 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepVO: A Deep Learning approach for Monocular Visual Odometry
Paper and Code
Nov 18, 2016

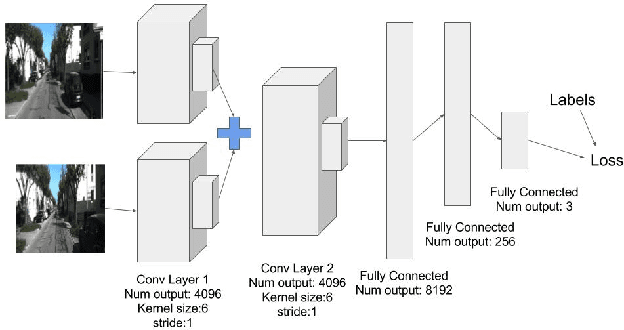

Deep Learning based techniques have been adopted with precision to solve a lot of standard computer vision problems, some of which are image classification, object detection and segmentation. Despite the widespread success of these approaches, they have not yet been exploited largely for solving the standard perception related problems encountered in autonomous navigation such as Visual Odometry (VO), Structure from Motion (SfM) and Simultaneous Localization and Mapping (SLAM). This paper analyzes the problem of Monocular Visual Odometry using a Deep Learning-based framework, instead of the regular 'feature detection and tracking' pipeline approaches. Several experiments were performed to understand the influence of a known/unknown environment, a conventional trackable feature and pre-trained activations tuned for object classification on the network's ability to accurately estimate the motion trajectory of the camera (or the vehicle). Based on these observations, we propose a Convolutional Neural Network architecture, best suited for estimating the object's pose under known environment conditions, and displays promising results when it comes to inferring the actual scale using just a single camera in real-time.