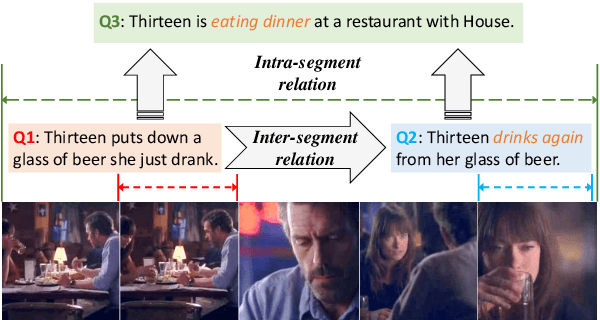

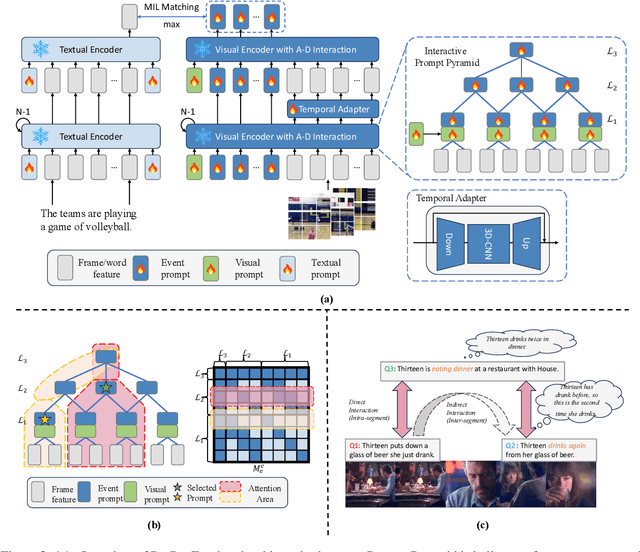
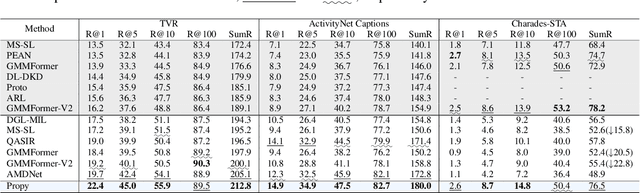
Partially Relevant Video Retrieval (PRVR) is a practical yet challenging task that involves retrieving videos based on queries relevant to only specific segments. While existing works follow the paradigm of developing models to process unimodal features, powerful pretrained vision-language models like CLIP remain underexplored in this field. To bridge this gap, we propose ProPy, a model with systematic architectural adaption of CLIP specifically designed for PRVR. Drawing insights from the semantic relevance of multi-granularity events, ProPy introduces two key innovations: (1) A Prompt Pyramid structure that organizes event prompts to capture semantics at multiple granularity levels, and (2) An Ancestor-Descendant Interaction Mechanism built on the pyramid that enables dynamic semantic interaction among events. With these designs, ProPy achieves SOTA performance on three public datasets, outperforming previous models by significant margins. Code is available at https://github.com/BUAAPY/ProPy.
A robust and versatile deep learning model for prediction of the arterial input function in dynamic small animal $\left[^{18}\text{F}\right]$FDG PET imaging
Jul 03, 2025![Figure 1 for A robust and versatile deep learning model for prediction of the arterial input function in dynamic small animal $\left[^{18}\text{F}\right]$FDG PET imaging](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2Faeedac3751b9e214478a1237ed9043e09178057f%2F5-Figure1-1.png&w=640&q=75)
![Figure 2 for A robust and versatile deep learning model for prediction of the arterial input function in dynamic small animal $\left[^{18}\text{F}\right]$FDG PET imaging](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2Faeedac3751b9e214478a1237ed9043e09178057f%2F6-Figure2-1.png&w=640&q=75)
![Figure 3 for A robust and versatile deep learning model for prediction of the arterial input function in dynamic small animal $\left[^{18}\text{F}\right]$FDG PET imaging](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2Faeedac3751b9e214478a1237ed9043e09178057f%2F7-Figure3-1.png&w=640&q=75)
![Figure 4 for A robust and versatile deep learning model for prediction of the arterial input function in dynamic small animal $\left[^{18}\text{F}\right]$FDG PET imaging](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2Faeedac3751b9e214478a1237ed9043e09178057f%2F9-Figure4-1.png&w=640&q=75)
Dynamic positron emission tomography (PET) and kinetic modeling are pivotal in advancing tracer development research in small animal studies. Accurate kinetic modeling requires precise input function estimation, traditionally achieved via arterial blood sampling. However, arterial cannulation in small animals like mice, involves intricate, time-consuming, and terminal procedures, precluding longitudinal studies. This work proposes a non-invasive, fully convolutional deep learning-based approach (FC-DLIF) to predict input functions directly from PET imaging, potentially eliminating the need for blood sampling in dynamic small-animal PET. The proposed FC-DLIF model includes a spatial feature extractor acting on the volumetric time frames of the PET sequence, extracting spatial features. These are subsequently further processed in a temporal feature extractor that predicts the arterial input function. The proposed approach is trained and evaluated using images and arterial blood curves from [$^{18}$F]FDG data using cross validation. Further, the model applicability is evaluated on imaging data and arterial blood curves collected using two additional radiotracers ([$^{18}$F]FDOPA, and [$^{68}$Ga]PSMA). The model was further evaluated on data truncated and shifted in time, to simulate shorter, and shifted, PET scans. The proposed FC-DLIF model reliably predicts the arterial input function with respect to mean squared error and correlation. Furthermore, the FC-DLIF model is able to predict the arterial input function even from truncated and shifted samples. The model fails to predict the AIF from samples collected using different radiotracers, as these are not represented in the training data. Our deep learning-based input function offers a non-invasive and reliable alternative to arterial blood sampling, proving robust and flexible to temporal shifts and different scan durations.
Reconsidering Explicit Longitudinal Mammography Alignment for Enhanced Breast Cancer Risk Prediction
Jun 24, 2025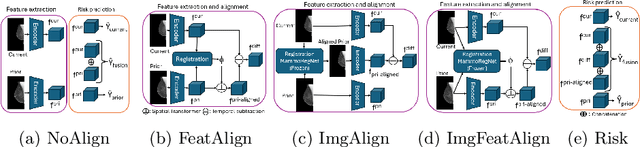
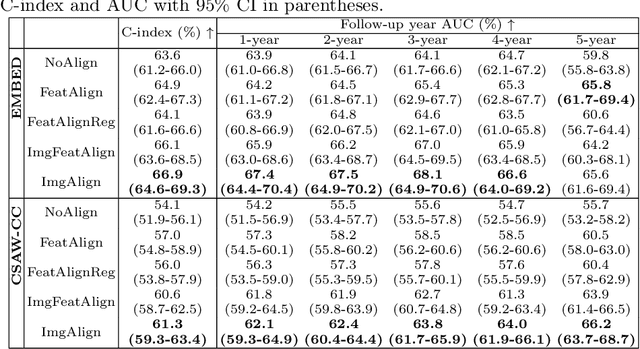
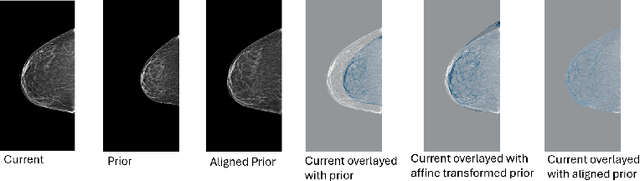

Regular mammography screening is essential for early breast cancer detection. Deep learning-based risk prediction methods have sparked interest to adjust screening intervals for high-risk groups. While early methods focused only on current mammograms, recent approaches leverage the temporal aspect of screenings to track breast tissue changes over time, requiring spatial alignment across different time points. Two main strategies for this have emerged: explicit feature alignment through deformable registration and implicit learned alignment using techniques like transformers, with the former providing more control. However, the optimal approach for explicit alignment in mammography remains underexplored. In this study, we provide insights into where explicit alignment should occur (input space vs. representation space) and if alignment and risk prediction should be jointly optimized. We demonstrate that jointly learning explicit alignment in representation space while optimizing risk estimation performance, as done in the current state-of-the-art approach, results in a trade-off between alignment quality and predictive performance and show that image-level alignment is superior to representation-level alignment, leading to better deformation field quality and enhanced risk prediction accuracy. The code is available at https://github.com/sot176/Longitudinal_Mammogram_Alignment.git.
DiffFuSR: Super-Resolution of all Sentinel-2 Multispectral Bands using Diffusion Models
Jun 13, 2025This paper presents DiffFuSR, a modular pipeline for super-resolving all 12 spectral bands of Sentinel-2 Level-2A imagery to a unified ground sampling distance (GSD) of 2.5 meters. The pipeline comprises two stages: (i) a diffusion-based super-resolution (SR) model trained on high-resolution RGB imagery from the NAIP and WorldStrat datasets, harmonized to simulate Sentinel-2 characteristics; and (ii) a learned fusion network that upscales the remaining multispectral bands using the super-resolved RGB image as a spatial prior. We introduce a robust degradation model and contrastive degradation encoder to support blind SR. Extensive evaluations of the proposed SR pipeline on the OpenSR benchmark demonstrate that the proposed method outperforms current SOTA baselines in terms of reflectance fidelity, spectral consistency, spatial alignment, and hallucination suppression. Furthermore, the fusion network significantly outperforms classical pansharpening approaches, enabling accurate enhancement of Sentinel-2's 20 m and 60 m bands. This study underscores the power of harmonized learning with generative priors and fusion strategies to create a modular framework for Sentinel-2 SR. Our code and models can be found at https://github.com/NorskRegnesentral/DiffFuSR.