 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSketchKeyAnime: Reference-anchored Sparse Key-Sketch Animation Synthesis
Jun 18, 2026Traditional animation production relies heavily on manual drawing and iterative refinement, particularly for key-pose design, in-betweening, and character coloring. While existing animation and video generation methods have made notable progress, they typically depend on RGB boundary frames, dense frame-wise conditions, or complete sketch sequences, limiting their applicability under low-cost input conditions. We present SketchKeyAnime, a video diffusion framework for generating structurally controllable, appearance-consistent, and temporally coherent animations from sparse key-sketch inputs. Given a single reference RGB image and a few temporally indexed key sketches, SketchKeyAnime introduces a dual-branch conditioning mechanism to encode local geometric constraints alongside semantic-temporal context. It leverages Sketch Cross Attention to fuse reference image and sketch conditions with learnable gating, and incorporates an Adaptive Weighted Loss to strengthen supervision on key-sketch frames and line-art regions. Experimental results on the Aesthetic subset of Sakuga-42M show that our approach consistently outperforms representative animation interpolation and sketch-guided generation baselines. Compared to the best-performing baseline, SketchKeyAnime reduces EDMD by 31.9\% and FVD by 9.5\%, demonstrating superior sketch fidelity and temporal coherence, while achieving the best overall performance across most quantitative metrics. These results validate the proposed framework and highlight its potential for low-cost, highly controllable animation creation.
LASA: A Weak Supervision Method for Open-Vocabulary Scene Sketch Semantic Segmentation
Jun 10, 2026Open-vocabulary scene sketch semantic segmentation aims to assign dense semantic labels to sparse line drawings based on flexible category vocabularies specified at inference time, without relying on pixel-level annotations during training. Unlike natural images, sketches lack texture and color cues, making semantic understanding heavily dependent on stroke layout and spatial configuration, a challenge that renders single-layer vision-language features inherently unstable. Our key observation is that attention maps from different Vision Transformer layers encode complementary spatial cues: shallow layers capture global structural layouts, while deeper layers focus on local stroke intersections and object parts. This suggests that cross-layer aggregation provides a more robust structural prior than any individual layer alone. Leveraging this insight, we propose a structure-aware framework built upon \textbf{L}ayer-wise \textbf{A}ccumulated \textbf{S}tructural \textbf{A}ttention (\textbf{LASA}), which aggregates multi-layer attention to guide hierarchical semantic alignment under weak supervision and refine predictions during inference. Experiments on FS-COCO, SFSD, and FrISS show that LASA improves mIoU by $+3.43$, $+8.01$, and $+15.74$ over the prior weakly supervised baselines, demonstrating consistent gains in both segmentation accuracy and spatial coherence. Our source code will be made publicly available.
TimeWeaver: Age-Consistent Reference-Based Face Restoration with Identity Preservation
Mar 24, 2026Recent progress in face restoration has shifted from visual fidelity to identity fidelity, driving a transition from reference-free to reference-based paradigms that condition restoration on reference images of the same person. However, these methods assume the reference and degraded input are age-aligned. When only cross-age references are available, as in historical restoration or missing-person retrieval, they fail to maintain age fidelity. To address this limitation, we propose TimeWeaver, the first reference-based face restoration framework supporting cross-age references. Given arbitrary reference images and a target-age prompt, TimeWeaver produces restorations with both identity fidelity and age consistency. Specifically, we decouple identity and age conditioning across training and inference. During training, the model learns an age-robust identity representation by fusing a global identity embedding with age-suppressed facial tokens via a transformer-based ID-Fusion module. During inference, two training-free techniques, Age-Aware Gradient Guidance and Token-Targeted Attention Boost, steer sampling toward desired age semantics, enabling precise adherence to the target-age prompt. Extensive experiments show that TimeWeaver surpasses existing methods in visual quality, identity preservation, and age consistency.
MeInTime: Bridging Age Gap in Identity-Preserving Face Restoration
Mar 19, 2026To better preserve an individual's identity, face restoration has evolved from reference-free to reference-based approaches, which leverage high-quality reference images of the same identity to enhance identity fidelity in the restored outputs. However, most existing methods implicitly assume that the reference and degraded input are age-aligned, limiting their effectiveness in real-world scenarios where only cross-age references are available, such as historical photo restoration. This paper proposes MeInTime, a diffusion-based face restoration method that extends reference-based restoration from same-age to cross-age settings. Given one or few reference images along with an age prompt corresponding to the degraded input, MeInTime achieves faithful restoration with both identity fidelity and age consistency. Specifically, we decouple the modeling of identity and age conditions. During training, we focus solely on effectively injecting identity features through a newly introduced attention mechanism and introduce Gated Residual Fusion modules to facilitate the integration between degraded features and identity representations. At inference, we propose Age-Aware Gradient Guidance, a training-free sampling strategy, using an age-driven direction to iteratively nudge the identity-aware denoising latent toward the desired age semantic manifold. Extensive experiments demonstrate that MeInTime outperforms existing face restoration methods in both identity preservation and age consistency. Our code is available at: https://github.com/teer4/MeInTime
InterChat: Enhancing Generative Visual Analytics using Multimodal Interactions
Mar 06, 2025



The rise of Large Language Models (LLMs) and generative visual analytics systems has transformed data-driven insights, yet significant challenges persist in accurately interpreting users' analytical and interaction intents. While language inputs offer flexibility, they often lack precision, making the expression of complex intents inefficient, error-prone, and time-intensive. To address these limitations, we investigate the design space of multimodal interactions for generative visual analytics through a literature review and pilot brainstorming sessions. Building on these insights, we introduce a highly extensible workflow that integrates multiple LLM agents for intent inference and visualization generation. We develop InterChat, a generative visual analytics system that combines direct manipulation of visual elements with natural language inputs. This integration enables precise intent communication and supports progressive, visually driven exploratory data analyses. By employing effective prompt engineering, and contextual interaction linking, alongside intuitive visualization and interaction designs, InterChat bridges the gap between user interactions and LLM-driven visualizations, enhancing both interpretability and usability. Extensive evaluations, including two usage scenarios, a user study, and expert feedback, demonstrate the effectiveness of InterChat. Results show significant improvements in the accuracy and efficiency of handling complex visual analytics tasks, highlighting the potential of multimodal interactions to redefine user engagement and analytical depth in generative visual analytics.
Sketch-1-to-3: One Single Sketch to 3D Detailed Face Reconstruction
Feb 25, 20253D face reconstruction from a single sketch is a critical yet underexplored task with significant practical applications. The primary challenges stem from the substantial modality gap between 2D sketches and 3D facial structures, including: (1) accurately extracting facial keypoints from 2D sketches; (2) preserving diverse facial expressions and fine-grained texture details; and (3) training a high-performing model with limited data. In this paper, we propose Sketch-1-to-3, a novel framework for realistic 3D face reconstruction from a single sketch, to address these challenges. Specifically, we first introduce the Geometric Contour and Texture Detail (GCTD) module, which enhances the extraction of geometric contours and texture details from facial sketches. Additionally, we design a deep learning architecture with a domain adaptation module and a tailored loss function to align sketches with the 3D facial space, enabling high-fidelity expression and texture reconstruction. To facilitate evaluation and further research, we construct SketchFaces, a real hand-drawn facial sketch dataset, and Syn-SketchFaces, a synthetic facial sketch dataset. Extensive experiments demonstrate that Sketch-1-to-3 achieves state-of-the-art performance in sketch-based 3D face reconstruction.
Temporal Consistent Automatic Video Colorization via Semantic Correspondence
May 13, 2023Video colorization task has recently attracted wide attention. Recent methods mainly work on the temporal consistency in adjacent frames or frames with small interval. However, it still faces severe challenge of the inconsistency between frames with large interval.To address this issue, we propose a novel video colorization framework, which combines semantic correspondence into automatic video colorization to keep long-range consistency. Firstly, a reference colorization network is designed to automatically colorize the first frame of each video, obtaining a reference image to supervise the following whole colorization process. Such automatically colorized reference image can not only avoid labor-intensive and time-consuming manual selection, but also enhance the similarity between reference and grayscale images. Afterwards, a semantic correspondence network and an image colorization network are introduced to colorize a series of the remaining frames with the help of the reference. Each frame is supervised by both the reference image and the immediately colorized preceding frame to improve both short-range and long-range temporal consistency. Extensive experiments demonstrate that our method outperforms other methods in maintaining temporal consistency both qualitatively and quantitatively. In the NTIRE 2023 Video Colorization Challenge, our method ranks at the 3rd place in Color Distribution Consistency (CDC) Optimization track.
SPColor: Semantic Prior Guided Exemplar-based Image Colorization
Apr 14, 2023
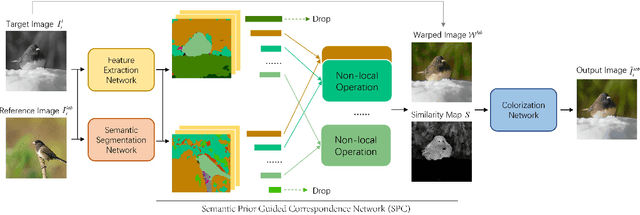


Exemplar-based image colorization aims to colorize a target grayscale image based on a color reference image, and the key is to establish accurate pixel-level semantic correspondence between these two images. Previous methods search for correspondence across the entire reference image, and this type of global matching is easy to get mismatch. We summarize the difficulties in two aspects: (1) When the reference image only contains a part of objects related to target image, improper correspondence will be established in unrelated regions. (2) It is prone to get mismatch in regions where the shape or texture of the object is easily confused. To overcome these issues, we propose SPColor, a semantic prior guided exemplar-based image colorization framework. Different from previous methods, SPColor first coarsely classifies pixels of the reference and target images to several pseudo-classes under the guidance of semantic prior, then the correspondences are only established locally between the pixels in the same class via the newly designed semantic prior guided correspondence network. In this way, improper correspondence between different semantic classes is explicitly excluded, and the mismatch is obviously alleviated. Besides, to better reserve the color from reference, a similarity masked perceptual loss is designed. Noting that the carefully designed SPColor utilizes the semantic prior provided by an unsupervised segmentation model, which is free for additional manual semantic annotations. Experiments demonstrate that our model outperforms recent state-of-the-art methods both quantitatively and qualitatively on public dataset.
Exemplar-based Video Colorization with Long-term Spatiotemporal Dependency
Mar 27, 2023
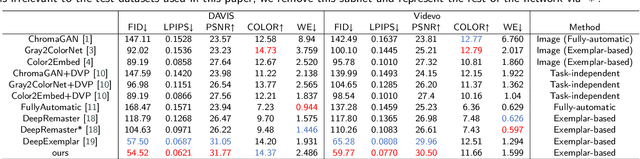
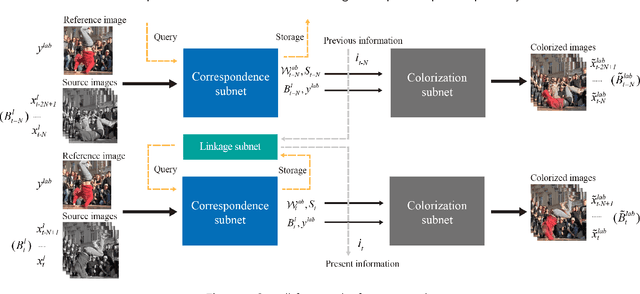

Exemplar-based video colorization is an essential technique for applications like old movie restoration. Although recent methods perform well in still scenes or scenes with regular movement, they always lack robustness in moving scenes due to their weak ability in modeling long-term dependency both spatially and temporally, leading to color fading, color discontinuity or other artifacts. To solve this problem, we propose an exemplar-based video colorization framework with long-term spatiotemporal dependency. To enhance the long-term spatial dependency, a parallelized CNN-Transformer block and a double head non-local operation are designed. The proposed CNN-Transformer block can better incorporate long-term spatial dependency with local texture and structural features, and the double head non-local operation further leverages the performance of augmented feature. While for long-term temporal dependency enhancement, we further introduce the novel linkage subnet. The linkage subnet propagate motion information across adjacent frame blocks and help to maintain temporal continuity. Experiments demonstrate that our model outperforms recent state-of-the-art methods both quantitatively and qualitatively. Also, our model can generate more colorful, realistic and stabilized results, especially for scenes where objects change greatly and irregularly.
PathSAGE: Spatial Graph Attention Neural Networks With Random Path Sampling
Mar 11, 2022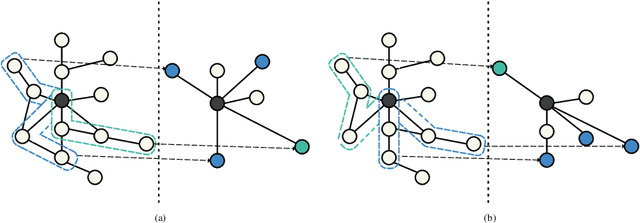

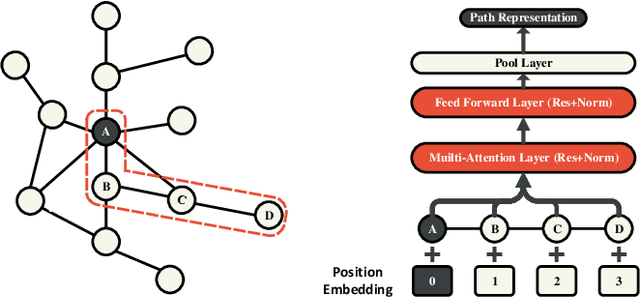

Graph Convolutional Networks (GCNs) achieve great success in non-Euclidean structure data processing recently. In existing studies, deeper layers are used in CCNs to extract deeper features of Euclidean structure data. However, for non-Euclidean structure data, too deep GCNs will confront with problems like "neighbor explosion" and "over-smoothing", it also cannot be applied to large datasets. To address these problems, we propose a model called PathSAGE, which can learn high-order topological information and improve the model's performance by expanding the receptive field. The model randomly samples paths starting from the central node and aggregates them by Transformer encoder. PathSAGE has only one layer of structure to aggregate nodes which avoid those problems above. The results of evaluation shows that our model achieves comparable performance with the state-of-the-art models in inductive learning tasks.