 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTHOR: A Versatile Foundation Model for Earth Observation Climate and Society Applications
Jan 22, 2026Current Earth observation foundation models are architecturally rigid, struggle with heterogeneous sensors and are constrained to fixed patch sizes. This limits their deployment in real-world scenarios requiring flexible computeaccuracy trade-offs. We propose THOR, a "computeadaptive" foundation model that solves both input heterogeneity and deployment rigidity. THOR is the first architecture to unify data from Copernicus Sentinel-1, -2, and -3 (OLCI & SLSTR) satellites, processing their native 10 m to 1000 m resolutions in a single model. We pre-train THOR with a novel randomized patch and input image size strategy. This allows a single set of pre-trained weights to be deployed at inference with any patch size, enabling a dynamic trade-off between computational cost and feature resolution without retraining. We pre-train THOR on THOR Pretrain, a new, large-scale multi-sensor dataset and demonstrate state-of-the-art performance on downstream benchmarks, particularly in data-limited regimes like the PANGAEA 10% split, validating that THOR's flexible feature generation excels for diverse climate and society applications.
DiffFuSR: Super-Resolution of all Sentinel-2 Multispectral Bands using Diffusion Models
Jun 13, 2025This paper presents DiffFuSR, a modular pipeline for super-resolving all 12 spectral bands of Sentinel-2 Level-2A imagery to a unified ground sampling distance (GSD) of 2.5 meters. The pipeline comprises two stages: (i) a diffusion-based super-resolution (SR) model trained on high-resolution RGB imagery from the NAIP and WorldStrat datasets, harmonized to simulate Sentinel-2 characteristics; and (ii) a learned fusion network that upscales the remaining multispectral bands using the super-resolved RGB image as a spatial prior. We introduce a robust degradation model and contrastive degradation encoder to support blind SR. Extensive evaluations of the proposed SR pipeline on the OpenSR benchmark demonstrate that the proposed method outperforms current SOTA baselines in terms of reflectance fidelity, spectral consistency, spatial alignment, and hallucination suppression. Furthermore, the fusion network significantly outperforms classical pansharpening approaches, enabling accurate enhancement of Sentinel-2's 20 m and 60 m bands. This study underscores the power of harmonized learning with generative priors and fusion strategies to create a modular framework for Sentinel-2 SR. Our code and models can be found at https://github.com/NorskRegnesentral/DiffFuSR.
Uncertainties of Satellite-based Essential Climate Variables from Deep Learning
Dec 23, 2024Accurate uncertainty information associated with essential climate variables (ECVs) is crucial for reliable climate modeling and understanding the spatiotemporal evolution of the Earth system. In recent years, geoscience and climate scientists have benefited from rapid progress in deep learning to advance the estimation of ECV products with improved accuracy. However, the quantification of uncertainties associated with the output of such deep learning models has yet to be thoroughly adopted. This survey explores the types of uncertainties associated with ECVs estimated from deep learning and the techniques to quantify them. The focus is on highlighting the importance of quantifying uncertainties inherent in ECV estimates, considering the dynamic and multifaceted nature of climate data. The survey starts by clarifying the definition of aleatoric and epistemic uncertainties and their roles in a typical satellite observation processing workflow, followed by bridging the gap between conventional statistical and deep learning views on uncertainties. Then, we comprehensively review the existing techniques for quantifying uncertainties associated with deep learning algorithms, focusing on their application in ECV studies. The specific need for modification to fit the requirements from both the Earth observation side and the deep learning side in such interdisciplinary tasks is discussed. Finally, we demonstrate our findings with two ECV examples, snow cover and terrestrial water storage, and provide our perspectives for future research.
Multi-modal land cover mapping of remote sensing images using pyramid attention and gated fusion networks
Nov 06, 2021

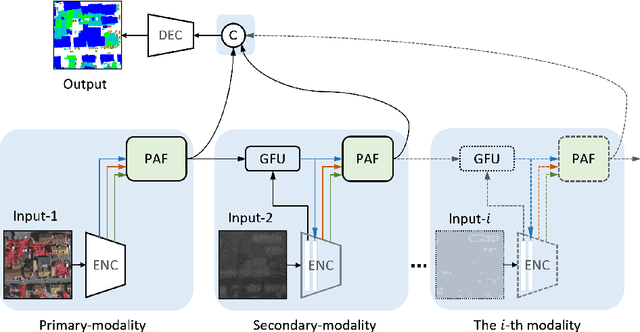
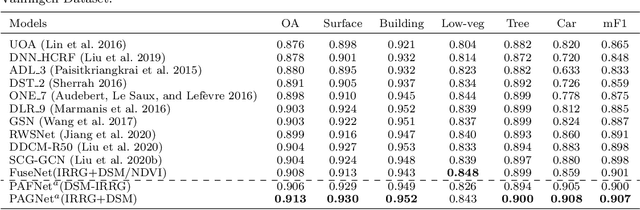
Multi-modality data is becoming readily available in remote sensing (RS) and can provide complementary information about the Earth's surface. Effective fusion of multi-modal information is thus important for various applications in RS, but also very challenging due to large domain differences, noise, and redundancies. There is a lack of effective and scalable fusion techniques for bridging multiple modality encoders and fully exploiting complementary information. To this end, we propose a new multi-modality network (MultiModNet) for land cover mapping of multi-modal remote sensing data based on a novel pyramid attention fusion (PAF) module and a gated fusion unit (GFU). The PAF module is designed to efficiently obtain rich fine-grained contextual representations from each modality with a built-in cross-level and cross-view attention fusion mechanism, and the GFU module utilizes a novel gating mechanism for early merging of features, thereby diminishing hidden redundancies and noise. This enables supplementary modalities to effectively extract the most valuable and complementary information for late feature fusion. Extensive experiments on two representative RS benchmark datasets demonstrate the effectiveness, robustness, and superiority of the MultiModNet for multi-modal land cover classification.
SCG-Net: Self-Constructing Graph Neural Networks for Semantic Segmentation
Sep 03, 2020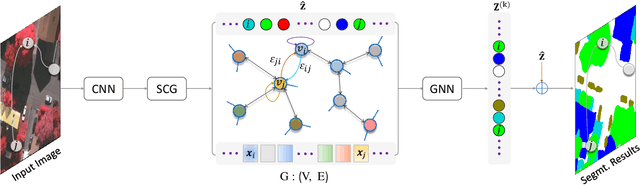
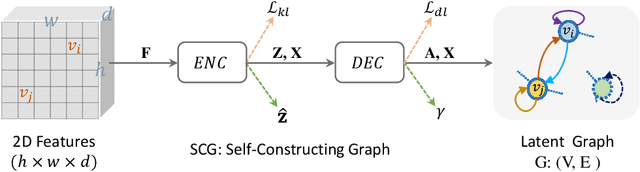
Capturing global contextual representations by exploiting long-range pixel-pixel dependencies has shown to improve semantic segmentation performance. However, how to do this efficiently is an open question as current approaches of utilising attention schemes or very deep models to increase the models field of view, result in complex models with large memory consumption. Inspired by recent work on graph neural networks, we propose the Self-Constructing Graph (SCG) module that learns a long-range dependency graph directly from the image and uses it to propagate contextual information efficiently to improve semantic segmentation. The module is optimised via a novel adaptive diagonal enhancement method and a variational lower bound that consists of a customized graph reconstruction term and a Kullback-Leibler divergence regularization term. When incorporated into a neural network (SCG-Net), semantic segmentation is performed in an end-to-end manner and competitive performance (mean F1-scores of 92.0% and 89.8% respectively) on the publicly available ISPRS Potsdam and Vaihingen datasets is achieved, with much fewer parameters, and at a lower computational cost compared to related pure convolutional neural network (CNN) based models.
Self-Constructing Graph Convolutional Networks for Semantic Labeling
Apr 23, 2020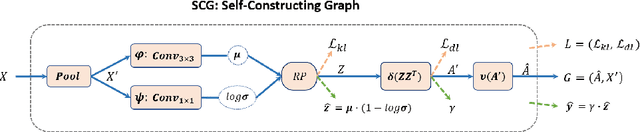
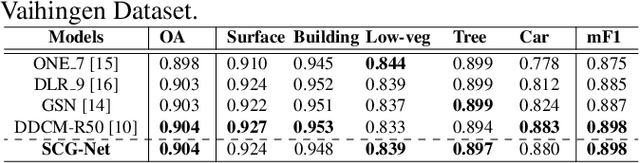
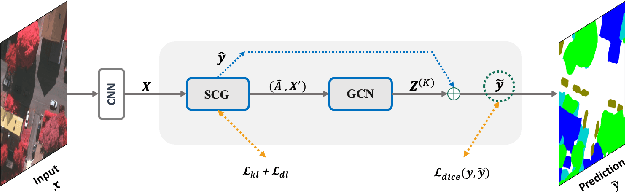
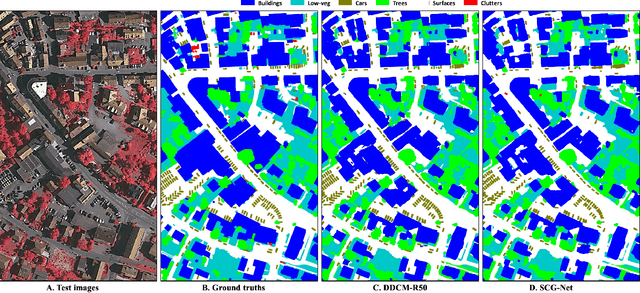
Graph Neural Networks (GNNs) have received increasing attention in many fields. However, due to the lack of prior graphs, their use for semantic labeling has been limited. Here, we propose a novel architecture called the Self-Constructing Graph (SCG), which makes use of learnable latent variables to generate embeddings and to self-construct the underlying graphs directly from the input features without relying on manually built prior knowledge graphs. SCG can automatically obtain optimized non-local context graphs from complex-shaped objects in aerial imagery. We optimize SCG via an adaptive diagonal enhancement method and a variational lower bound that consists of a customized graph reconstruction term and a Kullback-Leibler divergence regularization term. We demonstrate the effectiveness and flexibility of the proposed SCG on the publicly available ISPRS Vaihingen dataset and our model SCG-Net achieves competitive results in terms of F1-score with much fewer parameters and at a lower computational cost compared to related pure-CNN based work. Our code will be made public soon.
Multi-view Self-Constructing Graph Convolutional Networks with Adaptive Class Weighting Loss for Semantic Segmentation
Apr 21, 2020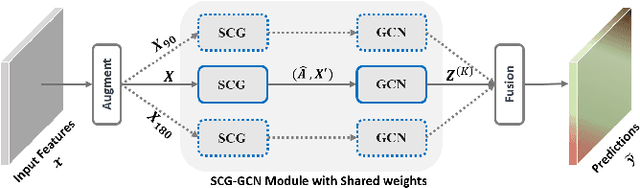
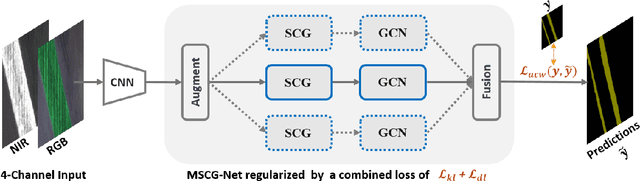


We propose a novel architecture called the Multi-view Self-Constructing Graph Convolutional Networks (MSCG-Net) for semantic segmentation. Building on the recently proposed Self-Constructing Graph (SCG) module, which makes use of learnable latent variables to self-construct the underlying graphs directly from the input features without relying on manually built prior knowledge graphs, we leverage multiple views in order to explicitly exploit the rotational invariance in airborne images. We further develop an adaptive class weighting loss to address the class imbalance. We demonstrate the effectiveness and flexibility of the proposed method on the Agriculture-Vision challenge dataset and our model achieves very competitive results (0.547 mIoU) with much fewer parameters and at a lower computational cost compared to related pure-CNN based work. Code will be available at: github.com/samleoqh/MSCG-Net
Dense Dilated Convolutions Merging Network for Land Cover Classification
Mar 09, 2020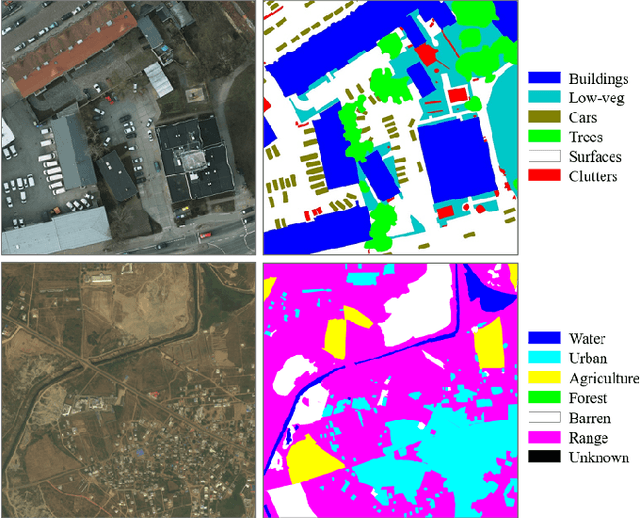
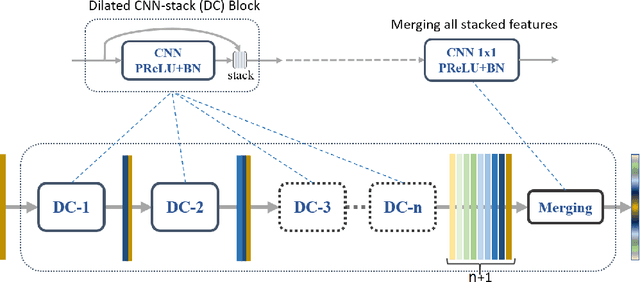
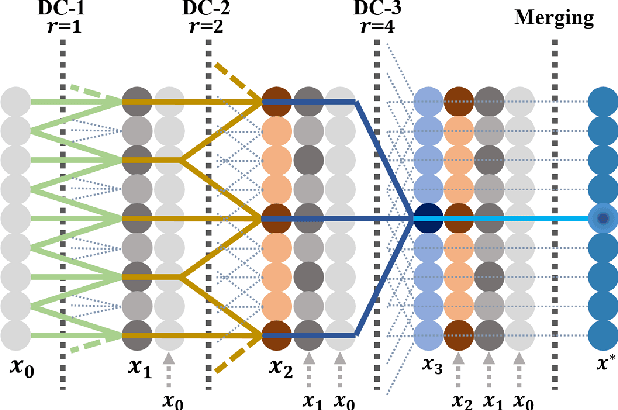
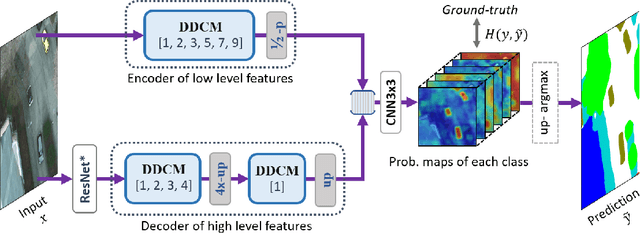
Land cover classification of remote sensing images is a challenging task due to limited amounts of annotated data, highly imbalanced classes, frequent incorrect pixel-level annotations, and an inherent complexity in the semantic segmentation task. In this article, we propose a novel architecture called the dense dilated convolutions' merging network (DDCM-Net) to address this task. The proposed DDCM-Net consists of dense dilated image convolutions merged with varying dilation rates. This effectively utilizes rich combinations of dilated convolutions that enlarge the network's receptive fields with fewer parameters and features compared with the state-of-the-art approaches in the remote sensing domain. Importantly, DDCM-Net obtains fused local- and global-context information, in effect incorporating surrounding discriminative capability for multiscale and complex-shaped objects with similar color and textures in very high-resolution aerial imagery. We demonstrate the effectiveness, robustness, and flexibility of the proposed DDCM-Net on the publicly available ISPRS Potsdam and Vaihingen data sets, as well as the DeepGlobe land cover data set. Our single model, trained on three-band Potsdam and Vaihingen data sets, achieves better accuracy in terms of both mean intersection over union (mIoU) and F1-score compared with other published models trained with more than three-band data. We further validate our model on the DeepGlobe data set, achieving state-of-the-art result 56.2% mIoU with much fewer parameters and at a lower computational cost compared with related recent work. Code available at https://github.com/samleoqh/DDCM-Semantic-Segmentation-PyTorch
Road Mapping In LiDAR Images Using A Joint-Task Dense Dilated Convolutions Merging Network
Sep 07, 2019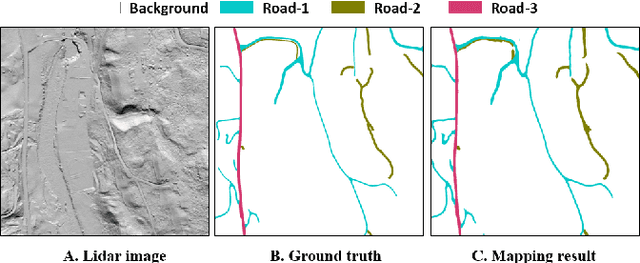
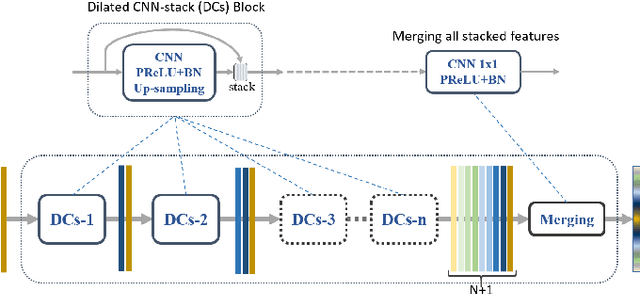
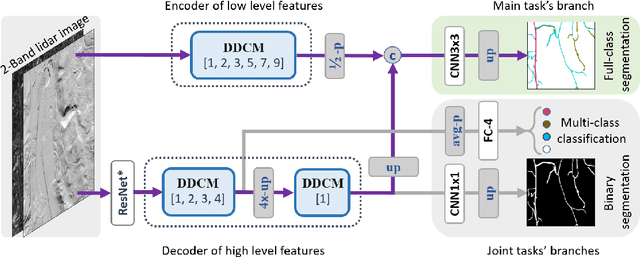
It is important, but challenging, for the forest industry to accurately map roads which are used for timber transport by trucks. In this work, we propose a Dense Dilated Convolutions Merging Network (DDCM-Net) to detect these roads in lidar images. The DDCM-Net can effectively recognize multi-scale and complex shaped roads with similar texture and colors, and also is shown to have superior performance over existing methods. To further improve its ability to accurately infer categories of roads, we propose the use of a joint-task learning strategy that utilizes two auxiliary output branches, i.e, multi-class classification and binary segmentation, joined with the main output of full-class segmentation. This pushes the network towards learning more robust representations that are expected to boost the ultimate performance of the main task. In addition, we introduce an iterative-random-weighting method to automatically weigh the joint losses for auxiliary tasks. This can avoid the difficult and expensive process of tuning the weights of each task's loss by hand. The experiments demonstrate that our proposed joint-task DDCM-Net can achieve better performance with fewer parameters and higher computational efficiency than previous state-of-the-art approaches.
Dense Dilated Convolutions Merging Network for Semantic Mapping of Remote Sensing Images
Aug 30, 2019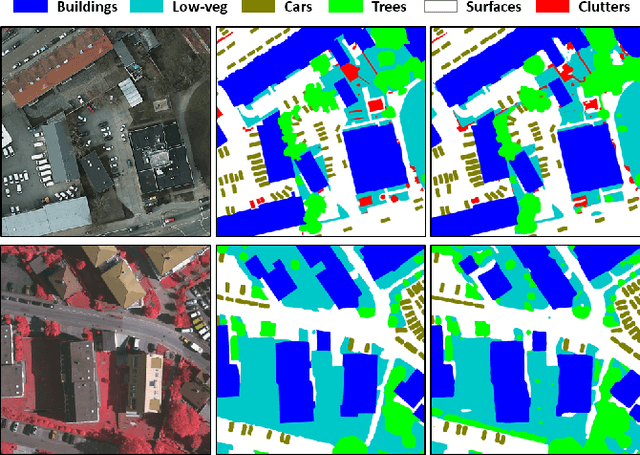
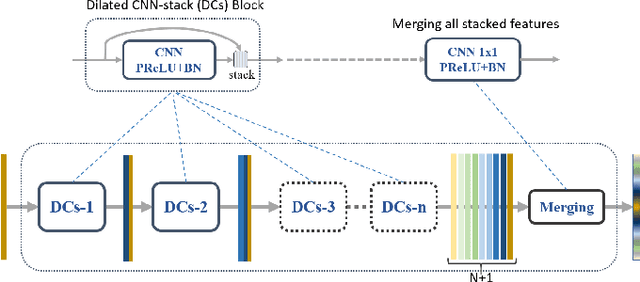
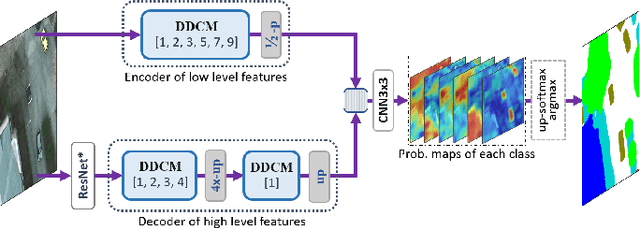

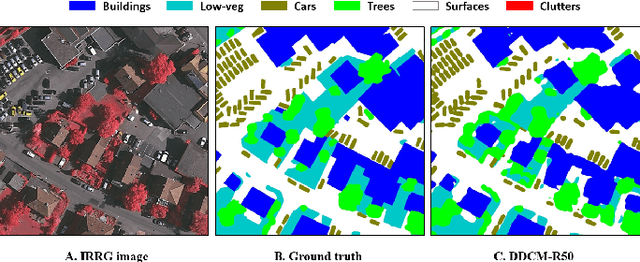
We propose a network for semantic mapping called the Dense Dilated Convolutions Merging Network (DDCM-Net) to provide a deep learning approach that can recognize multi-scale and complex shaped objects with similar color and textures, such as buildings, surfaces/roads, and trees in very high resolution remote sensing images. The proposed DDCM-Net consists of dense dilated convolutions merged with varying dilation rates. This can effectively enlarge the kernels' receptive fields, and, more importantly, obtain fused local and global context information to promote surrounding discriminative capability. We demonstrate the effectiveness of the proposed DDCM-Net on the publicly available ISPRS Potsdam dataset and achieve a performance of 92.3% F1-score and 86.0% mean intersection over union accuracy by only using the RGB bands, without any post-processing. We also show results on the ISPRS Vaihingen dataset, where the DDCM-Net trained with IRRG bands, also obtained better mapping accuracy (89.8% F1-score) than previous state-of-the-art approaches.