 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Analysis and an Eigen Initializer for Recurrent Neural Networks
Paper and Code
Jul 28, 2023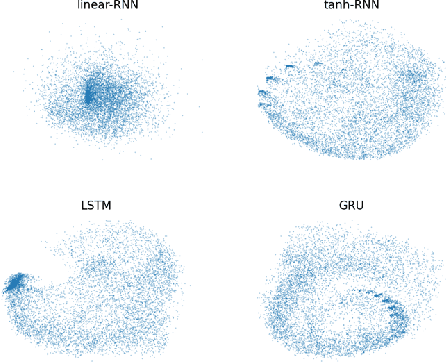
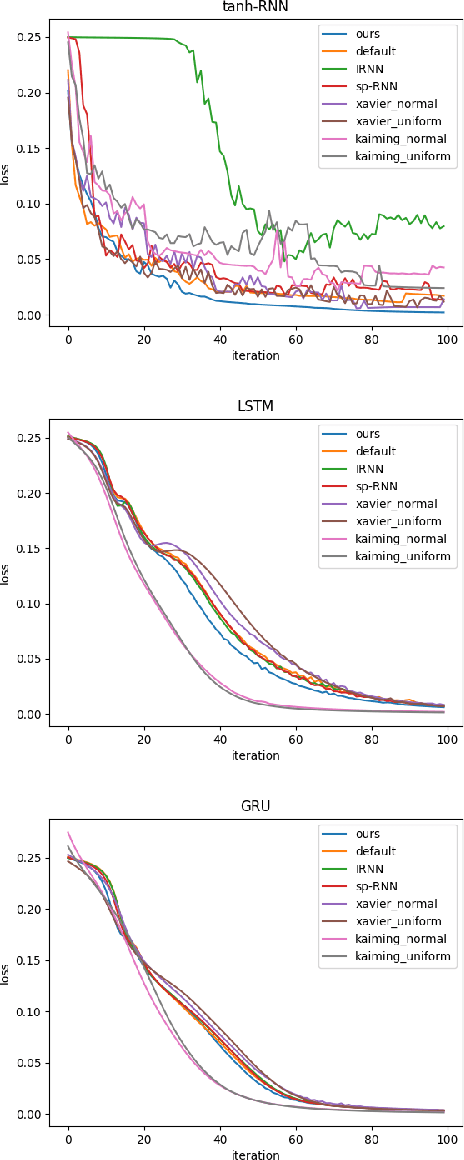
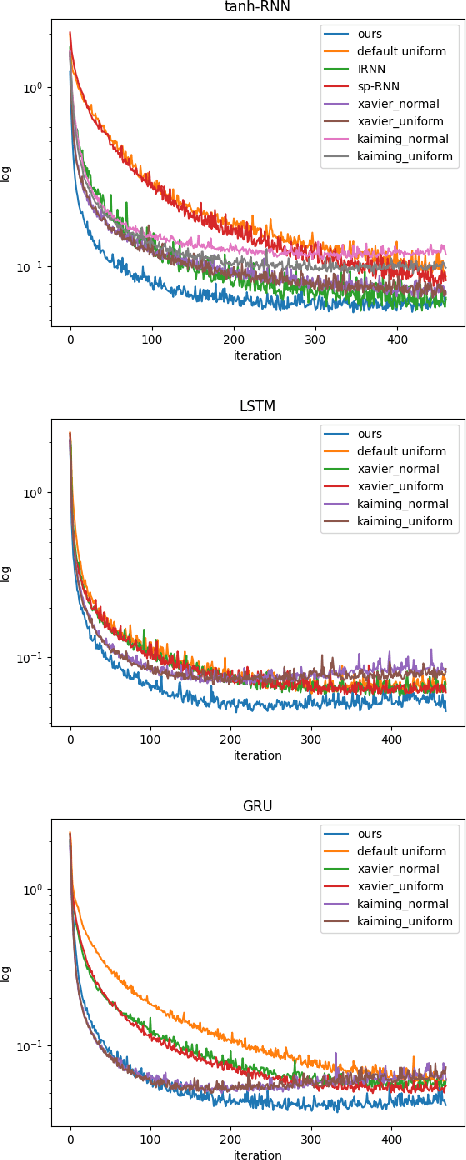
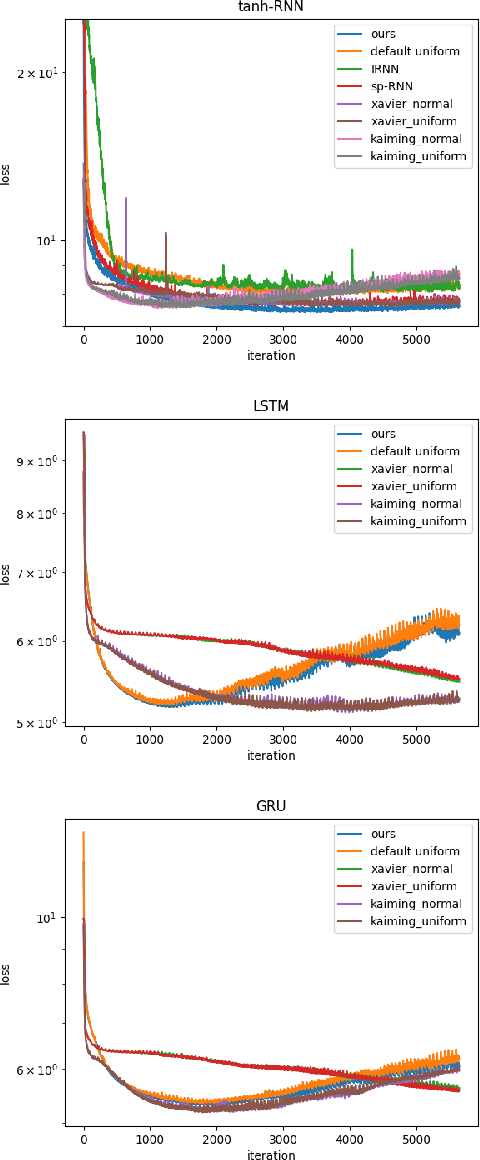
In recurrent neural networks, learning long-term dependency is the main difficulty due to the vanishing and exploding gradient problem. Many researchers are dedicated to solving this issue and they proposed many algorithms. Although these algorithms have achieved great success, understanding how the information decays remains an open problem. In this paper, we study the dynamics of the hidden state in recurrent neural networks. We propose a new perspective to analyze the hidden state space based on an eigen decomposition of the weight matrix. We start the analysis by linear state space model and explain the function of preserving information in activation functions. We provide an explanation for long-term dependency based on the eigen analysis. We also point out the different behavior of eigenvalues for regression tasks and classification tasks. From the observations on well-trained recurrent neural networks, we proposed a new initialization method for recurrent neural networks, which improves consistently performance. It can be applied to vanilla-RNN, LSTM, and GRU. We test on many datasets, such as Tomita Grammars, pixel-by-pixel MNIST datasets, and machine translation datasets (Multi30k). It outperforms the Xavier initializer and kaiming initializer as well as other RNN-only initializers like IRNN and sp-RNN in several tasks.