 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Deep Predictive Coding Networks for Videos Feature Extraction without Labels
Sep 08, 2024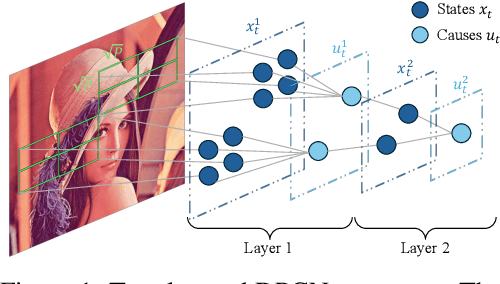
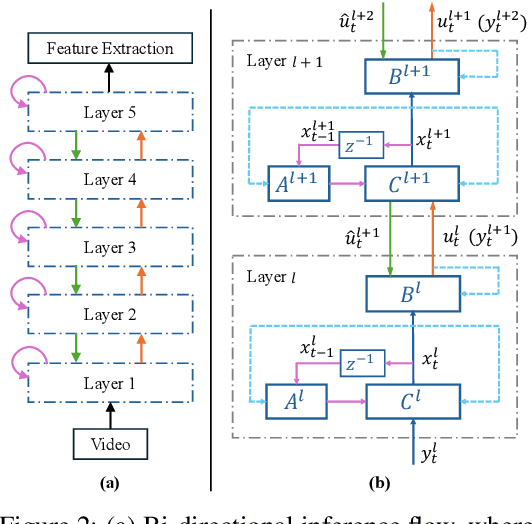
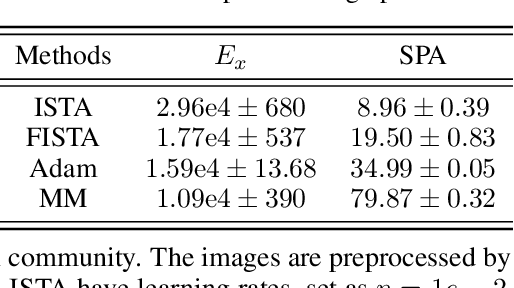
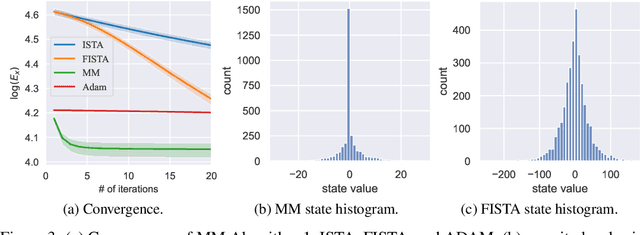
Brain-inspired deep predictive coding networks (DPCNs) effectively model and capture video features through a bi-directional information flow, even without labels. They are based on an overcomplete description of video scenes, and one of the bottlenecks has been the lack of effective sparsification techniques to find discriminative and robust dictionaries. FISTA has been the best alternative. This paper proposes a DPCN with a fast inference of internal model variables (states and causes) that achieves high sparsity and accuracy of feature clustering. The proposed unsupervised learning procedure, inspired by adaptive dynamic programming with a majorization-minimization framework, and its convergence are rigorously analyzed. Experiments in the data sets CIFAR-10, Super Mario Bros video game, and Coil-100 validate the approach, which outperforms previous versions of DPCNs on learning rate, sparsity ratio, and feature clustering accuracy. Because of DCPN's solid foundation and explainability, this advance opens the door for general applications in object recognition in video without labels.
Data-Driven Inverse Reinforcement Learning for Expert-Learner Zero-Sum Games
Jan 05, 2023



In this paper, we formulate inverse reinforcement learning (IRL) as an expert-learner interaction whereby the optimal performance intent of an expert or target agent is unknown to a learner agent. The learner observes the states and controls of the expert and hence seeks to reconstruct the expert's cost function intent and thus mimics the expert's optimal response. Next, we add non-cooperative disturbances that seek to disrupt the learning and stability of the learner agent. This leads to the formulation of a new interaction we call zero-sum game IRL. We develop a framework to solve the zero-sum game IRL problem that is a modified extension of RL policy iteration (PI) to allow unknown expert performance intentions to be computed and non-cooperative disturbances to be rejected. The framework has two parts: a value function and control action update based on an extension of PI, and a cost function update based on standard inverse optimal control. Then, we eventually develop an off-policy IRL algorithm that does not require knowledge of the expert and learner agent dynamics and performs single-loop learning. Rigorous proofs and analyses are given. Finally, simulation experiments are presented to show the effectiveness of the new approach.