 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Recurrent Event Memories for Streaming Data
Jul 28, 2023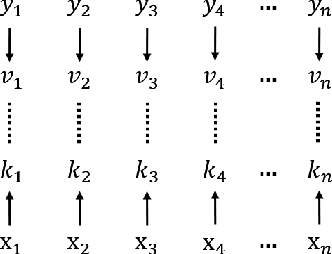
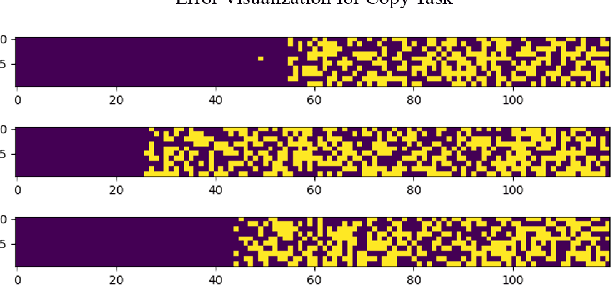
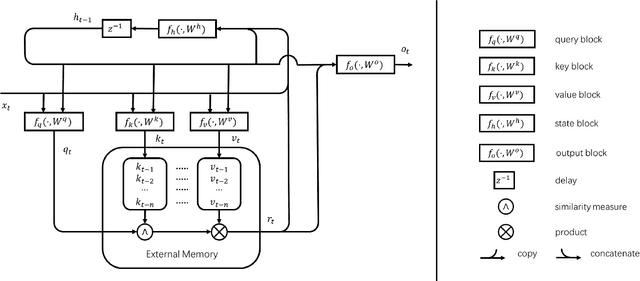
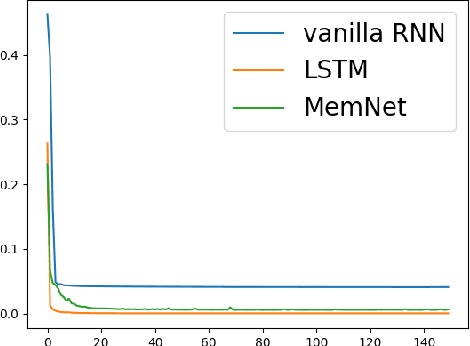
In this paper, we propose a new event memory architecture (MemNet) for recurrent neural networks, which is universal for different types of time series data such as scalar, multivariate or symbolic. Unlike other external neural memory architectures, it stores key-value pairs, which separate the information for addressing and for content to improve the representation, as in the digital archetype. Moreover, the key-value pairs also avoid the compromise between memory depth and resolution that applies to memories constructed by the model state. One of the MemNet key characteristics is that it requires only linear adaptive mapping functions while implementing a nonlinear operation on the input data. MemNet architecture can be applied without modifications to scalar time series, logic operators on strings, and also to natural language processing, providing state-of-the-art results in all application domains such as the chaotic time series, the symbolic operation tasks, and the question-answering tasks (bAbI). Finally, controlled by five linear layers, MemNet requires a much smaller number of training parameters than other external memory networks as well as the transformer network. The space complexity of MemNet equals a single self-attention layer. It greatly improves the efficiency of the attention mechanism and opens the door for IoT applications.
Dynamic Analysis and an Eigen Initializer for Recurrent Neural Networks
Jul 28, 2023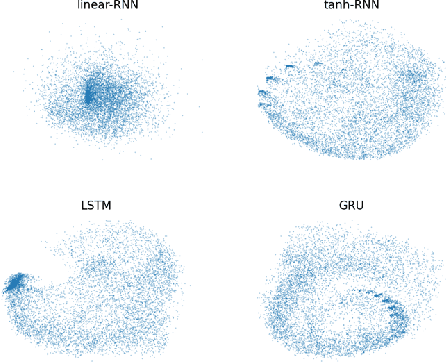
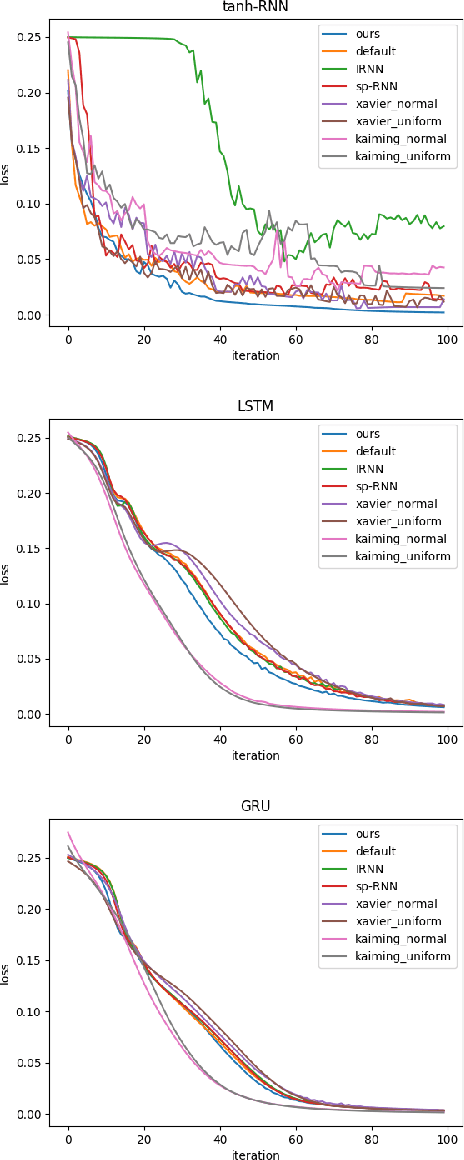
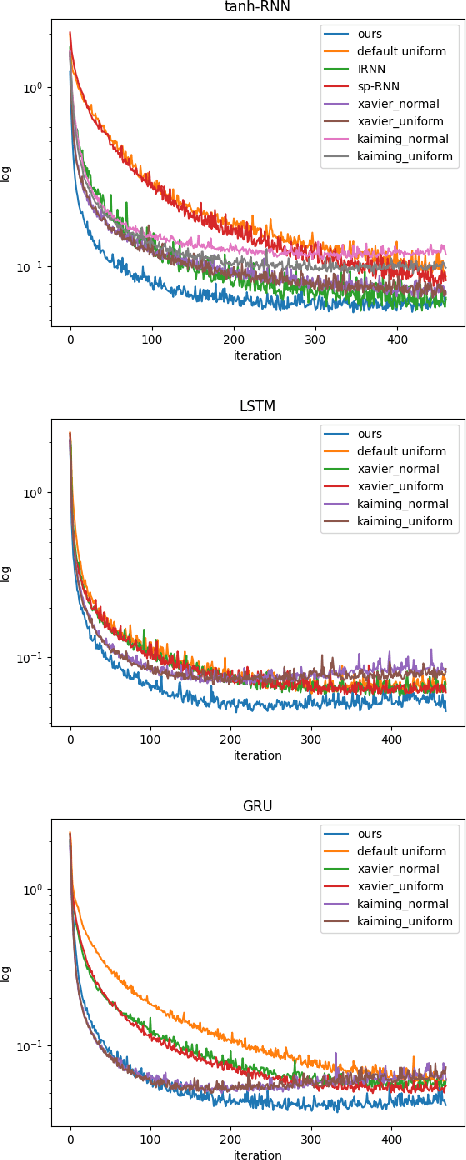
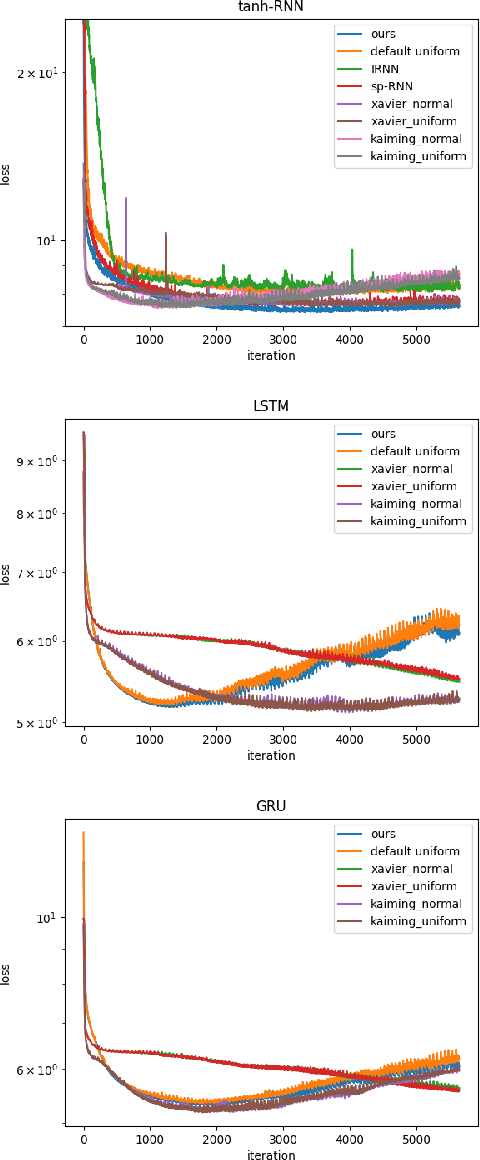
In recurrent neural networks, learning long-term dependency is the main difficulty due to the vanishing and exploding gradient problem. Many researchers are dedicated to solving this issue and they proposed many algorithms. Although these algorithms have achieved great success, understanding how the information decays remains an open problem. In this paper, we study the dynamics of the hidden state in recurrent neural networks. We propose a new perspective to analyze the hidden state space based on an eigen decomposition of the weight matrix. We start the analysis by linear state space model and explain the function of preserving information in activation functions. We provide an explanation for long-term dependency based on the eigen analysis. We also point out the different behavior of eigenvalues for regression tasks and classification tasks. From the observations on well-trained recurrent neural networks, we proposed a new initialization method for recurrent neural networks, which improves consistently performance. It can be applied to vanilla-RNN, LSTM, and GRU. We test on many datasets, such as Tomita Grammars, pixel-by-pixel MNIST datasets, and machine translation datasets (Multi30k). It outperforms the Xavier initializer and kaiming initializer as well as other RNN-only initializers like IRNN and sp-RNN in several tasks.