 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling Hardness from Noise: An Uncertainty-Driven Model-Agnostic Framework for Long-Tailed Remote Sensing Classification
Jan 01, 2026Long-Tailed distributions are pervasive in remote sensing due to the inherently imbalanced occurrence of grounded objects. However, a critical challenge remains largely overlooked, i.e., disentangling hard tail data samples from noisy ambiguous ones. Conventional methods often indiscriminately emphasize all low-confidence samples, leading to overfitting on noisy data. To bridge this gap, building upon Evidential Deep Learning, we propose a model-agnostic uncertainty-aware framework termed DUAL, which dynamically disentangles prediction uncertainty into Epistemic Uncertainty (EU) and Aleatoric Uncertainty (AU). Specifically, we introduce EU as an indicator of sample scarcity to guide a reweighting strategy for hard-to-learn tail samples, while leveraging AU to quantify data ambiguity, employing an adaptive label smoothing mechanism to suppress the impact of noise. Extensive experiments on multiple datasets across various backbones demonstrate the effectiveness and generalization of our framework, surpassing strong baselines such as TGN and SADE. Ablation studies provide further insights into the crucial choices of our design.
RubikSQL: Lifelong Learning Agentic Knowledge Base as an Industrial NL2SQL System
Aug 25, 2025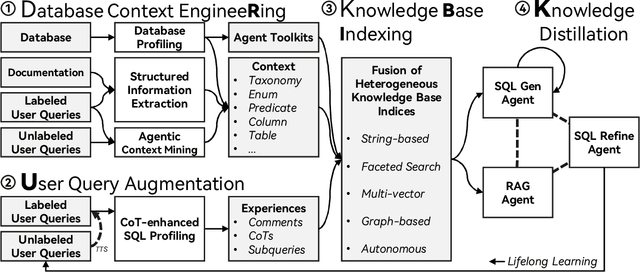
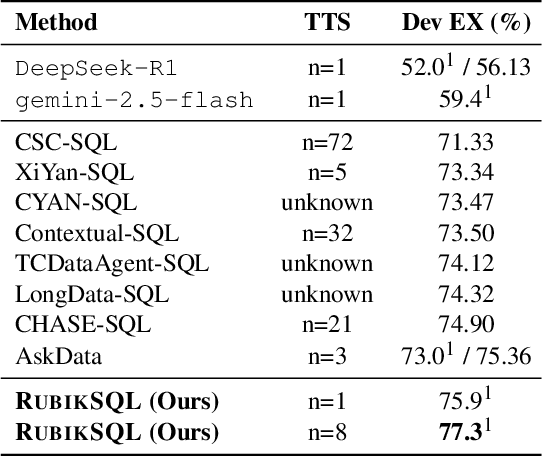
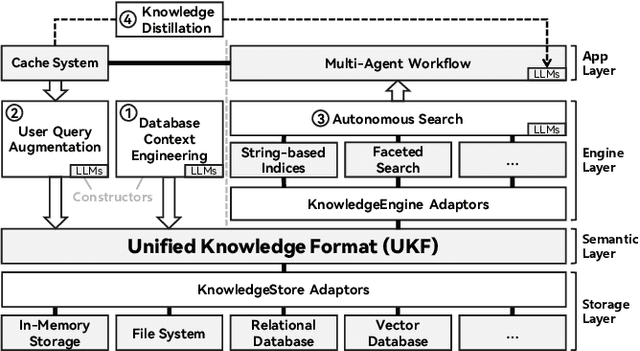
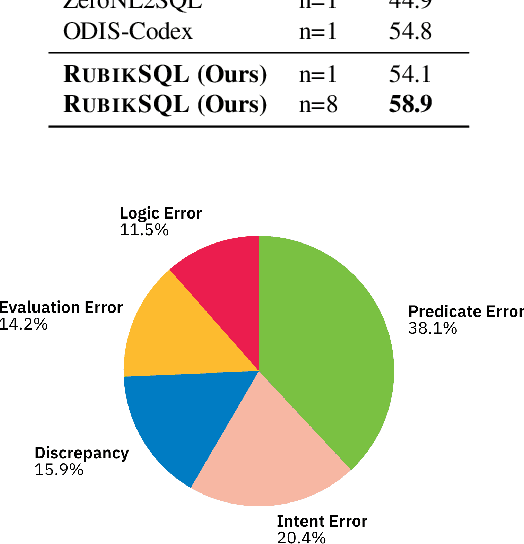
We present RubikSQL, a novel NL2SQL system designed to address key challenges in real-world enterprise-level NL2SQL, such as implicit intents and domain-specific terminology. RubikSQL frames NL2SQL as a lifelong learning task, demanding both Knowledge Base (KB) maintenance and SQL generation. RubikSQL systematically builds and refines its KB through techniques including database profiling, structured information extraction, agentic rule mining, and Chain-of-Thought (CoT)-enhanced SQL profiling. RubikSQL then employs a multi-agent workflow to leverage this curated KB, generating accurate SQLs. RubikSQL achieves SOTA performance on both the KaggleDBQA and BIRD Mini-Dev datasets. Finally, we release the RubikBench benchmark, a new benchmark specifically designed to capture vital traits of industrial NL2SQL scenarios, providing a valuable resource for future research.
LAMA-Net: A Convergent Network Architecture for Dual-Domain Reconstruction
Jul 30, 2025We propose a learnable variational model that learns the features and leverages complementary information from both image and measurement domains for image reconstruction. In particular, we introduce a learned alternating minimization algorithm (LAMA) from our prior work, which tackles two-block nonconvex and nonsmooth optimization problems by incorporating a residual learning architecture in a proximal alternating framework. In this work, our goal is to provide a complete and rigorous convergence proof of LAMA and show that all accumulation points of a specified subsequence of LAMA must be Clarke stationary points of the problem. LAMA directly yields a highly interpretable neural network architecture called LAMA-Net. Notably, in addition to the results shown in our prior work, we demonstrate that the convergence property of LAMA yields outstanding stability and robustness of LAMA-Net in this work. We also show that the performance of LAMA-Net can be further improved by integrating a properly designed network that generates suitable initials, which we call iLAMA-Net. To evaluate LAMA-Net/iLAMA-Net, we conduct several experiments and compare them with several state-of-the-art methods on popular benchmark datasets for Sparse-View Computed Tomography.
* arXiv admin note: substantial text overlap with arXiv:2410.21111
Sketch-1-to-3: One Single Sketch to 3D Detailed Face Reconstruction
Feb 25, 20253D face reconstruction from a single sketch is a critical yet underexplored task with significant practical applications. The primary challenges stem from the substantial modality gap between 2D sketches and 3D facial structures, including: (1) accurately extracting facial keypoints from 2D sketches; (2) preserving diverse facial expressions and fine-grained texture details; and (3) training a high-performing model with limited data. In this paper, we propose Sketch-1-to-3, a novel framework for realistic 3D face reconstruction from a single sketch, to address these challenges. Specifically, we first introduce the Geometric Contour and Texture Detail (GCTD) module, which enhances the extraction of geometric contours and texture details from facial sketches. Additionally, we design a deep learning architecture with a domain adaptation module and a tailored loss function to align sketches with the 3D facial space, enabling high-fidelity expression and texture reconstruction. To facilitate evaluation and further research, we construct SketchFaces, a real hand-drawn facial sketch dataset, and Syn-SketchFaces, a synthetic facial sketch dataset. Extensive experiments demonstrate that Sketch-1-to-3 achieves state-of-the-art performance in sketch-based 3D face reconstruction.
LAMA: Stable Dual-Domain Deep Reconstruction For Sparse-View CT
Oct 28, 2024



Inverse problems arise in many applications, especially tomographic imaging. We develop a Learned Alternating Minimization Algorithm (LAMA) to solve such problems via two-block optimization by synergizing data-driven and classical techniques with proven convergence. LAMA is naturally induced by a variational model with learnable regularizers in both data and image domains, parameterized as composite functions of neural networks trained with domain-specific data. We allow these regularizers to be nonconvex and nonsmooth to extract features from data effectively. We minimize the overall objective function using Nesterov's smoothing technique and residual learning architecture. It is demonstrated that LAMA reduces network complexity, improves memory efficiency, and enhances reconstruction accuracy, stability, and interpretability. Extensive experiments show that LAMA significantly outperforms state-of-the-art methods on popular benchmark datasets for Computed Tomography.
Fast Deep Predictive Coding Networks for Videos Feature Extraction without Labels
Sep 08, 2024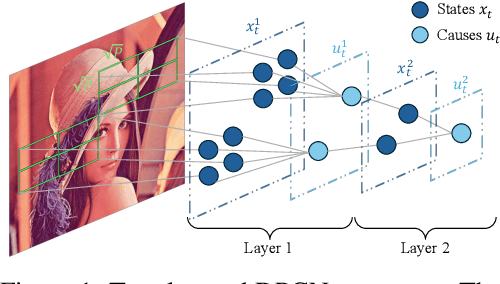
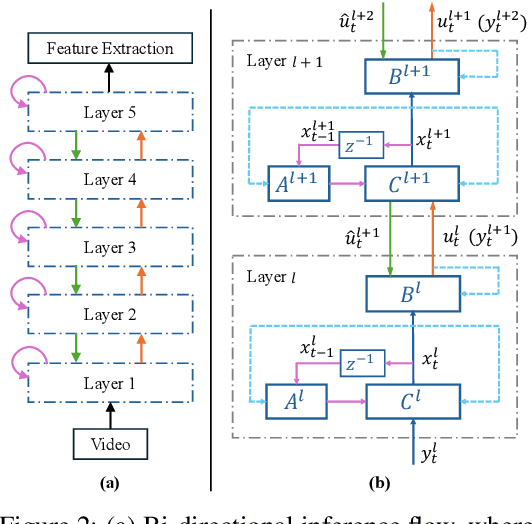
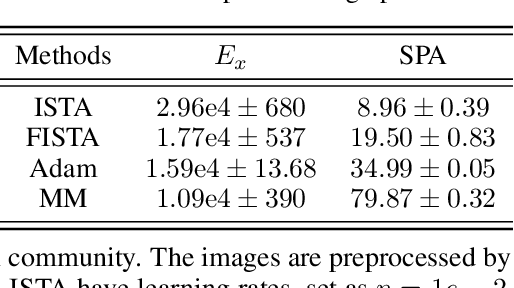
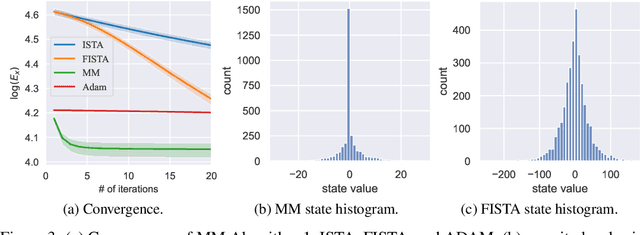
Brain-inspired deep predictive coding networks (DPCNs) effectively model and capture video features through a bi-directional information flow, even without labels. They are based on an overcomplete description of video scenes, and one of the bottlenecks has been the lack of effective sparsification techniques to find discriminative and robust dictionaries. FISTA has been the best alternative. This paper proposes a DPCN with a fast inference of internal model variables (states and causes) that achieves high sparsity and accuracy of feature clustering. The proposed unsupervised learning procedure, inspired by adaptive dynamic programming with a majorization-minimization framework, and its convergence are rigorously analyzed. Experiments in the data sets CIFAR-10, Super Mario Bros video game, and Coil-100 validate the approach, which outperforms previous versions of DPCNs on learning rate, sparsity ratio, and feature clustering accuracy. Because of DCPN's solid foundation and explainability, this advance opens the door for general applications in object recognition in video without labels.
Learned Alternating Minimization Algorithm for Dual-domain Sparse-View CT Reconstruction
Jun 06, 2023



We propose a novel Learned Alternating Minimization Algorithm (LAMA) for dual-domain sparse-view CT image reconstruction. LAMA is naturally induced by a variational model for CT reconstruction with learnable nonsmooth nonconvex regularizers, which are parameterized as composite functions of deep networks in both image and sinogram domains. To minimize the objective of the model, we incorporate the smoothing technique and residual learning architecture into the design of LAMA. We show that LAMA substantially reduces network complexity, improves memory efficiency and reconstruction accuracy, and is provably convergent for reliable reconstructions. Extensive numerical experiments demonstrate that LAMA outperforms existing methods by a wide margin on multiple benchmark CT datasets.
Algorithmic Design and Implementation of Unobtrusive Multistatic Serial LiDAR Image
Nov 08, 2019

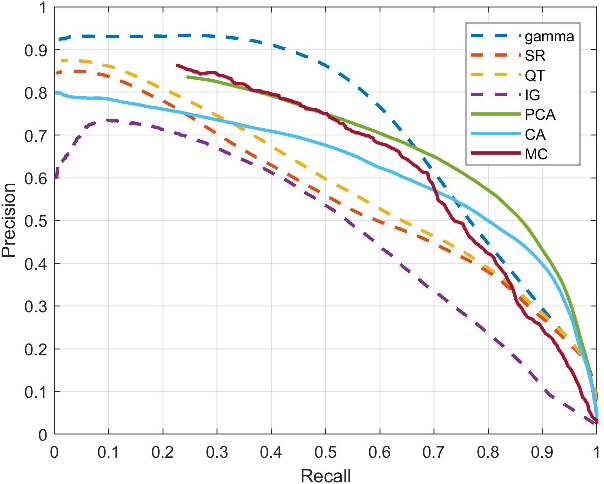
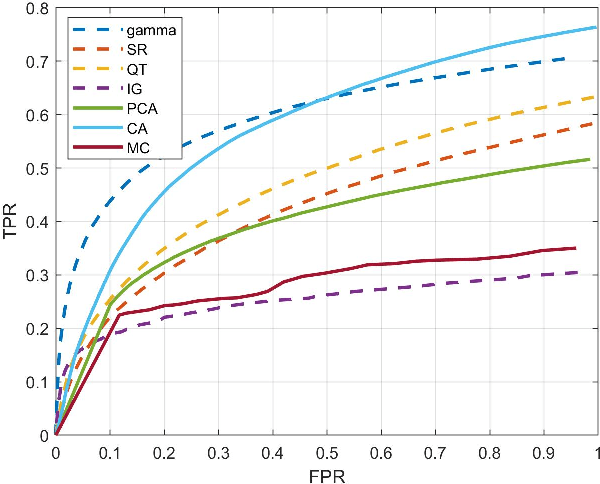
To fully understand interactions between marine hydrokinetic (MHK) equipment and marine animals, a fast and effective monitoring system is required to capture relevant information whenever underwater animals appear. A new automated underwater imaging system composed of LiDAR (Light Detection and Ranging) imaging hardware and a scene understanding software module named Unobtrusive Multistatic Serial LiDAR Imager (UMSLI) to supervise the presence of animals near turbines. UMSLI integrates the front end LiDAR hardware and a series of software modules to achieve image preprocessing, detection, tracking, segmentation and classification in a hierarchical manner.