 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExamining Deployment and Refinement of the VIOLA-AI Intracranial Hemorrhage Model Using an Interactive NeoMedSys Platform
May 14, 2025Background: There are many challenges and opportunities in the clinical deployment of AI tools in radiology. The current study describes a radiology software platform called NeoMedSys that can enable efficient deployment and refinements of AI models. We evaluated the feasibility and effectiveness of running NeoMedSys for three months in real-world clinical settings and focused on improvement performance of an in-house developed AI model (VIOLA-AI) designed for intracranial hemorrhage (ICH) detection. Methods: NeoMedSys integrates tools for deploying, testing, and optimizing AI models with a web-based medical image viewer, annotation system, and hospital-wide radiology information systems. A pragmatic investigation was deployed using clinical cases of patients presenting to the largest Emergency Department in Norway (site-1) with suspected traumatic brain injury (TBI) or patients with suspected stroke (site-2). We assessed ICH classification performance as VIOLA-AI encountered new data and underwent pre-planned model retraining. Performance metrics included sensitivity, specificity, accuracy, and the area under the receiver operating characteristic curve (AUC). Results: NeoMedSys facilitated iterative improvements in the AI model, significantly enhancing its diagnostic accuracy. Automated bleed detection and segmentation were reviewed in near real-time to facilitate re-training VIOLA-AI. The iterative refinement process yielded a marked improvement in classification sensitivity, rising to 90.3% (from 79.2%), and specificity that reached 89.3% (from 80.7%). The bleed detection ROC analysis for the entire sample demonstrated a high area-under-the-curve (AUC) of 0.949 (from 0.873). Model refinement stages were associated with notable gains, highlighting the value of real-time radiologist feedback.
Treatment-aware Diffusion Probabilistic Model for Longitudinal MRI Generation and Diffuse Glioma Growth Prediction
Sep 14, 2023



Diffuse gliomas are malignant brain tumors that grow widespread through the brain. The complex interactions between neoplastic cells and normal tissue, as well as the treatment-induced changes often encountered, make glioma tumor growth modeling challenging. In this paper, we present a novel end-to-end network capable of generating future tumor masks and realistic MRIs of how the tumor will look at any future time points for different treatment plans. Our approach is based on cutting-edge diffusion probabilistic models and deep-segmentation neural networks. We included sequential multi-parametric magnetic resonance images (MRI) and treatment information as conditioning inputs to guide the generative diffusion process. This allows for tumor growth estimates at any given time point. We trained the model using real-world postoperative longitudinal MRI data with glioma tumor growth trajectories represented as tumor segmentation maps over time. The model has demonstrated promising performance across a range of tasks, including the generation of high-quality synthetic MRIs with tumor masks, time-series tumor segmentations, and uncertainty estimates. Combined with the treatment-aware generated MRIs, the tumor growth predictions with uncertainty estimates can provide useful information for clinical decision-making.
The state-of-the-art 3D anisotropic intracranial hemorrhage segmentation on non-contrast head CT: The INSTANCE challenge
Jan 12, 2023Automatic intracranial hemorrhage segmentation in 3D non-contrast head CT (NCCT) scans is significant in clinical practice. Existing hemorrhage segmentation methods usually ignores the anisotropic nature of the NCCT, and are evaluated on different in-house datasets with distinct metrics, making it highly challenging to improve segmentation performance and perform objective comparisons among different methods. The INSTANCE 2022 was a grand challenge held in conjunction with the 2022 International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI). It is intended to resolve the above-mentioned problems and promote the development of both intracranial hemorrhage segmentation and anisotropic data processing. The INSTANCE released a training set of 100 cases with ground-truth and a validation set with 30 cases without ground-truth labels that were available to the participants. A held-out testing set with 70 cases is utilized for the final evaluation and ranking. The methods from different participants are ranked based on four metrics, including Dice Similarity Coefficient (DSC), Hausdorff Distance (HD), Relative Volume Difference (RVD) and Normalized Surface Dice (NSD). A total of 13 teams submitted distinct solutions to resolve the challenges, making several baseline models, pre-processing strategies and anisotropic data processing techniques available to future researchers. The winner method achieved an average DSC of 0.6925, demonstrating a significant growth over our proposed baseline method. To the best of our knowledge, the proposed INSTANCE challenge releases the first intracranial hemorrhage segmentation benchmark, and is also the first challenge that intended to resolve the anisotropic problem in 3D medical image segmentation, which provides new alternatives in these research fields.
Voxels Intersecting along Orthogonal Levels Attention U-Net (viola-Unet) to Segment Intracerebral Haemorrhage Using Computed Tomography Head Scans
Aug 12, 2022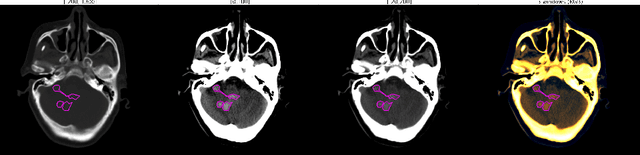

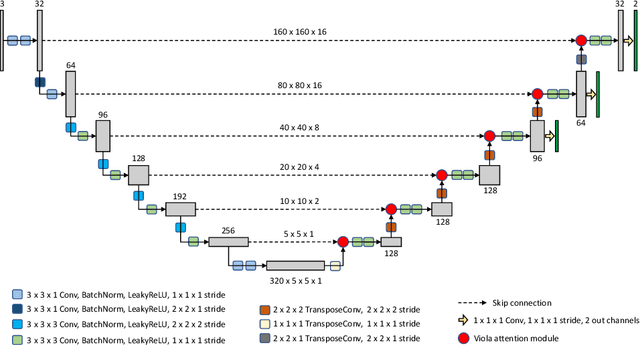

We implemented two distinct 3-dimensional deep learning neural networks and evaluate their ability to segment intracranial hemorrhage (ICH) seen on non-contrast computed tomography (CT). One model, referred to as "Voxels-Intersecting along Orthogonal Levels of Attention U-Net" (viola-Unet), has architecture elements that are amenable to the INSTANCE 2022 Data Challenge. A second comparison model was derived from the no-new U-Net (nnU-Net). Input images and ground truth segmentation maps were used to train the two networks separately in supervised manner; validation data were subsequently used for semi-supervised training. Model predictions were compared during 5-fold cross validation. The viola-Unet outperformed the comparison network on two out of four performance metrics (i.e., NSD and RVD). An ensemble model that combined viola-Unet and nnU-Net networks had the highest performance for DSC and HD. We demonstrate there were ICH segmentation performance benefits associated with a 3D U-Net efficiently incorporates spatially orthogonal features during the decoding branch of the U-Net. The code base, pretrained weights, and docker image of the viola-Unet AI tool will be publicly available at https://github.com/samleoqh/Viola-Unet .
Multi-modal land cover mapping of remote sensing images using pyramid attention and gated fusion networks
Nov 06, 2021

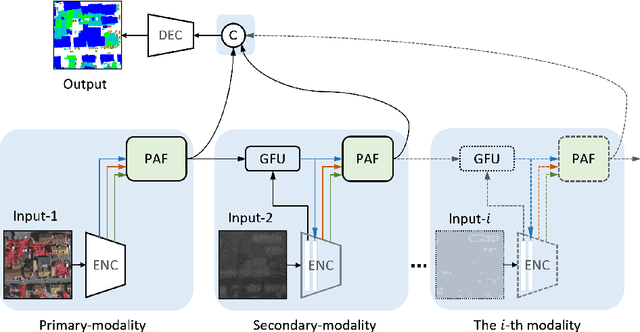
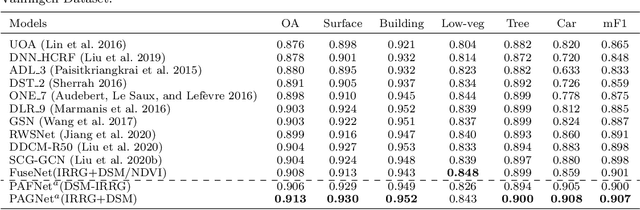
Multi-modality data is becoming readily available in remote sensing (RS) and can provide complementary information about the Earth's surface. Effective fusion of multi-modal information is thus important for various applications in RS, but also very challenging due to large domain differences, noise, and redundancies. There is a lack of effective and scalable fusion techniques for bridging multiple modality encoders and fully exploiting complementary information. To this end, we propose a new multi-modality network (MultiModNet) for land cover mapping of multi-modal remote sensing data based on a novel pyramid attention fusion (PAF) module and a gated fusion unit (GFU). The PAF module is designed to efficiently obtain rich fine-grained contextual representations from each modality with a built-in cross-level and cross-view attention fusion mechanism, and the GFU module utilizes a novel gating mechanism for early merging of features, thereby diminishing hidden redundancies and noise. This enables supplementary modalities to effectively extract the most valuable and complementary information for late feature fusion. Extensive experiments on two representative RS benchmark datasets demonstrate the effectiveness, robustness, and superiority of the MultiModNet for multi-modal land cover classification.
SCG-Net: Self-Constructing Graph Neural Networks for Semantic Segmentation
Sep 03, 2020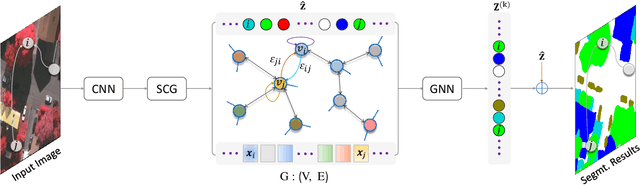
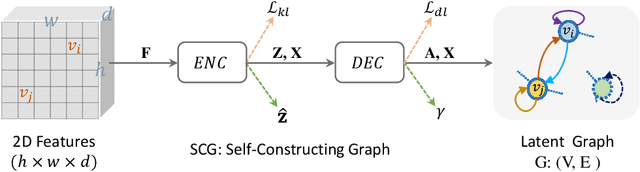
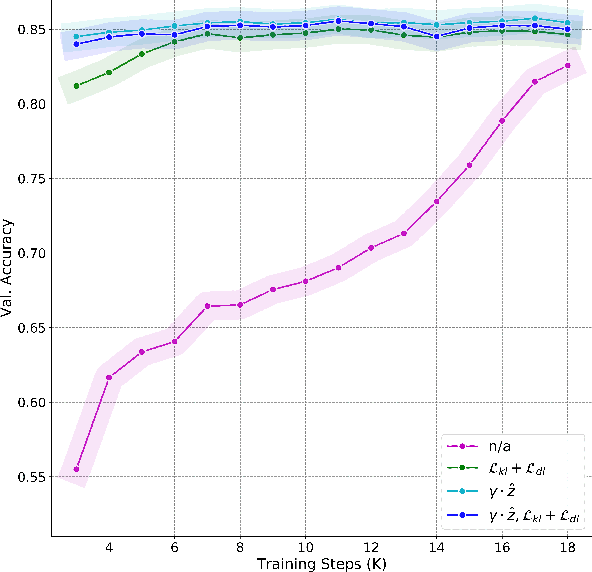
Capturing global contextual representations by exploiting long-range pixel-pixel dependencies has shown to improve semantic segmentation performance. However, how to do this efficiently is an open question as current approaches of utilising attention schemes or very deep models to increase the models field of view, result in complex models with large memory consumption. Inspired by recent work on graph neural networks, we propose the Self-Constructing Graph (SCG) module that learns a long-range dependency graph directly from the image and uses it to propagate contextual information efficiently to improve semantic segmentation. The module is optimised via a novel adaptive diagonal enhancement method and a variational lower bound that consists of a customized graph reconstruction term and a Kullback-Leibler divergence regularization term. When incorporated into a neural network (SCG-Net), semantic segmentation is performed in an end-to-end manner and competitive performance (mean F1-scores of 92.0% and 89.8% respectively) on the publicly available ISPRS Potsdam and Vaihingen datasets is achieved, with much fewer parameters, and at a lower computational cost compared to related pure convolutional neural network (CNN) based models.
The 1st Agriculture-Vision Challenge: Methods and Results
Apr 23, 2020
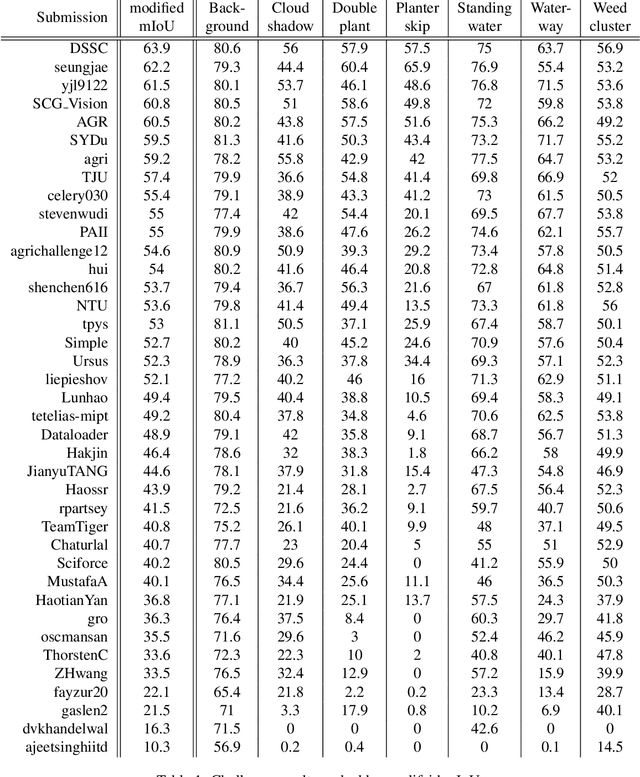
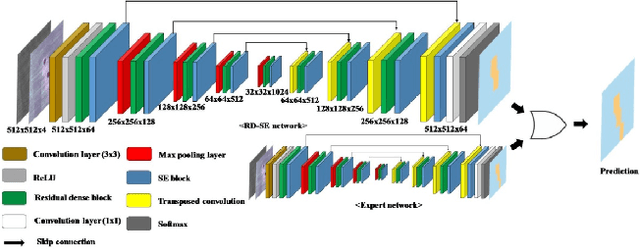
The first Agriculture-Vision Challenge aims to encourage research in developing novel and effective algorithms for agricultural pattern recognition from aerial images, especially for the semantic segmentation task associated with our challenge dataset. Around 57 participating teams from various countries compete to achieve state-of-the-art in aerial agriculture semantic segmentation. The Agriculture-Vision Challenge Dataset was employed, which comprises of 21,061 aerial and multi-spectral farmland images. This paper provides a summary of notable methods and results in the challenge. Our submission server and leaderboard will continue to open for researchers that are interested in this challenge dataset and task; the link can be found here.
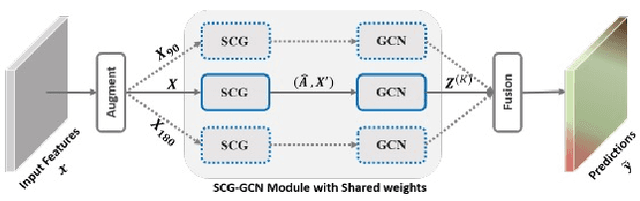
Self-Constructing Graph Convolutional Networks for Semantic Labeling
Apr 23, 2020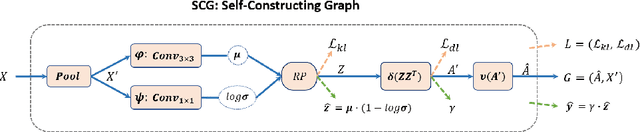
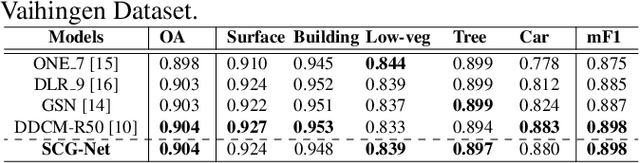
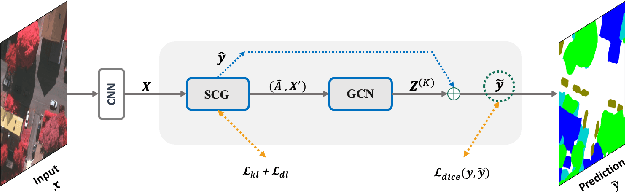
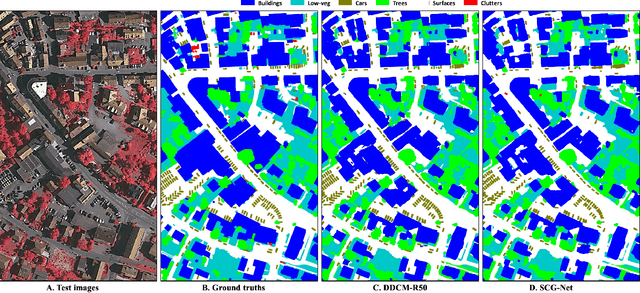
Graph Neural Networks (GNNs) have received increasing attention in many fields. However, due to the lack of prior graphs, their use for semantic labeling has been limited. Here, we propose a novel architecture called the Self-Constructing Graph (SCG), which makes use of learnable latent variables to generate embeddings and to self-construct the underlying graphs directly from the input features without relying on manually built prior knowledge graphs. SCG can automatically obtain optimized non-local context graphs from complex-shaped objects in aerial imagery. We optimize SCG via an adaptive diagonal enhancement method and a variational lower bound that consists of a customized graph reconstruction term and a Kullback-Leibler divergence regularization term. We demonstrate the effectiveness and flexibility of the proposed SCG on the publicly available ISPRS Vaihingen dataset and our model SCG-Net achieves competitive results in terms of F1-score with much fewer parameters and at a lower computational cost compared to related pure-CNN based work. Our code will be made public soon.
Multi-view Self-Constructing Graph Convolutional Networks with Adaptive Class Weighting Loss for Semantic Segmentation
Apr 21, 2020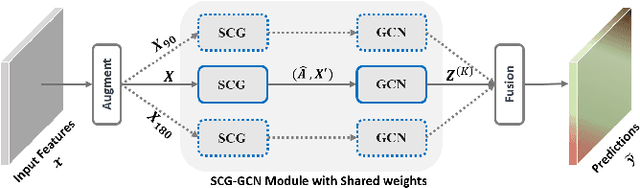
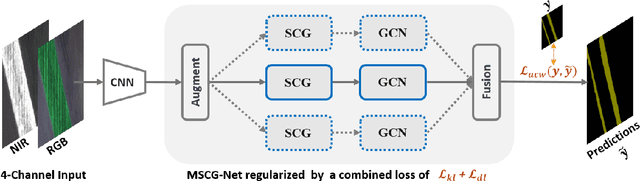


We propose a novel architecture called the Multi-view Self-Constructing Graph Convolutional Networks (MSCG-Net) for semantic segmentation. Building on the recently proposed Self-Constructing Graph (SCG) module, which makes use of learnable latent variables to self-construct the underlying graphs directly from the input features without relying on manually built prior knowledge graphs, we leverage multiple views in order to explicitly exploit the rotational invariance in airborne images. We further develop an adaptive class weighting loss to address the class imbalance. We demonstrate the effectiveness and flexibility of the proposed method on the Agriculture-Vision challenge dataset and our model achieves very competitive results (0.547 mIoU) with much fewer parameters and at a lower computational cost compared to related pure-CNN based work. Code will be available at: github.com/samleoqh/MSCG-Net
Dense Dilated Convolutions Merging Network for Land Cover Classification
Mar 09, 2020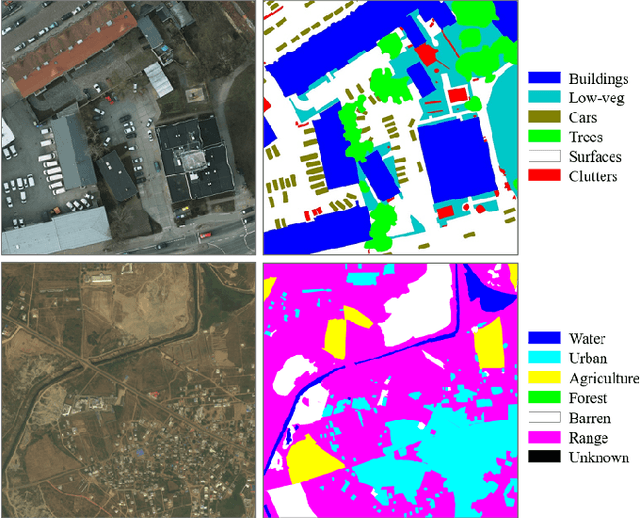
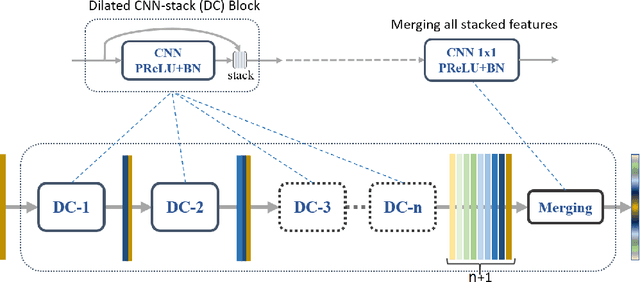
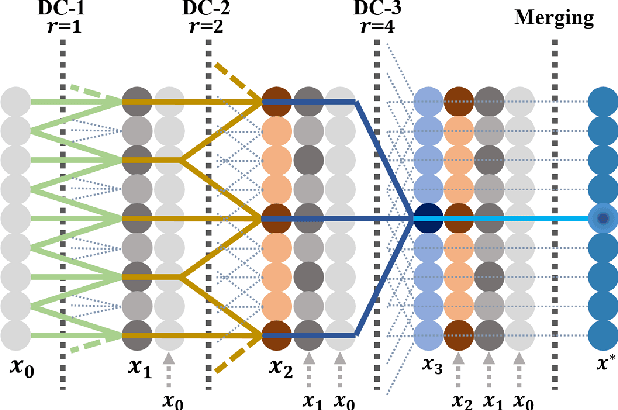
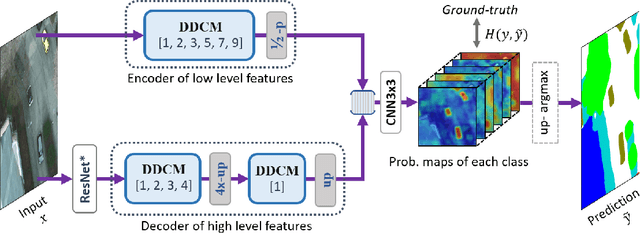
Land cover classification of remote sensing images is a challenging task due to limited amounts of annotated data, highly imbalanced classes, frequent incorrect pixel-level annotations, and an inherent complexity in the semantic segmentation task. In this article, we propose a novel architecture called the dense dilated convolutions' merging network (DDCM-Net) to address this task. The proposed DDCM-Net consists of dense dilated image convolutions merged with varying dilation rates. This effectively utilizes rich combinations of dilated convolutions that enlarge the network's receptive fields with fewer parameters and features compared with the state-of-the-art approaches in the remote sensing domain. Importantly, DDCM-Net obtains fused local- and global-context information, in effect incorporating surrounding discriminative capability for multiscale and complex-shaped objects with similar color and textures in very high-resolution aerial imagery. We demonstrate the effectiveness, robustness, and flexibility of the proposed DDCM-Net on the publicly available ISPRS Potsdam and Vaihingen data sets, as well as the DeepGlobe land cover data set. Our single model, trained on three-band Potsdam and Vaihingen data sets, achieves better accuracy in terms of both mean intersection over union (mIoU) and F1-score compared with other published models trained with more than three-band data. We further validate our model on the DeepGlobe data set, achieving state-of-the-art result 56.2% mIoU with much fewer parameters and at a lower computational cost compared with related recent work. Code available at https://github.com/samleoqh/DDCM-Semantic-Segmentation-PyTorch