 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntity Augmentation for Efficient Classification of Vertically Partitioned Data with Limited Overlap
Jun 25, 2024Vertical Federated Learning (VFL) is a machine learning paradigm for learning from vertically partitioned data (i.e. features for each input are distributed across multiple "guest" clients and an aggregating "host" server owns labels) without communicating raw data. Traditionally, VFL involves an "entity resolution" phase where the host identifies and serializes the unique entities known to all guests. This is followed by private set intersection to find common entities, and an "entity alignment" step to ensure all guests are always processing the same entity's data. However, using only data of entities from the intersection means guests discard potentially useful data. Besides, the effect on privacy is dubious and these operations are computationally expensive. We propose a novel approach that eliminates the need for set intersection and entity alignment in categorical tasks. Our Entity Augmentation technique generates meaningful labels for activations sent to the host, regardless of their originating entity, enabling efficient VFL without explicit entity alignment. With limited overlap between training data, this approach performs substantially better (e.g. with 5% overlap, 48.1% vs 69.48% test accuracy on CIFAR-10). In fact, thanks to the regularizing effect, our model performs marginally better even with 100% overlap.
[Re] CLRNet: Cross Layer Refinement Network for Lane Detection
Oct 02, 2023The following work is a reproducibility report for CLRNet: Cross Layer Refinement Network for Lane Detection. The basic code was made available by the author. The paper proposes a novel Cross Layer Refinement Network to utilize both high and low level features for lane detection. The authors assert that the proposed technique sets the new state-of-the-art on three lane-detection benchmarks
Multiple Waypoint Navigation in Unknown Indoor Environments
Sep 18, 2022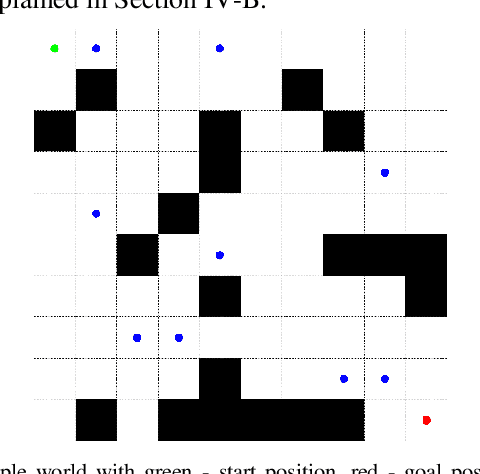
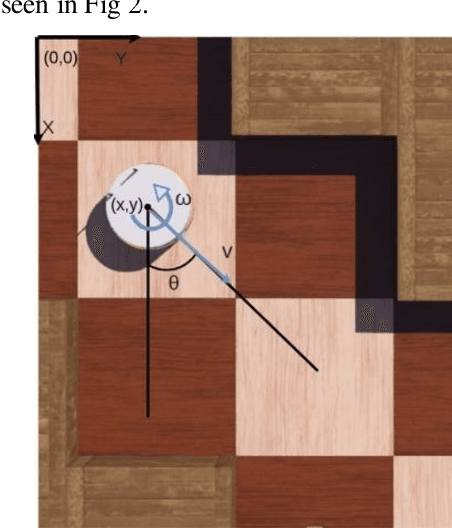
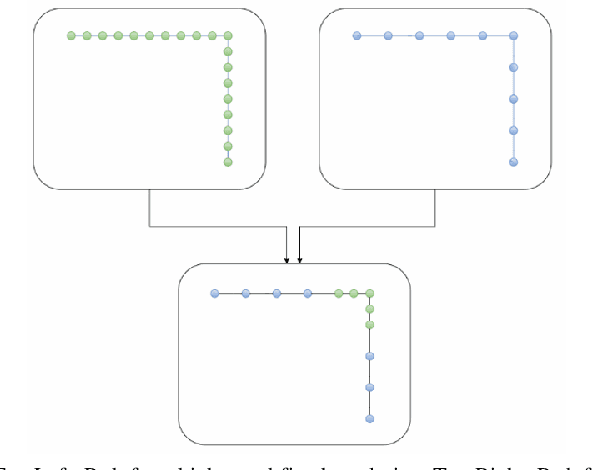
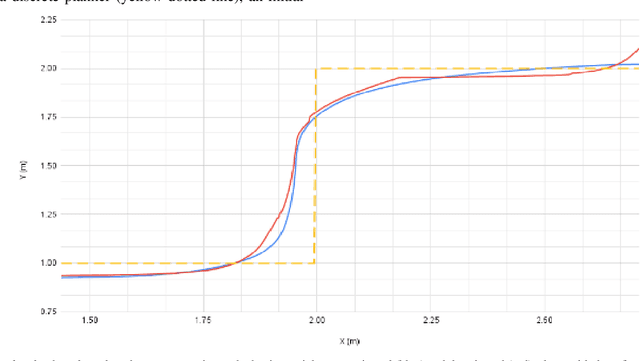
Indoor motion planning focuses on solving the problem of navigating an agent through a cluttered environment. To date, quite a lot of work has been done in this field, but these methods often fail to find the optimal balance between computationally inexpensive online path planning, and optimality of the path. Along with this, these works often prove optimality for single-start single-goal worlds. To address these challenges, we present a multiple waypoint path planner and controller stack for navigation in unknown indoor environments where waypoints include the goal along with the intermediary points that the robot must traverse before reaching the goal. Our approach makes use of a global planner (to find the next best waypoint at any instant), a local planner (to plan the path to a specific waypoint), and an adaptive Model Predictive Control strategy (for robust system control and faster maneuvers). We evaluate our algorithm on a set of randomly generated obstacle maps, intermediate waypoints, and start-goal pairs, with results indicating a significant reduction in computational costs, with high accuracies and robust control.
[Re] Differentiable Spatial Planning using Transformers
Aug 19, 2022![Figure 1 for [Re] Differentiable Spatial Planning using Transformers](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Ff52887523e4052a448b8dced56e196661b8109ea%2F4-Figure1-1.png&w=640&q=75)
![Figure 2 for [Re] Differentiable Spatial Planning using Transformers](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Ff52887523e4052a448b8dced56e196661b8109ea%2F5-Table1-1.png&w=640&q=75)
![Figure 3 for [Re] Differentiable Spatial Planning using Transformers](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Ff52887523e4052a448b8dced56e196661b8109ea%2F5-Figure2-1.png&w=640&q=75)
![Figure 4 for [Re] Differentiable Spatial Planning using Transformers](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Ff52887523e4052a448b8dced56e196661b8109ea%2F6-Table2-1.png&w=640&q=75)
This report covers our reproduction effort of the paper 'Differentiable Spatial Planning using Transformers' by Chaplot et al. . In this paper, the problem of spatial path planning in a differentiable way is considered. They show that their proposed method of using Spatial Planning Transformers outperforms prior data-driven models and leverages differentiable structures to learn mapping without a ground truth map simultaneously. We verify these claims by reproducing their experiments and testing their method on new data. We also investigate the stability of planning accuracy with maps with increased obstacle complexity. Efforts to investigate and verify the learnings of the Mapper module were met with failure stemming from a paucity of computational resources and unreachable authors.
Reproducibility Report: Contrastive Learning of Socially-aware Motion Representations
Aug 18, 2022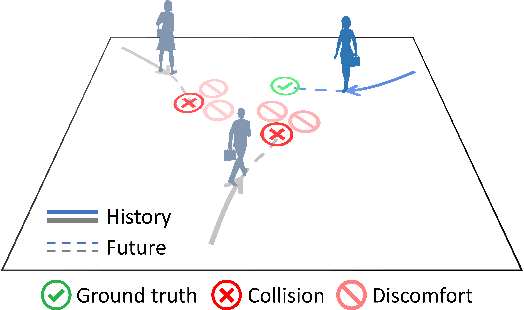


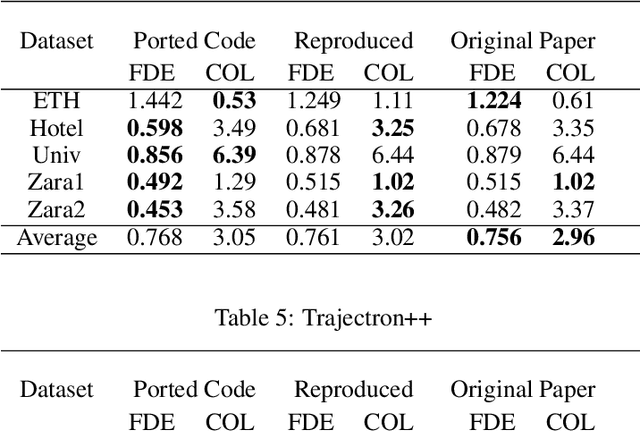
The following paper is a reproducibility report for "Social NCE: Contrastive Learning of Socially-aware Motion Representations" {\cite{liu2020snce}} published in ICCV 2021 as part of the ML Reproducibility Challenge 2021. The original code was made available by the author \footnote{\href{https://github.com/vita-epfl/social-nce}{https://github.com/vita-epfl/social-nce}}. We attempted to verify the results claimed by the authors and reimplemented their code in PyTorch Lightning.
Local NMPC on Global Optimised Path for Autonomous Racing
Sep 15, 2021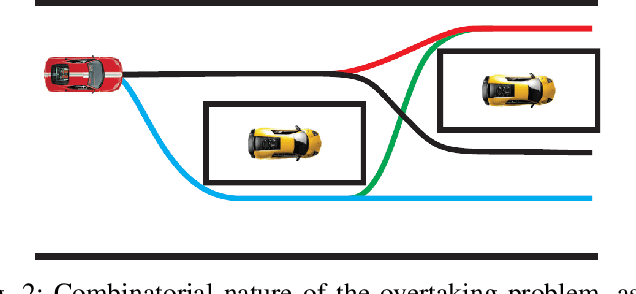
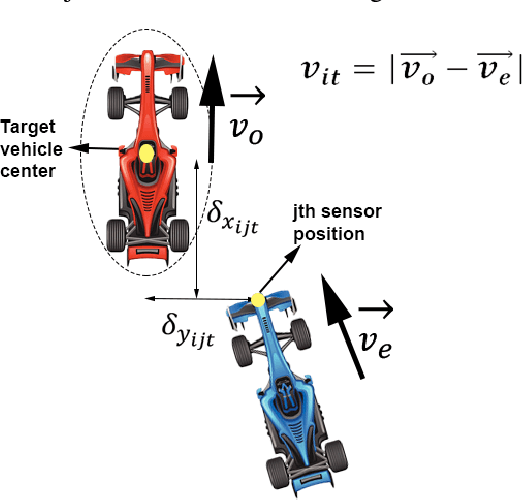


The paper presents a strategy for the control of anautonomous racing car on a pre-mapped track. Using a dynamic model of the vehicle, the optimal racing line is computed, taking track boundaries into account. With the optimal racing line as areference, a local nonlinear model predictive controller (NMPC) is proposed, which takes into account multiple local objectives like making more progress along the race line, avoiding collision with opponent vehicles, and use of drafting to achieve more progress.
Reproducibility of "FDA: Fourier Domain Adaptation forSemantic Segmentation
Apr 30, 2021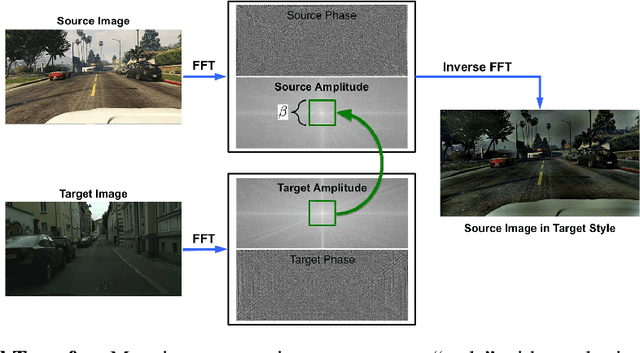
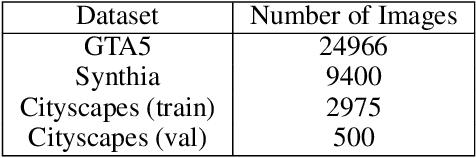

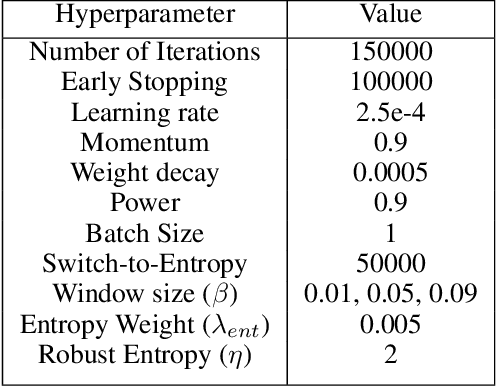
The following paper is a reproducibility report for "FDA: Fourier Domain Adaptation for Semantic Segmentation" published in the CVPR 2020 as part of the ML Reproducibility Challenge 2020. The original code was made available by the author. The well-commented version of the code containing all ablation studies performed derived from the original code along with WANDB integration is available at <github.com/thefatbandit/FDA> with proper instructions to execute experiments in README.
Design and Implementation of Path Trackers for Ackermann Drive based Vehicles
Dec 05, 2020
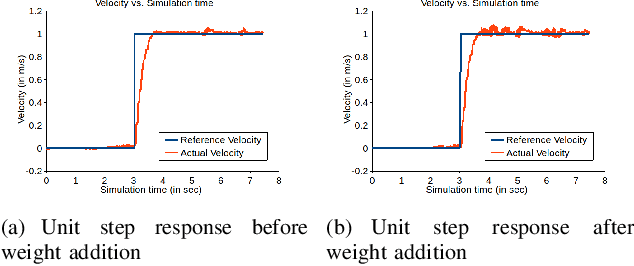
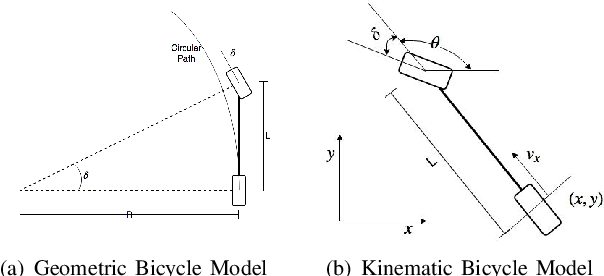
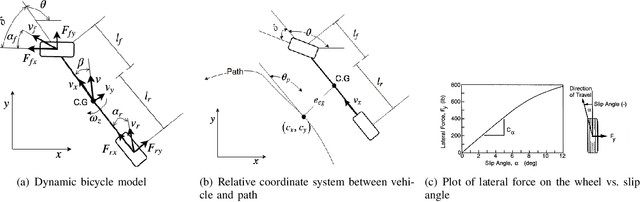
This article is an overview of the various literature on path tracking methods and their implementation in simulation and realistic operating environments.The scope of this study includes analysis, implementation,tuning, and comparison of some selected path tracking methods commonly used in practice for trajectory tracking in autonomous vehicles. Many of these methods are applicable at low speed due to the linear assumption for the system model, and hence, some methods are also included that consider nonlinearities present in lateral vehicle dynamics during high-speed navigation. The performance evaluation and comparison of tracking methods are carried out on realistic simulations and a dedicated instrumented passenger car, Mahindra e2o, to get a performance idea of all the methods in realistic operating conditions and develop tuning methodologies for each of the methods. It has been observed that our model predictive control-based approach is able to perform better compared to the others in medium velocity ranges.
Modeling and Control of an Autonomous Three Wheeled Mobile Robot with Front Steer
Dec 05, 2016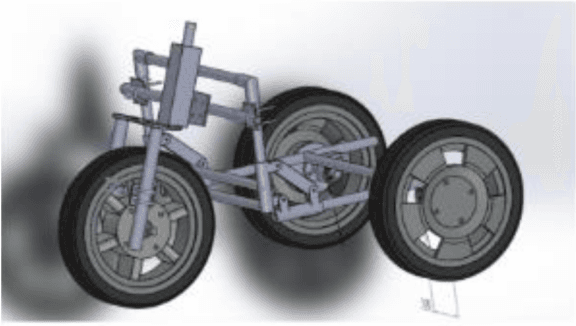
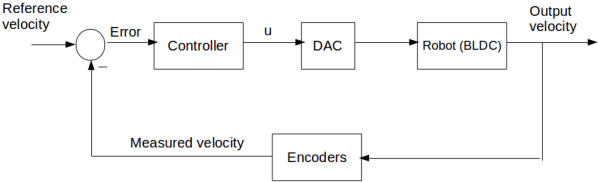
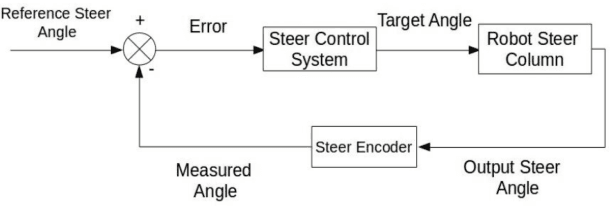
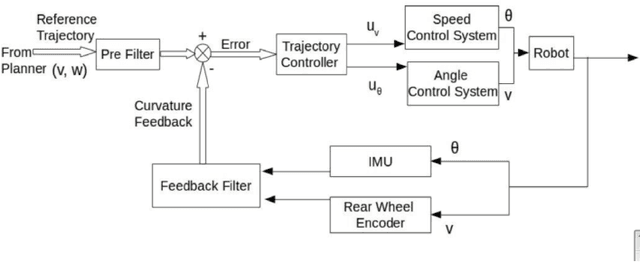
Modeling and control strategies for a design of an autonomous three wheeled mobile robot with front wheel steer is presented. Although, the three-wheel vehicle design with front wheel steer is common in automotive vehicles used often in public transport, but its advantages in navigation and localization of autonomous vehicles is seldom utilized. We present the system model for such a robotic vehicle. A PID controller for speed control is designed for the model obtained and has been implemented in a digital control framework. The trajectory control framework, which is a challenging task for such a three-wheeled robot has also been presented in the paper. The derived system model has been verified using experimental results obtained for the robot vehicle design. Controller performance and robustness issues have also been discussed briefly.
DeepVO: A Deep Learning approach for Monocular Visual Odometry
Nov 18, 2016

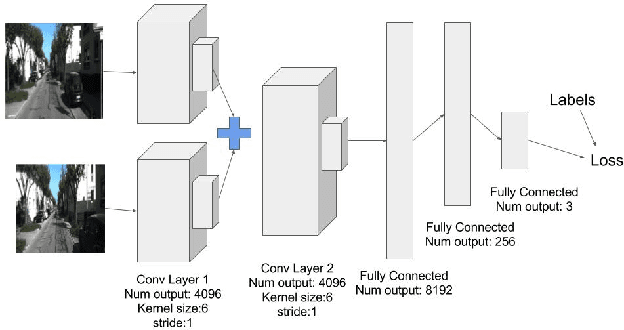

Deep Learning based techniques have been adopted with precision to solve a lot of standard computer vision problems, some of which are image classification, object detection and segmentation. Despite the widespread success of these approaches, they have not yet been exploited largely for solving the standard perception related problems encountered in autonomous navigation such as Visual Odometry (VO), Structure from Motion (SfM) and Simultaneous Localization and Mapping (SLAM). This paper analyzes the problem of Monocular Visual Odometry using a Deep Learning-based framework, instead of the regular 'feature detection and tracking' pipeline approaches. Several experiments were performed to understand the influence of a known/unknown environment, a conventional trackable feature and pre-trained activations tuned for object classification on the network's ability to accurately estimate the motion trajectory of the camera (or the vehicle). Based on these observations, we propose a Convolutional Neural Network architecture, best suited for estimating the object's pose under known environment conditions, and displays promising results when it comes to inferring the actual scale using just a single camera in real-time.