 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Deep Predictive Coding Networks for Videos Feature Extraction without Labels
Sep 08, 2024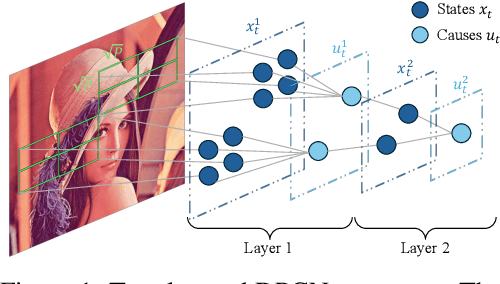
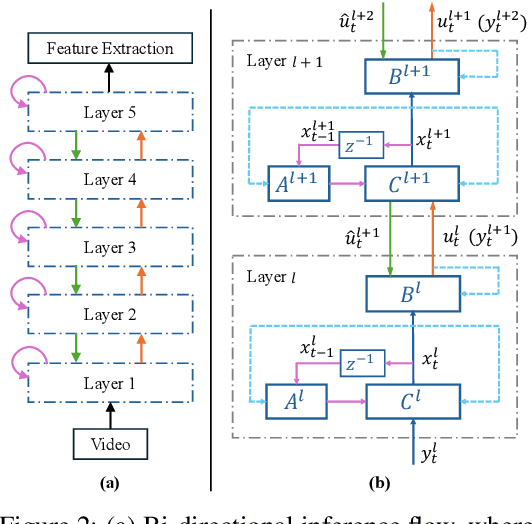
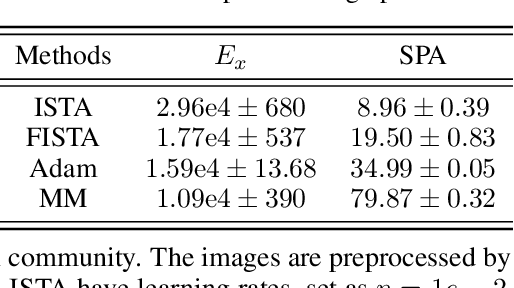
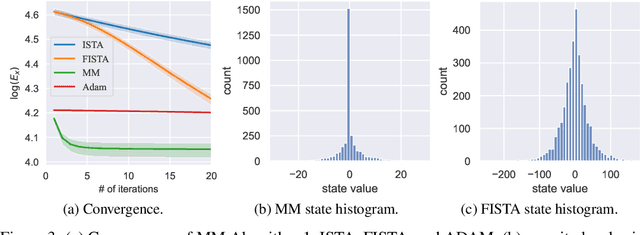
Brain-inspired deep predictive coding networks (DPCNs) effectively model and capture video features through a bi-directional information flow, even without labels. They are based on an overcomplete description of video scenes, and one of the bottlenecks has been the lack of effective sparsification techniques to find discriminative and robust dictionaries. FISTA has been the best alternative. This paper proposes a DPCN with a fast inference of internal model variables (states and causes) that achieves high sparsity and accuracy of feature clustering. The proposed unsupervised learning procedure, inspired by adaptive dynamic programming with a majorization-minimization framework, and its convergence are rigorously analyzed. Experiments in the data sets CIFAR-10, Super Mario Bros video game, and Coil-100 validate the approach, which outperforms previous versions of DPCNs on learning rate, sparsity ratio, and feature clustering accuracy. Because of DCPN's solid foundation and explainability, this advance opens the door for general applications in object recognition in video without labels.
Universal Recurrent Event Memories for Streaming Data
Jul 28, 2023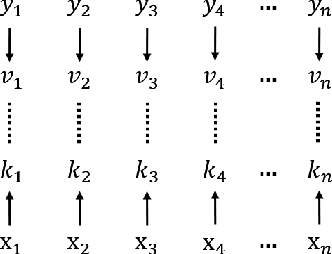
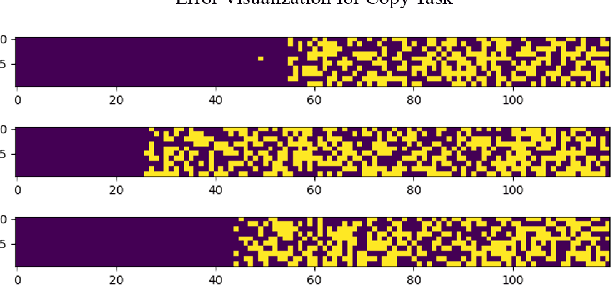
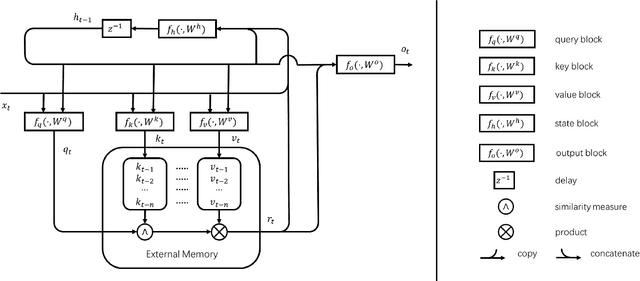
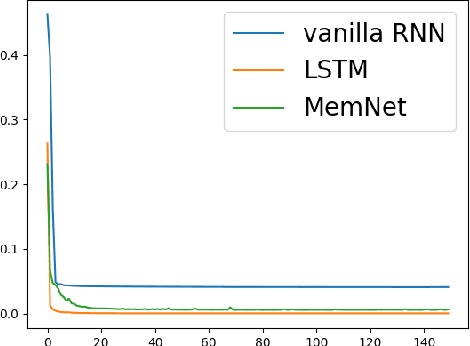
In this paper, we propose a new event memory architecture (MemNet) for recurrent neural networks, which is universal for different types of time series data such as scalar, multivariate or symbolic. Unlike other external neural memory architectures, it stores key-value pairs, which separate the information for addressing and for content to improve the representation, as in the digital archetype. Moreover, the key-value pairs also avoid the compromise between memory depth and resolution that applies to memories constructed by the model state. One of the MemNet key characteristics is that it requires only linear adaptive mapping functions while implementing a nonlinear operation on the input data. MemNet architecture can be applied without modifications to scalar time series, logic operators on strings, and also to natural language processing, providing state-of-the-art results in all application domains such as the chaotic time series, the symbolic operation tasks, and the question-answering tasks (bAbI). Finally, controlled by five linear layers, MemNet requires a much smaller number of training parameters than other external memory networks as well as the transformer network. The space complexity of MemNet equals a single self-attention layer. It greatly improves the efficiency of the attention mechanism and opens the door for IoT applications.
Dynamic Analysis and an Eigen Initializer for Recurrent Neural Networks
Jul 28, 2023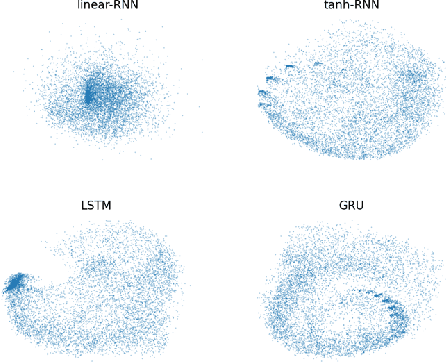
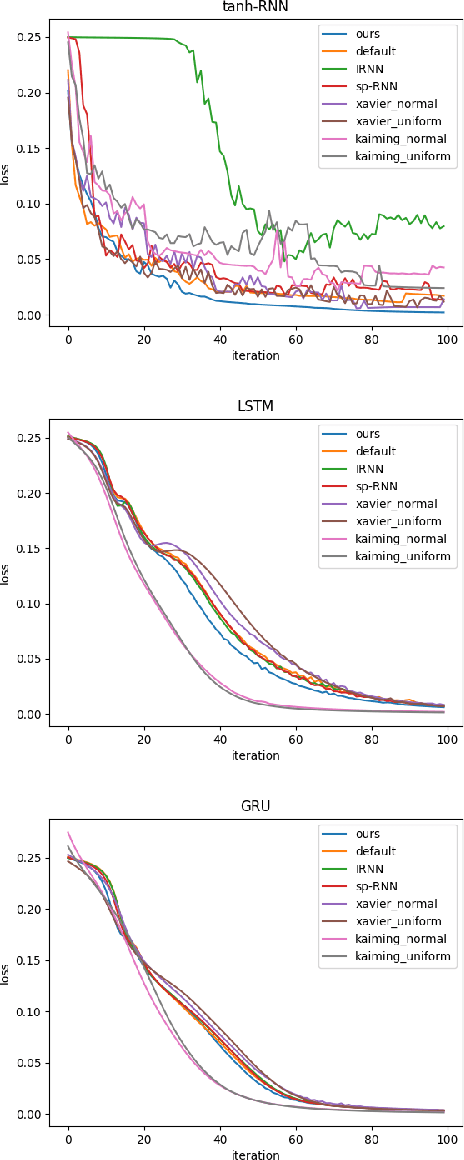
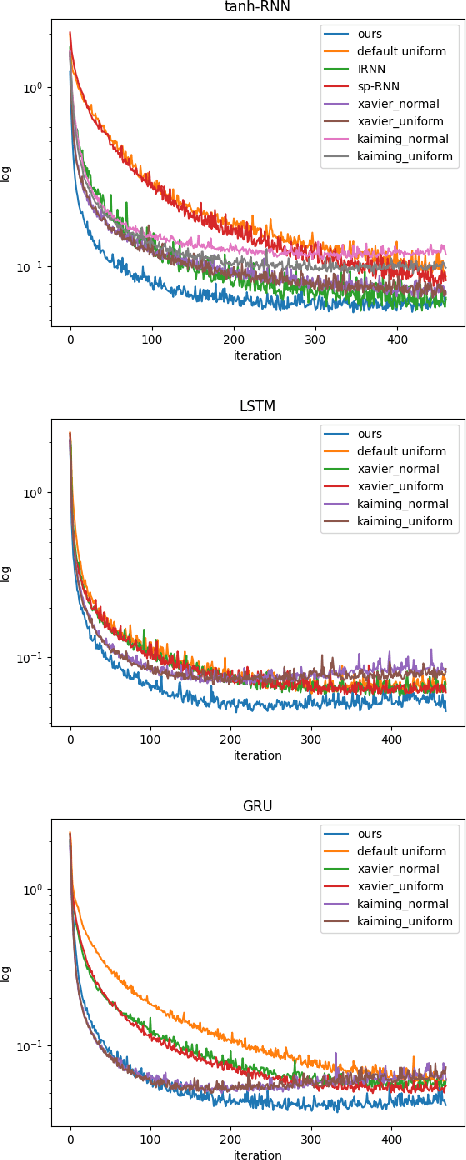
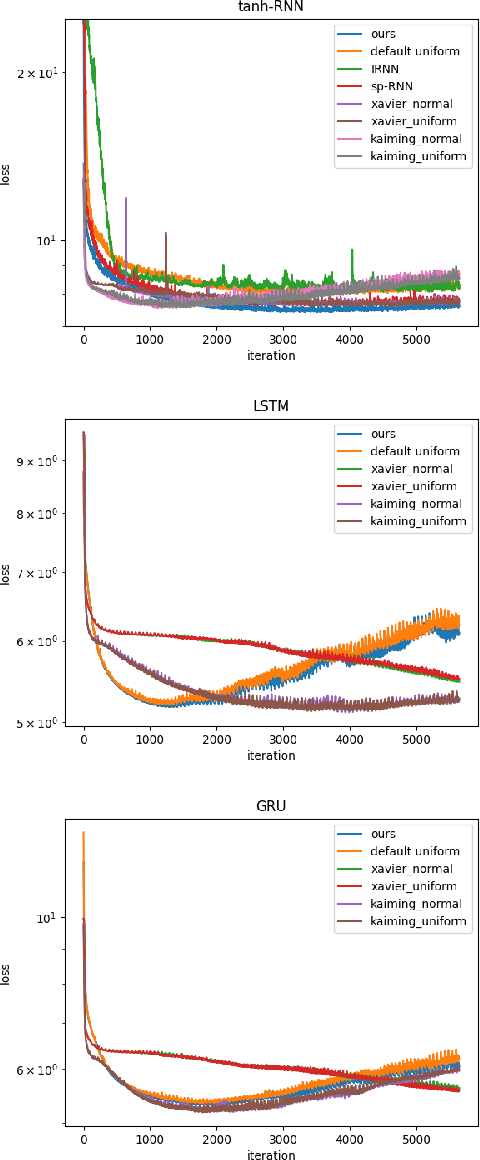
In recurrent neural networks, learning long-term dependency is the main difficulty due to the vanishing and exploding gradient problem. Many researchers are dedicated to solving this issue and they proposed many algorithms. Although these algorithms have achieved great success, understanding how the information decays remains an open problem. In this paper, we study the dynamics of the hidden state in recurrent neural networks. We propose a new perspective to analyze the hidden state space based on an eigen decomposition of the weight matrix. We start the analysis by linear state space model and explain the function of preserving information in activation functions. We provide an explanation for long-term dependency based on the eigen analysis. We also point out the different behavior of eigenvalues for regression tasks and classification tasks. From the observations on well-trained recurrent neural networks, we proposed a new initialization method for recurrent neural networks, which improves consistently performance. It can be applied to vanilla-RNN, LSTM, and GRU. We test on many datasets, such as Tomita Grammars, pixel-by-pixel MNIST datasets, and machine translation datasets (Multi30k). It outperforms the Xavier initializer and kaiming initializer as well as other RNN-only initializers like IRNN and sp-RNN in several tasks.
Causal Recurrent Variational Autoencoder for Medical Time Series Generation
Jan 16, 2023We propose causal recurrent variational autoencoder (CR-VAE), a novel generative model that is able to learn a Granger causal graph from a multivariate time series x and incorporates the underlying causal mechanism into its data generation process. Distinct to the classical recurrent VAEs, our CR-VAE uses a multi-head decoder, in which the $p$-th head is responsible for generating the $p$-th dimension of $\mathbf{x}$ (i.e., $\mathbf{x}^p$). By imposing a sparsity-inducing penalty on the weights (of the decoder) and encouraging specific sets of weights to be zero, our CR-VAE learns a sparse adjacency matrix that encodes causal relations between all pairs of variables. Thanks to this causal matrix, our decoder strictly obeys the underlying principles of Granger causality, thereby making the data generating process transparent. We develop a two-stage approach to train the overall objective. Empirically, we evaluate the behavior of our model in synthetic data and two real-world human brain datasets involving, respectively, the electroencephalography (EEG) signals and the functional magnetic resonance imaging (fMRI) data. Our model consistently outperforms state-of-the-art time series generative models both qualitatively and quantitatively. Moreover, it also discovers a faithful causal graph with similar or improved accuracy over existing Granger causality-based causal inference methods. Code of CR-VAE is publicly available at https://github.com/hongmingli1995/CR-VAE.
Hierarchical Linear Dynamical System for Representing Notes from Recorded Audio
Feb 27, 2022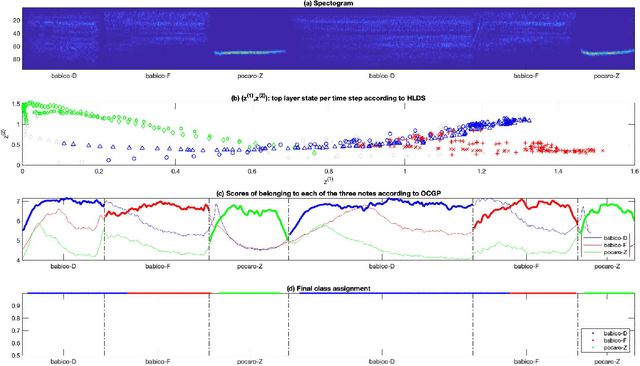


We seek to develop simultaneous segmentation and classification of notes from audio recordings in presence of outliers. The selected architecture for modeling time series is hierarchical linear dynamical system (HLDS). We propose a novel method for its parameter setting. HLDS can potentially be employed in two ways: 1) simultaneous segmentation and clustering for exploring data, i.e. finding unknown notes, 2) simultaneous segmentation and classification of audio recording for finding the notes of interest in the presence of outliers. We adapted HLDS for the second purpose since it is an easier task and still a challenging problem, e.g. in the field of bioacoustics. Each test clip has the same notes (but different instances) as of the training clip and also contain outlier notes. At test, it is automatically decided to which class of interest a note belongs to if any. Two applications of this work are to the fields of bioacoustics for detection of animal sounds in audio field recordings and also to musicology. Experiments have been conducted for segmentation and classification of both avian and musical notes from recorded audio.
Uncertainty quantification for multiclass data description
Aug 29, 2021
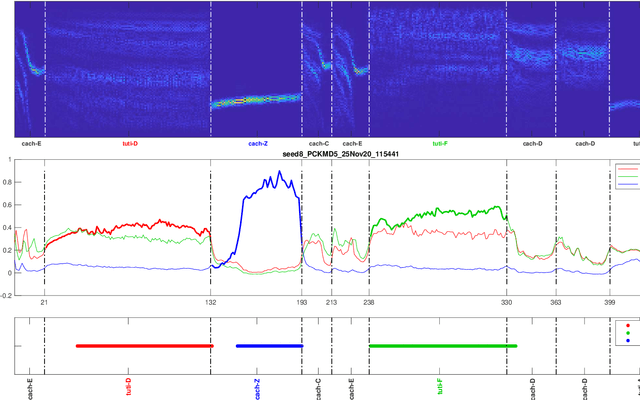

In this manuscript, we propose a multiclass data description model based on kernel Mahalanobis distance (MDD-KM) with self-adapting hyperparameter setting. MDD-KM provides uncertainty quantification and can be deployed to build classification systems for the realistic scenario where out-of-distribution (OOD) samples are present among the test data. Given a test signal, a quantity related to empirical kernel Mahalanobis distance between the signal and each of the training classes is computed. Since these quantities correspond to the same reproducing kernel Hilbert space, they are commensurable and hence can be readily treated as classification scores without further application of fusion techniques. To set kernel parameters, we exploit the fact that predictive variance according to a Gaussian process (GP) is empirical kernel Mahalanobis distance when a centralized kernel is used, and propose to use GP's negative likelihood function as the cost function. We conduct experiments on the real problem of avian note classification. We report a prototypical classification system based on a hierarchical linear dynamical system with MDD-KM as a component. Our classification system does not require sound event detection as a preprocessing step, and is able to find instances of training avian notes with varying length among OOD samples (corresponding to unknown notes of disinterest) in the test audio clip. Domain knowledge is leveraged to make crisp decisions from raw classification scores. We demonstrate the superior performance of MDD-KM over possibilistic K-nearest neighbor.
Modularizing Deep Learning via Pairwise Learning With Kernels
May 12, 2020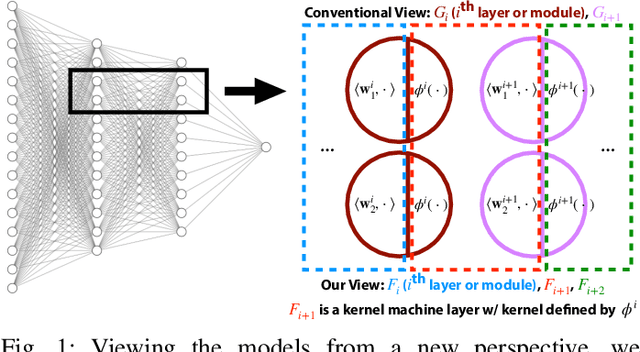
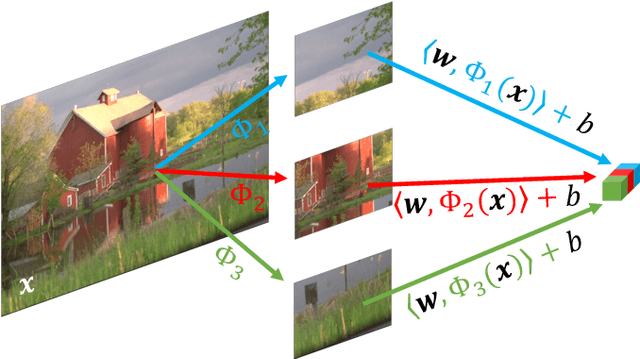
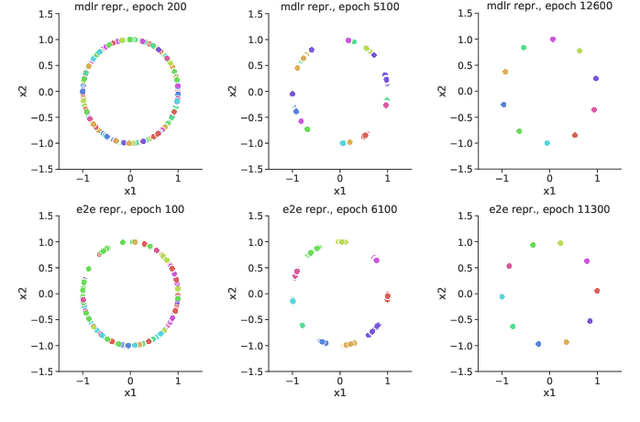
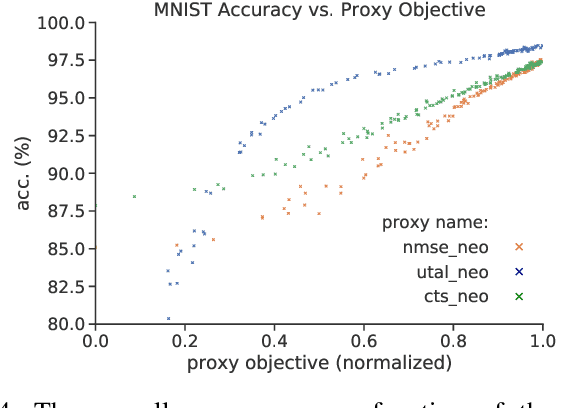
By redefining the conventional notions of layers, we present an alternative view on finitely wide, fully trainable deep neural networks as stacked linear models in feature spaces, leading to a kernel machine interpretation. Based on this construction, we then propose a provably optimal modular learning framework for classification, avoiding between-module backpropagation. This modular training approach brings new insights into the label requirement of deep learning: It leverages weak pairwise labels when learning the hidden modules. When training the output module, on the other hand, it requires full supervision but achieves high label efficiency, needing as few as 10 randomly selected labeled examples (one from each class) to achieve 94.88\% accuracy on CIFAR-10 using a ResNet-18 backbone. Moreover, modular training enables fully modularized deep learning workflows, which then simplify the design and implementation of pipelines and improve the maintainability and reusability of models. To showcase the advantages of such a modularized workflow, we describe a simple yet reliable method for estimating reusability of pre-trained modules as well as task transferability in a transfer learning setting. At practically no computation overhead, it precisely described the task space structure of 15 binary classification tasks from CIFAR-10.
Information Plane Analysis of Deep Neural Networks via Matrix-Based Renyi's Entropy and Tensor Kernels
Sep 25, 2019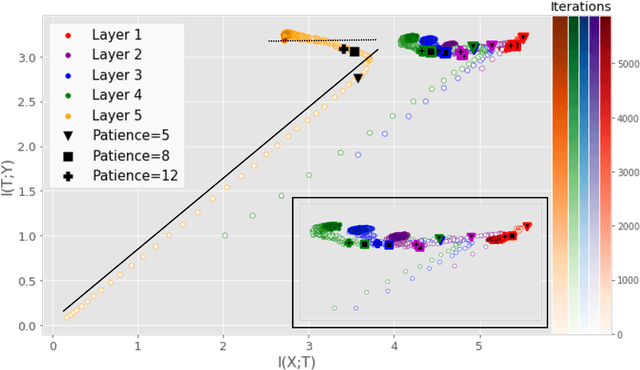
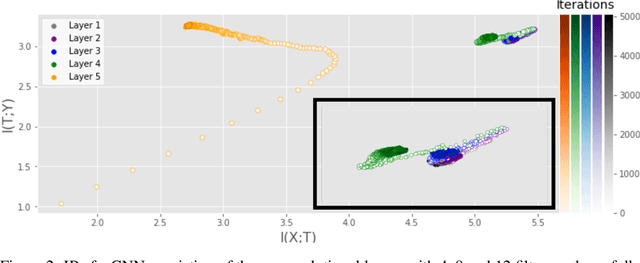
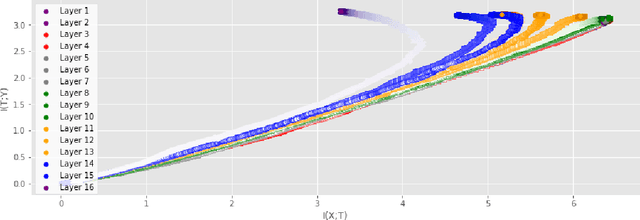
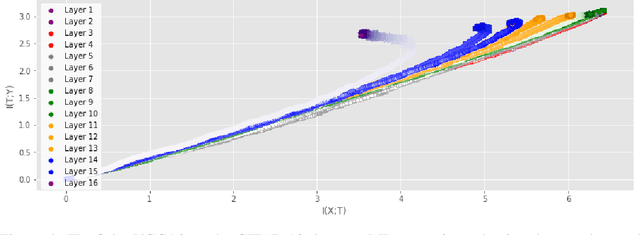
Analyzing deep neural networks (DNNs) via information plane (IP) theory has gained tremendous attention recently as a tool to gain insight into, among others, their generalization ability. However, it is by no means obvious how to estimate mutual information (MI) between each hidden layer and the input/desired output, to construct the IP. For instance, hidden layers with many neurons require MI estimators with robustness towards the high dimensionality associated with such layers. MI estimators should also be able to naturally handle convolutional layers, while at the same time being computationally tractable to scale to large networks. None of the existing IP methods to date have been able to study truly deep Convolutional Neural Networks (CNNs), such as the e.g.\ VGG-16. In this paper, we propose an IP analysis using the new matrix--based R\'enyi's entropy coupled with tensor kernels over convolutional layers, leveraging the power of kernel methods to represent properties of the probability distribution independently of the dimensionality of the data. The obtained results shed new light on the previous literature concerning small-scale DNNs, however using a completely new approach. Importantly, the new framework enables us to provide the first comprehensive IP analysis of contemporary large-scale DNNs and CNNs, investigating the different training phases and providing new insights into the training dynamics of large-scale neural networks.
A Taxonomy for Neural Memory Networks
May 01, 2018



In this paper, a taxonomy for memory networks is proposed based on their memory organization. The taxonomy includes all the popular memory networks: vanilla recurrent neural network (RNN), long short term memory (LSTM ), neural stack and neural Turing machine and their variants. The taxonomy puts all these networks under a single umbrella and shows their relative expressive power , i.e. vanilla RNN <=LSTM<=neural stack<=neural RAM. The differences and commonality between these networks are analyzed. These differences are also connected to the requirements of different tasks which can give the user instructions of how to choose or design an appropriate memory network for a specific task. As a conceptual simplified class of problems, four tasks of synthetic symbol sequences: counting, counting with interference, reversing and repeat counting are developed and tested to verify our arguments. And we use two natural language processing problems to discuss how this taxonomy helps choosing the appropriate neural memory networks for real world problem.
Learning Multiple Levels of Representations with Kernel Machines
Apr 02, 2018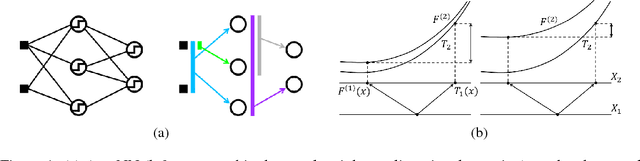
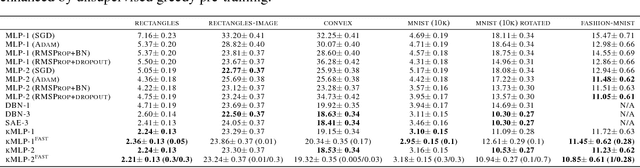
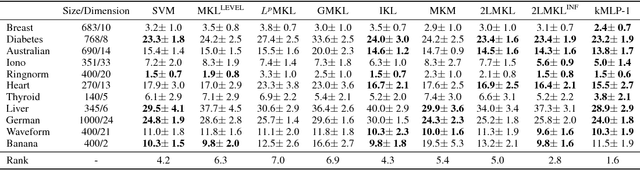
We propose a connectionist-inspired kernel machine model with three key advantages over traditional kernel machines. First, it is capable of learning distributed and hierarchical representations. Second, its performance is highly robust to the choice of kernel function. Third, the solution space is not limited to the span of images of training data in reproducing kernel Hilbert space (RKHS). Together with the architecture, we propose a greedy learning algorithm that allows the proposed multilayer network to be trained layer-wise without backpropagation by optimizing the geometric properties of images in RKHS. With a single fixed generic kernel for each layer and two layers in total, our model compares favorably with state-of-the-art multiple kernel learning algorithms using significantly more kernels and popular deep architectures on widely used classification benchmarks.