 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVISLIX: An XAI Framework for Validating Vision Models with Slice Discovery and Analysis
May 06, 2025Real-world machine learning models require rigorous evaluation before deployment, especially in safety-critical domains like autonomous driving and surveillance. The evaluation of machine learning models often focuses on data slices, which are subsets of the data that share a set of characteristics. Data slice finding automatically identifies conditions or data subgroups where models underperform, aiding developers in mitigating performance issues. Despite its popularity and effectiveness, data slicing for vision model validation faces several challenges. First, data slicing often needs additional image metadata or visual concepts, and falls short in certain computer vision tasks, such as object detection. Second, understanding data slices is a labor-intensive and mentally demanding process that heavily relies on the expert's domain knowledge. Third, data slicing lacks a human-in-the-loop solution that allows experts to form hypothesis and test them interactively. To overcome these limitations and better support the machine learning operations lifecycle, we introduce VISLIX, a novel visual analytics framework that employs state-of-the-art foundation models to help domain experts analyze slices in computer vision models. Our approach does not require image metadata or visual concepts, automatically generates natural language insights, and allows users to test data slice hypothesis interactively. We evaluate VISLIX with an expert study and three use cases, that demonstrate the effectiveness of our tool in providing comprehensive insights for validating object detection models.
InterChat: Enhancing Generative Visual Analytics using Multimodal Interactions
Mar 06, 2025



The rise of Large Language Models (LLMs) and generative visual analytics systems has transformed data-driven insights, yet significant challenges persist in accurately interpreting users' analytical and interaction intents. While language inputs offer flexibility, they often lack precision, making the expression of complex intents inefficient, error-prone, and time-intensive. To address these limitations, we investigate the design space of multimodal interactions for generative visual analytics through a literature review and pilot brainstorming sessions. Building on these insights, we introduce a highly extensible workflow that integrates multiple LLM agents for intent inference and visualization generation. We develop InterChat, a generative visual analytics system that combines direct manipulation of visual elements with natural language inputs. This integration enables precise intent communication and supports progressive, visually driven exploratory data analyses. By employing effective prompt engineering, and contextual interaction linking, alongside intuitive visualization and interaction designs, InterChat bridges the gap between user interactions and LLM-driven visualizations, enhancing both interpretability and usability. Extensive evaluations, including two usage scenarios, a user study, and expert feedback, demonstrate the effectiveness of InterChat. Results show significant improvements in the accuracy and efficiency of handling complex visual analytics tasks, highlighting the potential of multimodal interactions to redefine user engagement and analytical depth in generative visual analytics.
DeepVO: A Deep Learning approach for Monocular Visual Odometry
Nov 18, 2016

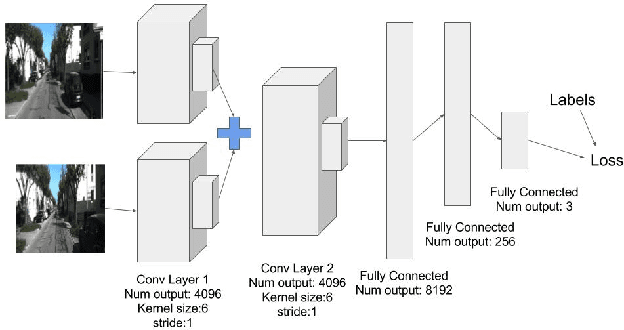

Deep Learning based techniques have been adopted with precision to solve a lot of standard computer vision problems, some of which are image classification, object detection and segmentation. Despite the widespread success of these approaches, they have not yet been exploited largely for solving the standard perception related problems encountered in autonomous navigation such as Visual Odometry (VO), Structure from Motion (SfM) and Simultaneous Localization and Mapping (SLAM). This paper analyzes the problem of Monocular Visual Odometry using a Deep Learning-based framework, instead of the regular 'feature detection and tracking' pipeline approaches. Several experiments were performed to understand the influence of a known/unknown environment, a conventional trackable feature and pre-trained activations tuned for object classification on the network's ability to accurately estimate the motion trajectory of the camera (or the vehicle). Based on these observations, we propose a Convolutional Neural Network architecture, best suited for estimating the object's pose under known environment conditions, and displays promising results when it comes to inferring the actual scale using just a single camera in real-time.