 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwift Sampling: Selecting Temporal Surprises via Taylor Series
May 21, 2026While most frames in long-form video are redundant, the critical information resides in temporal surprises: moments where the actual visual features deviate from their predicted evolution. Inspired by the human brain's predictive coding, we introduce Swift Sampling, an elegant, training-free frame selection algorithm that automatically identifies high-information moments in a video. Specifically, we model a video as a differentiable trajectory in the visual latent space and compute the velocity and acceleration of its features. Then, we apply Taylor expansion to project the expected path of subsequent frames. Frames that diverge sharply from this predicted manifold are identified as temporally surprising frames and selected for sampling. Unlike prior training-free methods that rely on auxiliary networks or video-specific hyperparameter tuning, Swift Sampling is incredibly lightweight, adding only 0.02x additional computational cost over baseline making it 30x cheaper overhead than leading baselines. Across three long-video question answering benchmarks and 10 different downstream tasks, Swift Sampling outperforms uniform sampling and prior query-agnostic baselines. It is especially powerful for long videos with limited frame budgets improving accuracy by up to +12.5 points.
Decoding Attention from Gaze: A Benchmark Dataset and End-to-End Models
Nov 20, 2022

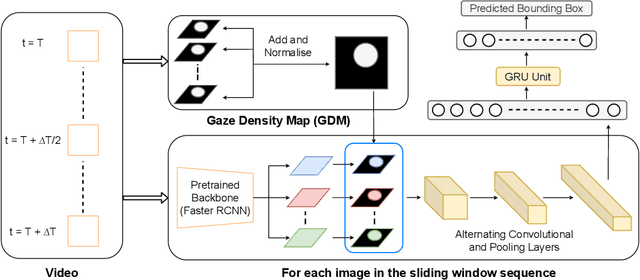
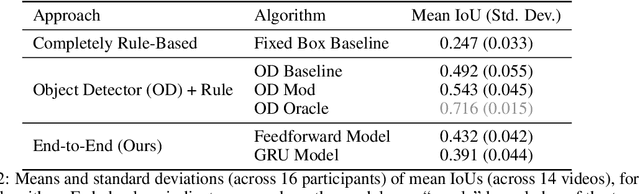
Eye-tracking has potential to provide rich behavioral data about human cognition in ecologically valid environments. However, analyzing this rich data is often challenging. Most automated analyses are specific to simplistic artificial visual stimuli with well-separated, static regions of interest, while most analyses in the context of complex visual stimuli, such as most natural scenes, rely on laborious and time-consuming manual annotation. This paper studies using computer vision tools for "attention decoding", the task of assessing the locus of a participant's overt visual attention over time. We provide a publicly available Multiple Object Eye-Tracking (MOET) dataset, consisting of gaze data from participants tracking specific objects, annotated with labels and bounding boxes, in crowded real-world videos, for training and evaluating attention decoding algorithms. We also propose two end-to-end deep learning models for attention decoding and compare these to state-of-the-art heuristic methods.
Multiple Waypoint Navigation in Unknown Indoor Environments
Sep 18, 2022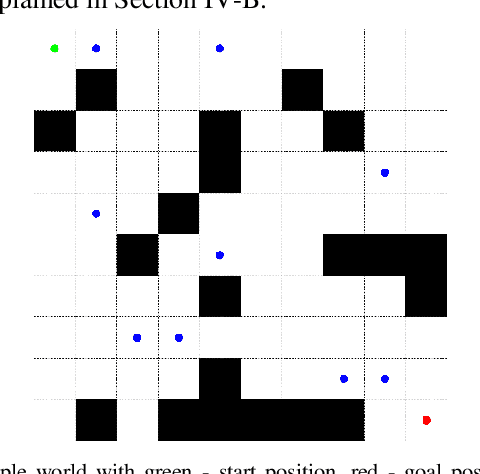
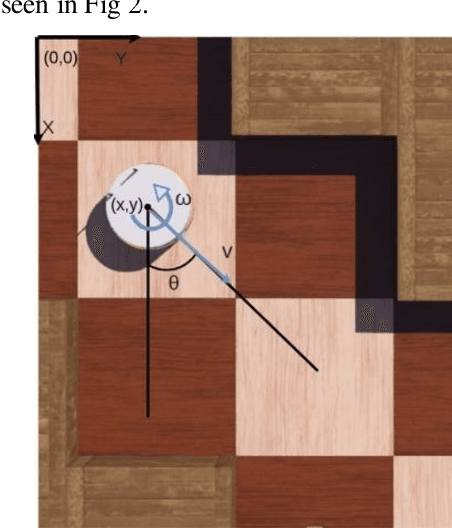
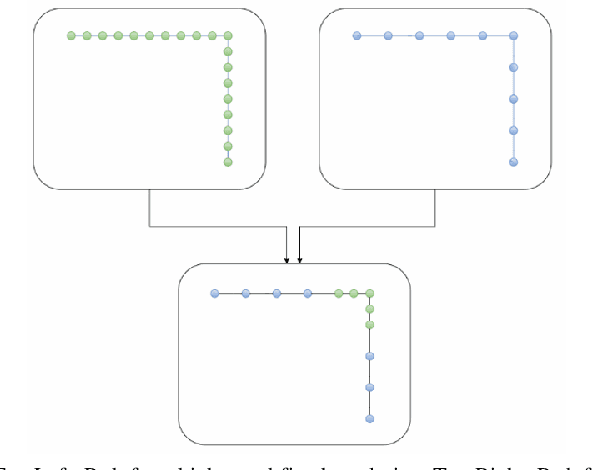
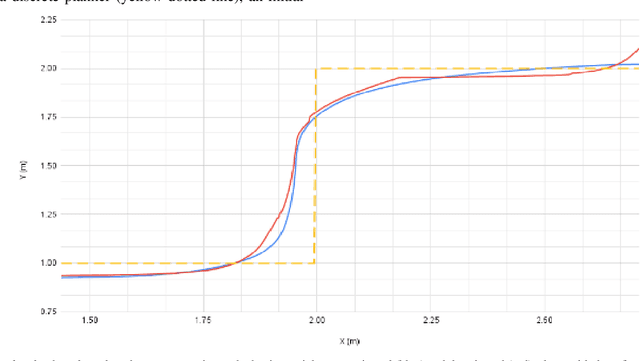
Indoor motion planning focuses on solving the problem of navigating an agent through a cluttered environment. To date, quite a lot of work has been done in this field, but these methods often fail to find the optimal balance between computationally inexpensive online path planning, and optimality of the path. Along with this, these works often prove optimality for single-start single-goal worlds. To address these challenges, we present a multiple waypoint path planner and controller stack for navigation in unknown indoor environments where waypoints include the goal along with the intermediary points that the robot must traverse before reaching the goal. Our approach makes use of a global planner (to find the next best waypoint at any instant), a local planner (to plan the path to a specific waypoint), and an adaptive Model Predictive Control strategy (for robust system control and faster maneuvers). We evaluate our algorithm on a set of randomly generated obstacle maps, intermediate waypoints, and start-goal pairs, with results indicating a significant reduction in computational costs, with high accuracies and robust control.
Reproducibility of "FDA: Fourier Domain Adaptation forSemantic Segmentation
Apr 30, 2021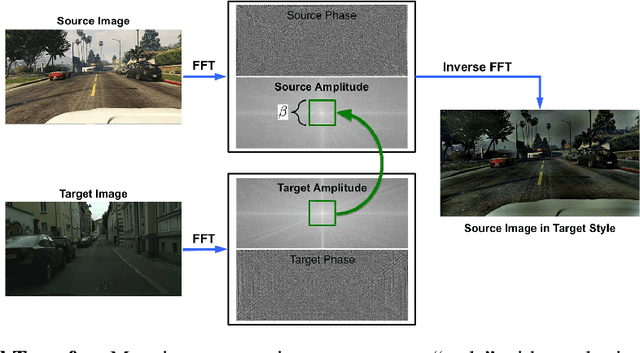
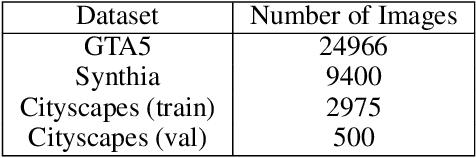

The following paper is a reproducibility report for "FDA: Fourier Domain Adaptation for Semantic Segmentation" published in the CVPR 2020 as part of the ML Reproducibility Challenge 2020. The original code was made available by the author. The well-commented version of the code containing all ablation studies performed derived from the original code along with WANDB integration is available at <github.com/thefatbandit/FDA> with proper instructions to execute experiments in README.
Suggestion Mining from Online Reviews using ULMFiT
Apr 19, 2019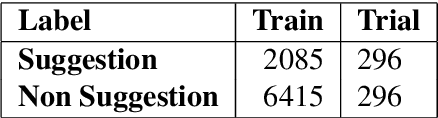
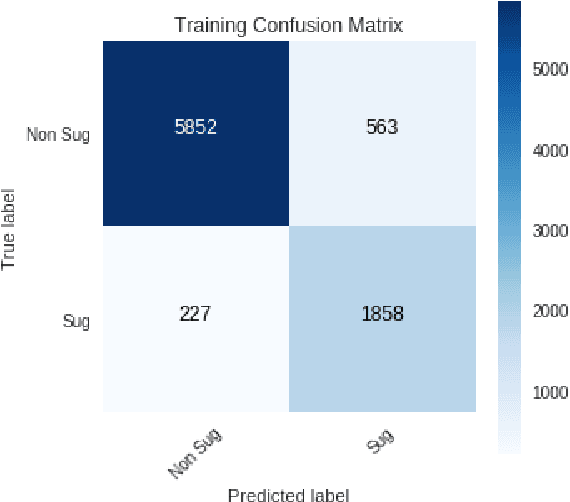

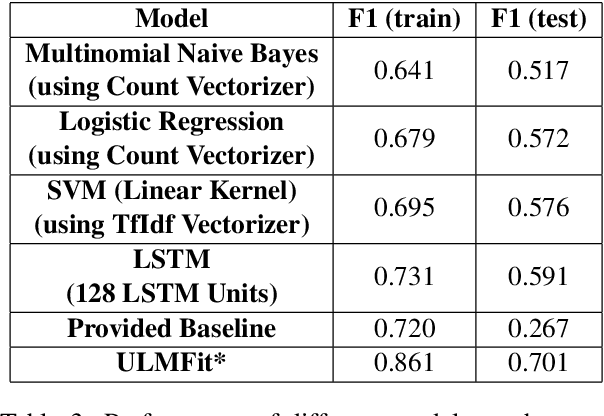
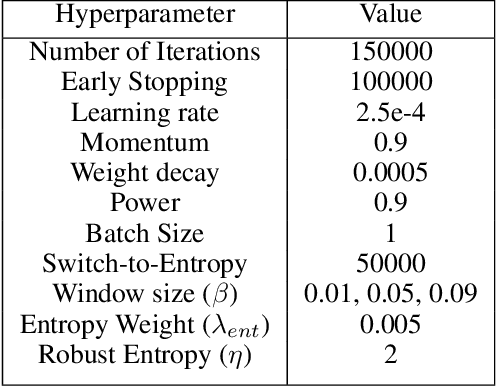
In this paper we present our approach and the system description for Sub Task A of SemEval 2019 Task 9: Suggestion Mining from Online Reviews and Forums. Given a sentence, the task asks to predict whether the sentence consists of a suggestion or not. Our model is based on Universal Language Model Fine-tuning for Text Classification. We apply various pre-processing techniques before training the language and the classification model. We further provide detailed analysis of the results obtained using the trained model. Our team ranked 10th out of 34 participants, achieving an F1 score of 0.7011. We publicly share our implementation at https://github.com/isarth/SemEval9_MIDAS
Identifying Offensive Posts and Targeted Offense from Twitter
Apr 19, 2019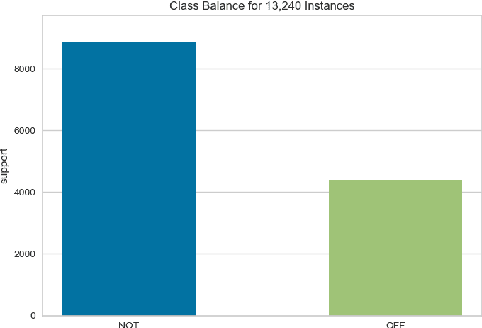

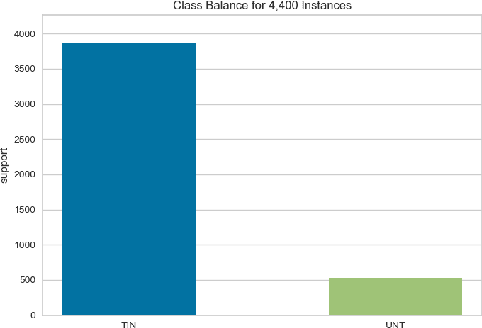
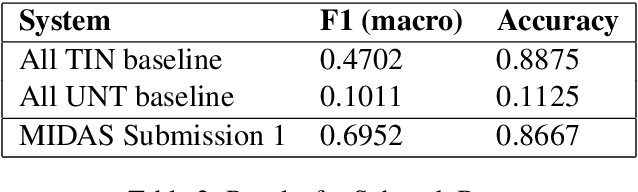
In this paper we present our approach and the system description for Sub-task A and Sub Task B of SemEval 2019 Task 6: Identifying and Categorizing Offensive Language in Social Media. Sub-task A involves identifying if a given tweet is offensive or not, and Sub Task B involves detecting if an offensive tweet is targeted towards someone (group or an individual). Our models for Sub-task A is based on an ensemble of Convolutional Neural Network, Bidirectional LSTM with attention, and Bidirectional LSTM + Bidirectional GRU, whereas for Sub-task B, we rely on a set of heuristics derived from the training data and manual observation. We provide detailed analysis of the results obtained using the trained models. Our team ranked 5th out of 103 participants in Sub-task A, achieving a macro F1 score of 0.807, and ranked 8th out of 75 participants in Sub Task B achieving a macro F1 of 0.695.