 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoding Attention from Gaze: A Benchmark Dataset and End-to-End Models
Nov 20, 2022

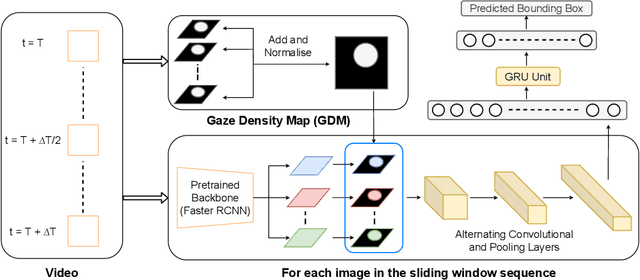
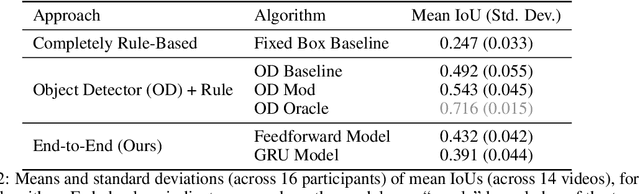
Eye-tracking has potential to provide rich behavioral data about human cognition in ecologically valid environments. However, analyzing this rich data is often challenging. Most automated analyses are specific to simplistic artificial visual stimuli with well-separated, static regions of interest, while most analyses in the context of complex visual stimuli, such as most natural scenes, rely on laborious and time-consuming manual annotation. This paper studies using computer vision tools for "attention decoding", the task of assessing the locus of a participant's overt visual attention over time. We provide a publicly available Multiple Object Eye-Tracking (MOET) dataset, consisting of gaze data from participants tracking specific objects, annotated with labels and bounding boxes, in crowded real-world videos, for training and evaluating attention decoding algorithms. We also propose two end-to-end deep learning models for attention decoding and compare these to state-of-the-art heuristic methods.