 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKeypoint Counting Classifiers: Turning Vision Transformers into Self-Explainable Models Without Training
Dec 19, 2025
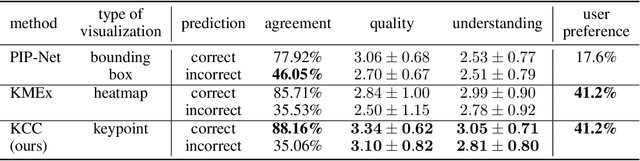

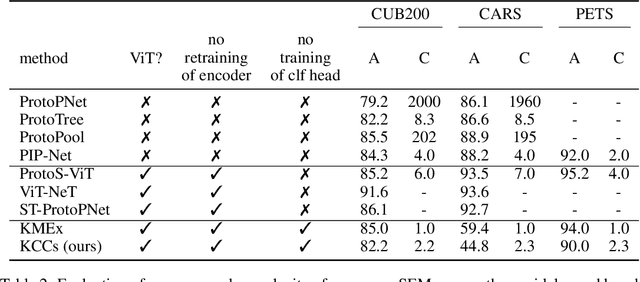
Current approaches for designing self-explainable models (SEMs) require complicated training procedures and specific architectures which makes them impractical. With the advance of general purpose foundation models based on Vision Transformers (ViTs), this impracticability becomes even more problematic. Therefore, new methods are necessary to provide transparency and reliability to ViT-based foundation models. In this work, we present a new method for turning any well-trained ViT-based model into a SEM without retraining, which we call Keypoint Counting Classifiers (KCCs). Recent works have shown that ViTs can automatically identify matching keypoints between images with high precision, and we build on these results to create an easily interpretable decision process that is inherently visualizable in the input. We perform an extensive evaluation which show that KCCs improve the human-machine communication compared to recent baselines. We believe that KCCs constitute an important step towards making ViT-based foundation models more transparent and reliable.
The Impact of Longitudinal Mammogram Alignment on Breast Cancer Risk Assessment
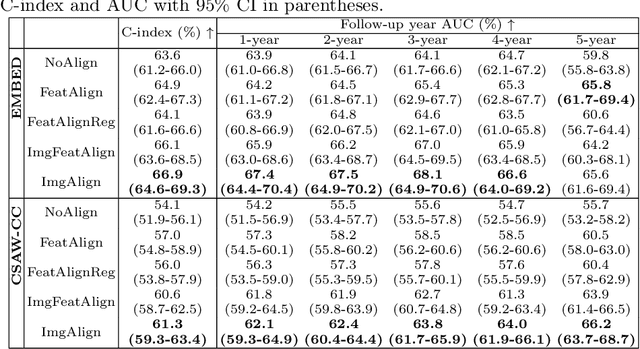
Nov 11, 2025Regular mammography screening is crucial for early breast cancer detection. By leveraging deep learning-based risk models, screening intervals can be personalized, especially for high-risk individuals. While recent methods increasingly incorporate longitudinal information from prior mammograms, accurate spatial alignment across time points remains a key challenge. Misalignment can obscure meaningful tissue changes and degrade model performance. In this study, we provide insights into various alignment strategies, image-based registration, feature-level (representation space) alignment with and without regularization, and implicit alignment methods, for their effectiveness in longitudinal deep learning-based risk modeling. Using two large-scale mammography datasets, we assess each method across key metrics, including predictive accuracy, precision, recall, and deformation field quality. Our results show that image-based registration consistently outperforms the more recently favored feature-based and implicit approaches across all metrics, enabling more accurate, temporally consistent predictions and generating smooth, anatomically plausible deformation fields. Although regularizing the deformation field improves deformation quality, it reduces the risk prediction performance of feature-level alignment. Applying image-based deformation fields within the feature space yields the best risk prediction performance. These findings underscore the importance of image-based deformation fields for spatial alignment in longitudinal risk modeling, offering improved prediction accuracy and robustness. This approach has strong potential to enhance personalized screening and enable earlier interventions for high-risk individuals. The code is available at https://github.com/sot176/Mammogram_Alignment_Study_Risk_Prediction.git, allowing full reproducibility of the results.
A robust and versatile deep learning model for prediction of the arterial input function in dynamic small animal $\left[^{18}\text{F}\right]$FDG PET imaging
Jul 03, 2025![Figure 1 for A robust and versatile deep learning model for prediction of the arterial input function in dynamic small animal $\left[^{18}\text{F}\right]$FDG PET imaging](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2Faeedac3751b9e214478a1237ed9043e09178057f%2F5-Figure1-1.png&w=640&q=75)
![Figure 2 for A robust and versatile deep learning model for prediction of the arterial input function in dynamic small animal $\left[^{18}\text{F}\right]$FDG PET imaging](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2Faeedac3751b9e214478a1237ed9043e09178057f%2F6-Figure2-1.png&w=640&q=75)
![Figure 3 for A robust and versatile deep learning model for prediction of the arterial input function in dynamic small animal $\left[^{18}\text{F}\right]$FDG PET imaging](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2Faeedac3751b9e214478a1237ed9043e09178057f%2F7-Figure3-1.png&w=640&q=75)
![Figure 4 for A robust and versatile deep learning model for prediction of the arterial input function in dynamic small animal $\left[^{18}\text{F}\right]$FDG PET imaging](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2Faeedac3751b9e214478a1237ed9043e09178057f%2F9-Figure4-1.png&w=640&q=75)
Dynamic positron emission tomography (PET) and kinetic modeling are pivotal in advancing tracer development research in small animal studies. Accurate kinetic modeling requires precise input function estimation, traditionally achieved via arterial blood sampling. However, arterial cannulation in small animals like mice, involves intricate, time-consuming, and terminal procedures, precluding longitudinal studies. This work proposes a non-invasive, fully convolutional deep learning-based approach (FC-DLIF) to predict input functions directly from PET imaging, potentially eliminating the need for blood sampling in dynamic small-animal PET. The proposed FC-DLIF model includes a spatial feature extractor acting on the volumetric time frames of the PET sequence, extracting spatial features. These are subsequently further processed in a temporal feature extractor that predicts the arterial input function. The proposed approach is trained and evaluated using images and arterial blood curves from [$^{18}$F]FDG data using cross validation. Further, the model applicability is evaluated on imaging data and arterial blood curves collected using two additional radiotracers ([$^{18}$F]FDOPA, and [$^{68}$Ga]PSMA). The model was further evaluated on data truncated and shifted in time, to simulate shorter, and shifted, PET scans. The proposed FC-DLIF model reliably predicts the arterial input function with respect to mean squared error and correlation. Furthermore, the FC-DLIF model is able to predict the arterial input function even from truncated and shifted samples. The model fails to predict the AIF from samples collected using different radiotracers, as these are not represented in the training data. Our deep learning-based input function offers a non-invasive and reliable alternative to arterial blood sampling, proving robust and flexible to temporal shifts and different scan durations.
Reconsidering Explicit Longitudinal Mammography Alignment for Enhanced Breast Cancer Risk Prediction
Jun 24, 2025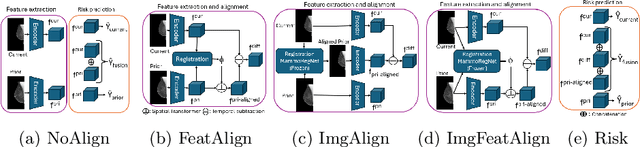
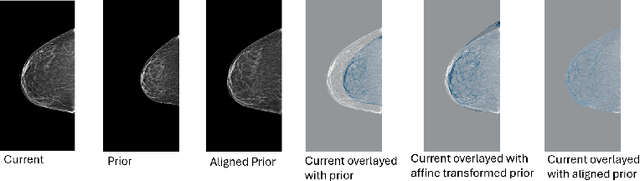

Regular mammography screening is essential for early breast cancer detection. Deep learning-based risk prediction methods have sparked interest to adjust screening intervals for high-risk groups. While early methods focused only on current mammograms, recent approaches leverage the temporal aspect of screenings to track breast tissue changes over time, requiring spatial alignment across different time points. Two main strategies for this have emerged: explicit feature alignment through deformable registration and implicit learned alignment using techniques like transformers, with the former providing more control. However, the optimal approach for explicit alignment in mammography remains underexplored. In this study, we provide insights into where explicit alignment should occur (input space vs. representation space) and if alignment and risk prediction should be jointly optimized. We demonstrate that jointly learning explicit alignment in representation space while optimizing risk estimation performance, as done in the current state-of-the-art approach, results in a trade-off between alignment quality and predictive performance and show that image-level alignment is superior to representation-level alignment, leading to better deformation field quality and enhanced risk prediction accuracy. The code is available at https://github.com/sot176/Longitudinal_Mammogram_Alignment.git.
From Flexibility to Manipulation: The Slippery Slope of XAI Evaluation
Dec 07, 2024



The lack of ground truth explanation labels is a fundamental challenge for quantitative evaluation in explainable artificial intelligence (XAI). This challenge becomes especially problematic when evaluation methods have numerous hyperparameters that must be specified by the user, as there is no ground truth to determine an optimal hyperparameter selection. It is typically not feasible to do an exhaustive search of hyperparameters so researchers typically make a normative choice based on similar studies in the literature, which provides great flexibility for the user. In this work, we illustrate how this flexibility can be exploited to manipulate the evaluation outcome. We frame this manipulation as an adversarial attack on the evaluation where seemingly innocent changes in hyperparameter setting significantly influence the evaluation outcome. We demonstrate the effectiveness of our manipulation across several datasets with large changes in evaluation outcomes across several explanation methods and models. Lastly, we propose a mitigation strategy based on ranking across hyperparameters that aims to provide robustness towards such manipulation. This work highlights the difficulty of conducting reliable XAI evaluation and emphasizes the importance of a holistic and transparent approach to evaluation in XAI.
The Kernelized Taylor Diagram
May 18, 2022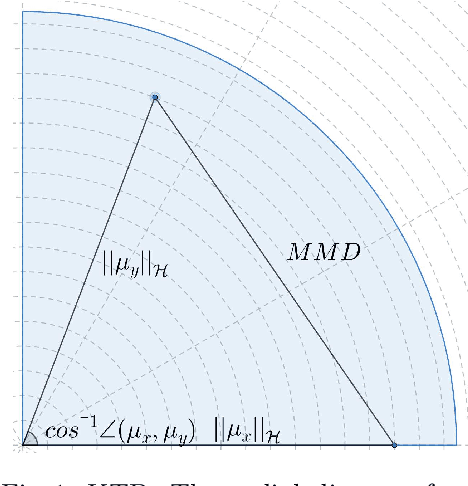
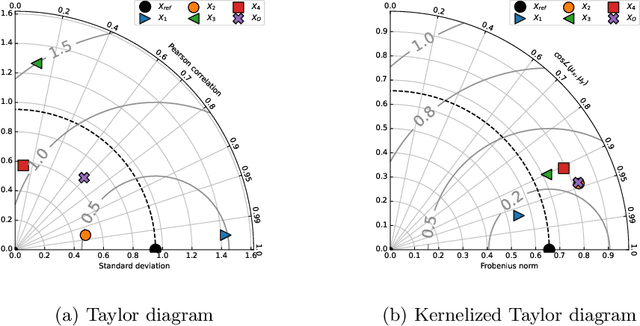
This paper presents the kernelized Taylor diagram, a graphical framework for visualizing similarities between data populations. The kernelized Taylor diagram builds on the widely used Taylor diagram, which is used to visualize similarities between populations. However, the Taylor diagram has several limitations such as not capturing non-linear relationships and sensitivity to outliers. To address such limitations, we propose the kernelized Taylor diagram. Our proposed kernelized Taylor diagram is capable of visualizing similarities between populations with minimal assumptions of the data distributions. The kernelized Taylor diagram relates the maximum mean discrepancy and the kernel mean embedding in a single diagram, a construction that, to the best of our knowledge, have not been devised prior to this work. We believe that the kernelized Taylor diagram can be a valuable tool in data visualization.
Mixing Up Contrastive Learning: Self-Supervised Representation Learning for Time Series
Mar 17, 2022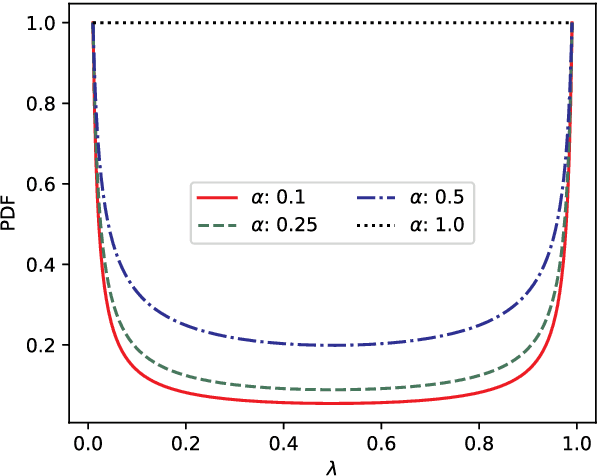
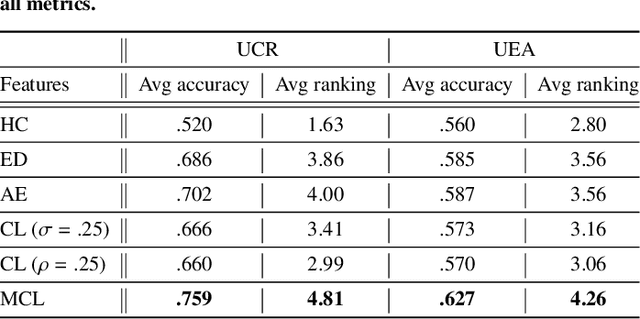
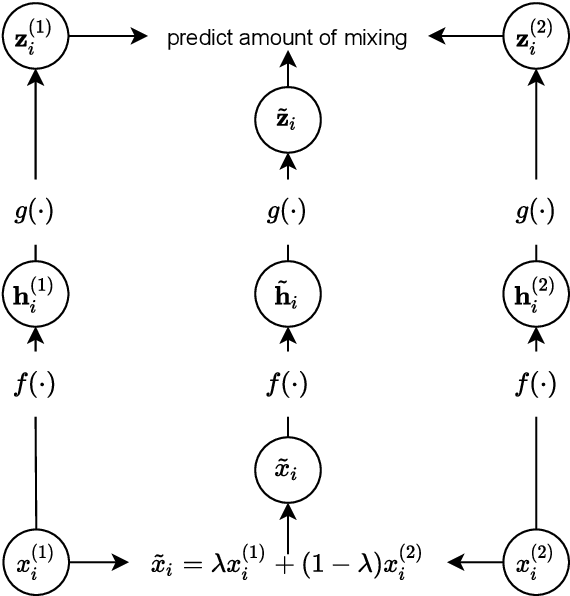
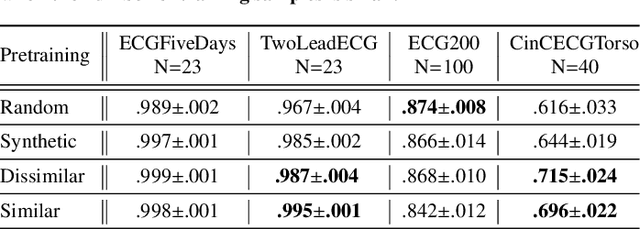
The lack of labeled data is a key challenge for learning useful representation from time series data. However, an unsupervised representation framework that is capable of producing high quality representations could be of great value. It is key to enabling transfer learning, which is especially beneficial for medical applications, where there is an abundance of data but labeling is costly and time consuming. We propose an unsupervised contrastive learning framework that is motivated from the perspective of label smoothing. The proposed approach uses a novel contrastive loss that naturally exploits a data augmentation scheme in which new samples are generated by mixing two data samples with a mixing component. The task in the proposed framework is to predict the mixing component, which is utilized as soft targets in the loss function. Experiments demonstrate the framework's superior performance compared to other representation learning approaches on both univariate and multivariate time series and illustrate its benefits for transfer learning for clinical time series.
Uncertainty-Aware Deep Ensembles for Reliable and Explainable Predictions of Clinical Time Series
Oct 16, 2020
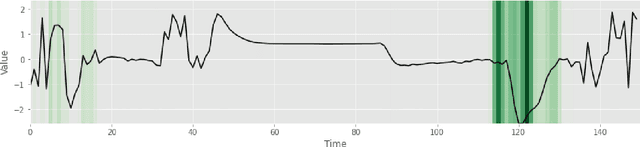
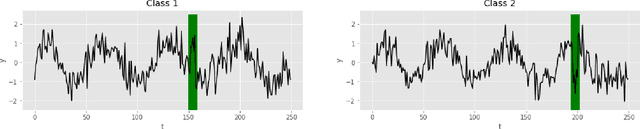
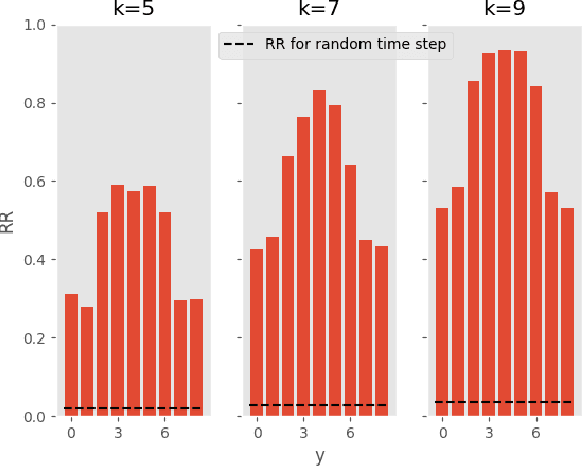
Deep learning-based support systems have demonstrated encouraging results in numerous clinical applications involving the processing of time series data. While such systems often are very accurate, they have no inherent mechanism for explaining what influenced the predictions, which is critical for clinical tasks. However, existing explainability techniques lack an important component for trustworthy and reliable decision support, namely a notion of uncertainty. In this paper, we address this lack of uncertainty by proposing a deep ensemble approach where a collection of DNNs are trained independently. A measure of uncertainty in the relevance scores is computed by taking the standard deviation across the relevance scores produced by each model in the ensemble, which in turn is used to make the explanations more reliable. The class activation mapping method is used to assign a relevance score for each time step in the time series. Results demonstrate that the proposed ensemble is more accurate in locating relevant time steps and is more consistent across random initializations, thus making the model more trustworthy. The proposed methodology paves the way for constructing trustworthy and dependable support systems for processing clinical time series for healthcare related tasks.
Information Plane Analysis of Deep Neural Networks via Matrix-Based Renyi's Entropy and Tensor Kernels
Sep 25, 2019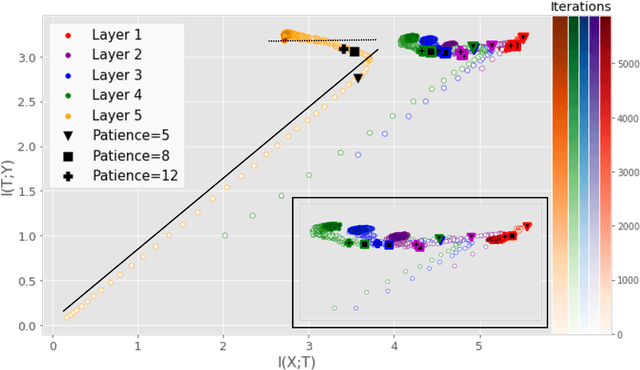
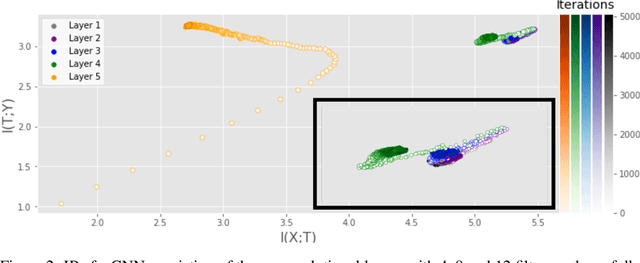
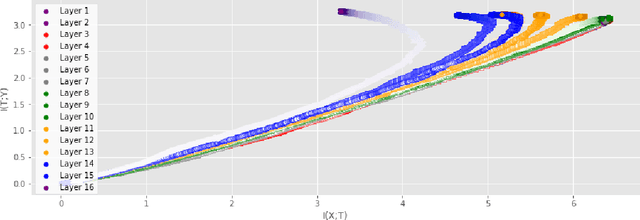
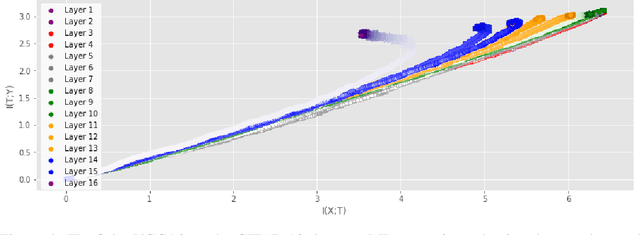
Analyzing deep neural networks (DNNs) via information plane (IP) theory has gained tremendous attention recently as a tool to gain insight into, among others, their generalization ability. However, it is by no means obvious how to estimate mutual information (MI) between each hidden layer and the input/desired output, to construct the IP. For instance, hidden layers with many neurons require MI estimators with robustness towards the high dimensionality associated with such layers. MI estimators should also be able to naturally handle convolutional layers, while at the same time being computationally tractable to scale to large networks. None of the existing IP methods to date have been able to study truly deep Convolutional Neural Networks (CNNs), such as the e.g.\ VGG-16. In this paper, we propose an IP analysis using the new matrix--based R\'enyi's entropy coupled with tensor kernels over convolutional layers, leveraging the power of kernel methods to represent properties of the probability distribution independently of the dimensionality of the data. The obtained results shed new light on the previous literature concerning small-scale DNNs, however using a completely new approach. Importantly, the new framework enables us to provide the first comprehensive IP analysis of contemporary large-scale DNNs and CNNs, investigating the different training phases and providing new insights into the training dynamics of large-scale neural networks.
Understanding Convolutional Neural Network Training with Information Theory
Oct 12, 2018
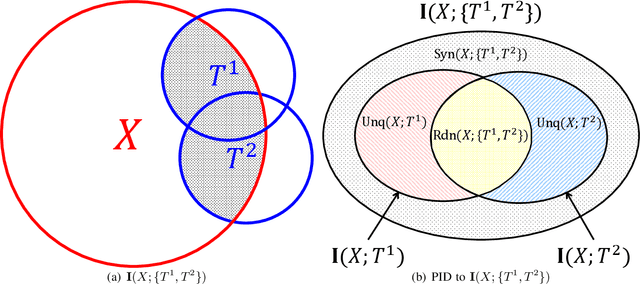

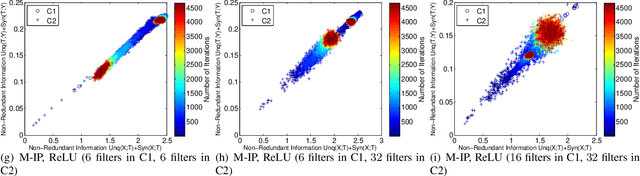
Using information theoretic concepts to understand and explore the inner organization of deep neural networks (DNNs) remains a big challenge. Recently, the concept of an information plane (coupled with the famed information bottleneck principle) began to shed light on the analysis of multilayer perceptrons (MLPs). We provided an in-depth insight into stacked autoencoders (SAEs) using a novel matrix-based Renyi's {\alpha}-entropy functional, enabling for the first time the analysis of the dynamics of learning using information flow in the real-world scenario involving complex network architecture and large data. Despite the great potential of these past works, there are several open questions when it comes to applying information theoretic concepts to understand convolutional neural networks (CNNs). These include for instance the accurate estimation of information quantities among multiple variables, and the many different training methodologies. By extending the novel matrix-based Renyi's {\alpha}-entropy functional to a multivariate scenario and introducing the partial information decomposition (PID) framework, this paper presents a systematic method to analyze CNNs training using information theory. Our results validate two fundamental data processing inequalities in CNNs, and also reveals some fundamental issues embedded in the training phase of CNNs.