 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced Robot Planning and Perception through Environment Prediction
Oct 11, 2024Mobile robots rely on maps to navigate through an environment. In the absence of any map, the robots must build the map online from partial observations as they move in the environment. Traditional methods build a map using only direct observations. In contrast, humans identify patterns in the observed environment and make informed guesses about what to expect ahead. Modeling these patterns explicitly is difficult due to the complexity of the environments. However, these complex models can be approximated well using learning-based methods in conjunction with large training data. By extracting patterns, robots can use direct observations and predictions of what lies ahead to better navigate an unknown environment. In this dissertation, we present several learning-based methods to equip mobile robots with prediction capabilities for efficient and safer operation. In the first part of the dissertation, we learn to predict using geometrical and structural patterns in the environment. Partially observed maps provide invaluable cues for accurately predicting the unobserved areas. We first demonstrate the capability of general learning-based approaches to model these patterns for a variety of overhead map modalities. Then we employ task-specific learning for faster navigation in indoor environments by predicting 2D occupancy in the nearby regions. This idea is further extended to 3D point cloud representation for object reconstruction. Predicting the shape of the full object from only partial views, our approach paves the way for efficient next-best-view planning. In the second part of the dissertation, we learn to predict using spatiotemporal patterns in the environment. We focus on dynamic tasks such as target tracking and coverage where we seek decentralized coordination between robots. We first show how graph neural networks can be used for more scalable and faster inference.
Is Generative Communication between Embodied Agents Good for Zero-Shot ObjectNav?
Aug 03, 2024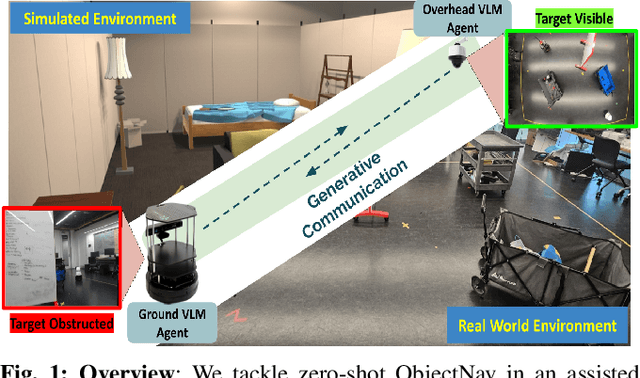
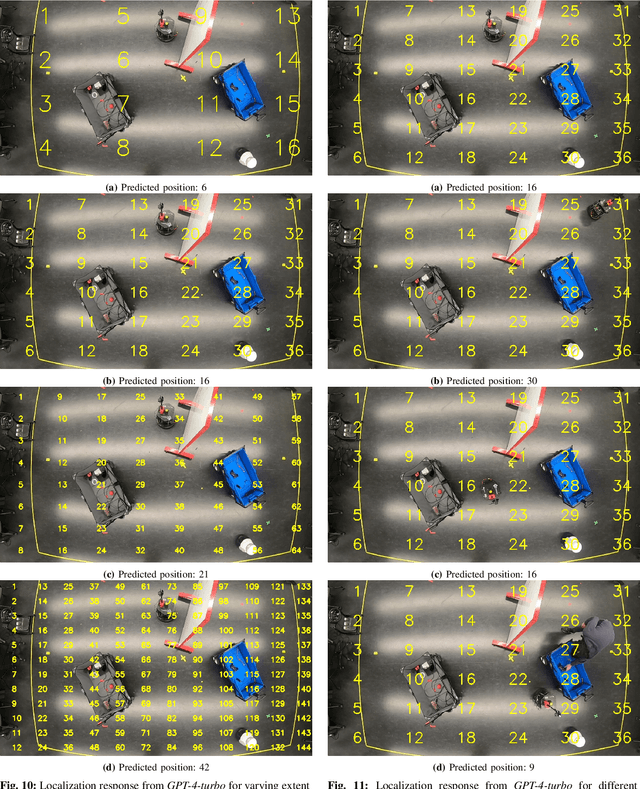


In Zero-Shot ObjectNav, an embodied ground agent is expected to navigate to a target object specified by a natural language label without any environment-specific fine-tuning. This is challenging, given the limited view of a ground agent and its independent exploratory behavior. To address these issues, we consider an assistive overhead agent with a bounded global view alongside the ground agent and present two coordinated navigation schemes for judicious exploration. We establish the influence of the Generative Communication (GC) between the embodied agents equipped with Vision-Language Models (VLMs) in improving zero-shot ObjectNav, achieving a 10% improvement in the ground agent's ability to find the target object in comparison with an unassisted setup in simulation. We further analyze the GC for unique traits quantifying the presence of hallucination and cooperation. In particular, we identify a unique trait of "preemptive hallucination" specific to our embodied setting, where the overhead agent assumes that the ground agent has executed an action in the dialogue when it is yet to move. Finally, we conduct real-world inferences with GC and showcase qualitative examples where countering pre-emptive hallucination via prompt finetuning improves real-world ObjectNav performance.
Pre-Trained Masked Image Model for Mobile Robot Navigation
Oct 10, 20232D top-down maps are commonly used for the navigation and exploration of mobile robots through unknown areas. Typically, the robot builds the navigation maps incrementally from local observations using onboard sensors. Recent works have shown that predicting the structural patterns in the environment through learning-based approaches can greatly enhance task efficiency. While many such works build task-specific networks using limited datasets, we show that the existing foundational vision networks can accomplish the same without any fine-tuning. Specifically, we use Masked Autoencoders, pre-trained on street images, to present novel applications for field-of-view expansion, single-agent topological exploration, and multi-agent exploration for indoor mapping, across different input modalities. Our work motivates the use of foundational vision models for generalized structure prediction-driven applications, especially in the dearth of training data. For more qualitative results see https://raaslab.org/projects/MIM4Robots.
ProxMaP: Proximal Occupancy Map Prediction for Efficient Indoor Robot Navigation
May 10, 2023In a typical path planning pipeline for a ground robot, we build a map (e.g., an occupancy grid) of the environment as the robot moves around. While navigating indoors, a ground robot's knowledge about the environment may be limited due to occlusions. Therefore, the map will have many as-yet-unknown regions that may need to be avoided by a conservative planner. Instead, if a robot is able to correctly predict what its surroundings and occluded regions look like, the robot may be more efficient in navigation. In this work, we focus on predicting occupancy within the reachable distance of the robot to enable faster navigation and present a self-supervised proximity occupancy map prediction method, named ProxMaP. We show that ProxMaP generalizes well across realistic and real domains, and improves the robot navigation efficiency in simulation by \textbf{$12.40\%$} against the traditional navigation method. We share our findings on our project webpage (see https://raaslab.org/projects/ProxMaP ).
Interpretable Deep Reinforcement Learning for Green Security Games with Real-Time Information
Nov 09, 2022



Green Security Games with real-time information (GSG-I) add the real-time information about the agents' movement to the typical GSG formulation. Prior works on GSG-I have used deep reinforcement learning (DRL) to learn the best policy for the agent in such an environment without any need to store the huge number of state representations for GSG-I. However, the decision-making process of DRL methods is largely opaque, which results in a lack of trust in their predictions. To tackle this issue, we present an interpretable DRL method for GSG-I that generates visualization to explain the decisions taken by the DRL algorithm. We also show that this approach performs better and works well with a simpler training regimen compared to the existing method.
D2CoPlan: A Differentiable Decentralized Planner for Multi-Robot Coverage
Sep 19, 2022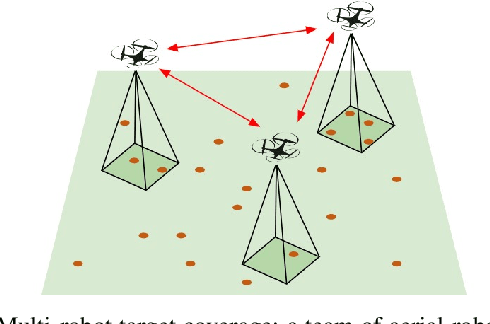
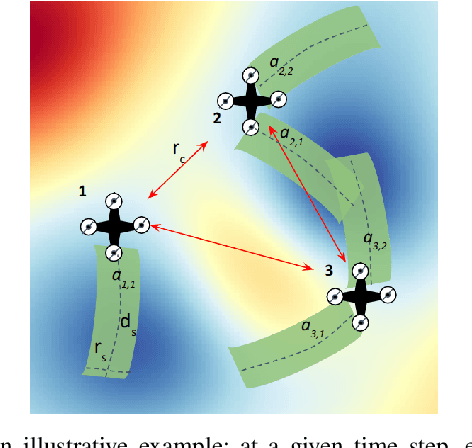
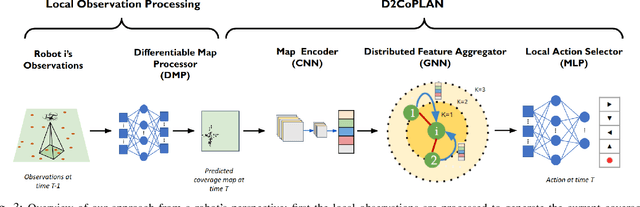
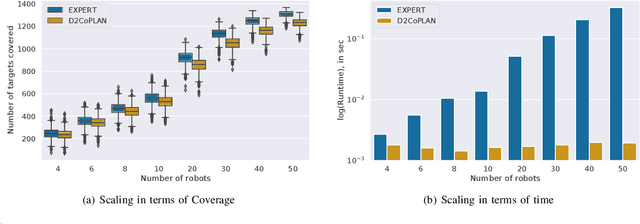
Centralized approaches for multi-robot coverage planning problems suffer from the lack of scalability. Learning-based distributed algorithms provide a scalable avenue in addition to bringing data-oriented feature generation capabilities to the table, allowing integration with other learning-based approaches. To this end, we present a learning-based, differentiable distributed coverage planner (D2COPL A N) which scales efficiently in runtime and number of agents compared to the expert algorithm, and performs on par with the classical distributed algorithm. In addition, we show that D2COPlan can be seamlessly combined with other learning methods to learn end-to-end, resulting in a better solution than the individually trained modules, opening doors to further research for tasks that remain elusive with classical methods.
Occupancy Map Prediction for Improved Indoor Robot Navigation
Mar 08, 2022

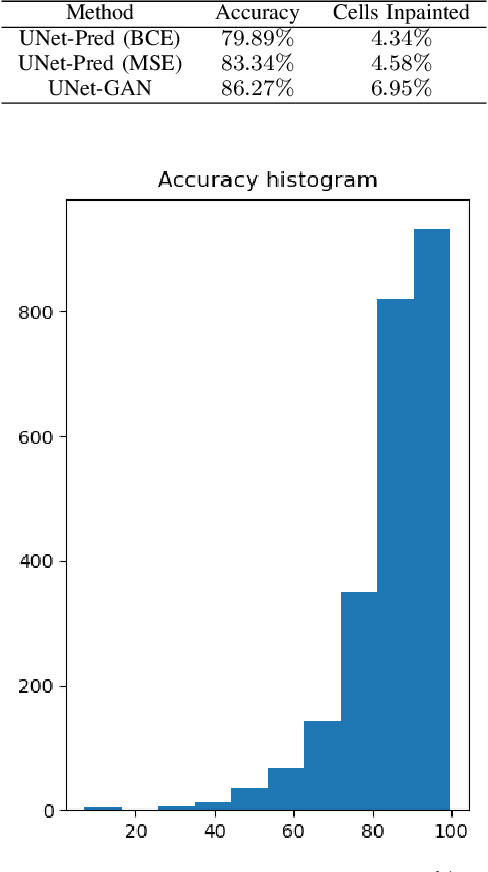
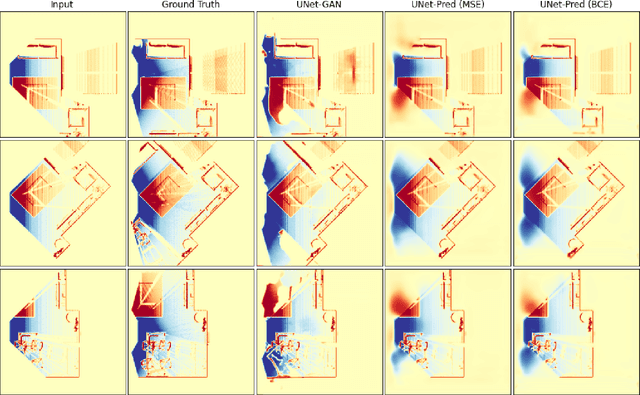
In the typical path planning pipeline for a ground robot, we build a map (e.g., an occupancy grid) of the environment as the robot moves around. While navigating indoors, a ground robot's knowledge about the environment may be limited by the occlusions in its surroundings. Therefore, the map will have many as-yet-unknown regions that may need to be avoided by a conservative planner. Instead, if a robot is able to correctly infer what its surroundings and occluded regions look like, the navigation can be further optimized. In this work, we propose an approach using pix2pix and UNet to infer the occupancy grid in unseen areas near the robot as an image-to-image translation task. Our approach simplifies the task of occupancy map prediction for the deep learning network and reduces the amount of data required compared to similar existing methods. We show that the predicted map improves the navigation time in simulations over the existing approaches.
Risk-Aware Path Planning for Ground Vehicles using Occluded Aerial Images
Apr 23, 2021
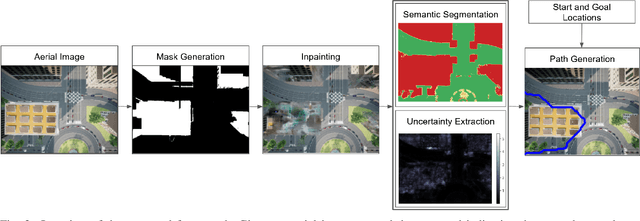
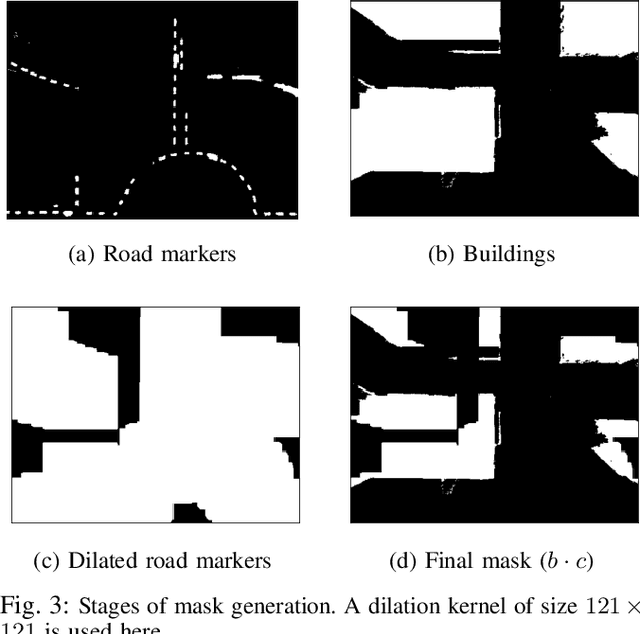
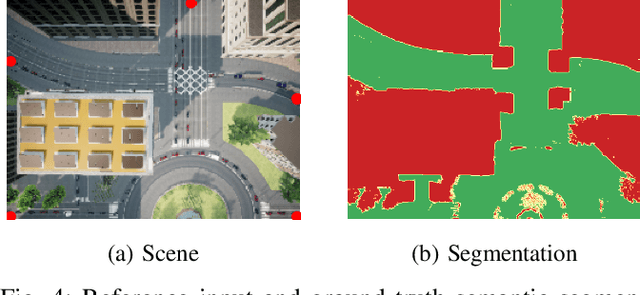
We consider scenarios where a ground vehicle plans its path using data gathered by an aerial vehicle. In the aerial images, navigable areas of the scene may be occluded due to obstacles. Naively planning paths using aerial images may result in longer paths as a conservative planner may try to avoid regions that are occluded. We propose a modular, deep learning-based framework that allows the robot to predict the existence of navigable areas in the occluded regions. Specifically, we use image inpainting methods to fill in parts of the areas that are potentially occluded, which can then be semantically segmented to determine navigability. We use supervised neural networks for both modules. However, these predictions may be incorrect. Therefore, we extract uncertainty in these predictions and use a risk-aware approach that takes these uncertainties into account for path planning. We compare modules in our approach with non-learning-based approaches to show the efficacy of the proposed framework through photo-realistic simulations. The modular pipeline allows further improvement in path planning and deployment in different settings.
Free as in Free Word Order: An Energy Based Model for Word Segmentation and Morphological Tagging in Sanskrit
Oct 25, 2018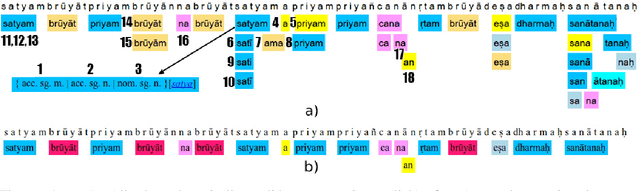
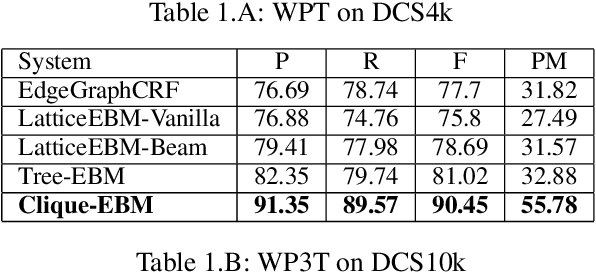
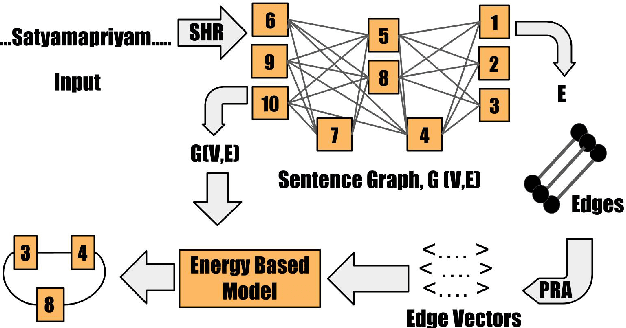
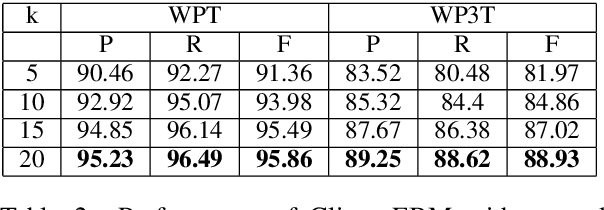
The configurational information in sentences of a free word order language such as Sanskrit is of limited use. Thus, the context of the entire sentence will be desirable even for basic processing tasks such as word segmentation. We propose a structured prediction framework that jointly solves the word segmentation and morphological tagging tasks in Sanskrit. We build an energy based model where we adopt approaches generally employed in graph based parsing techniques (McDonald et al., 2005a; Carreras, 2007). Our model outperforms the state of the art with an F-Score of 96.92 (percentage improvement of 7.06%) while using less than one-tenth of the task-specific training data. We find that the use of a graph based ap- proach instead of a traditional lattice-based sequential labelling approach leads to a percentage gain of 12.6% in F-Score for the segmentation task.
Building a Word Segmenter for Sanskrit Overnight
Feb 17, 2018
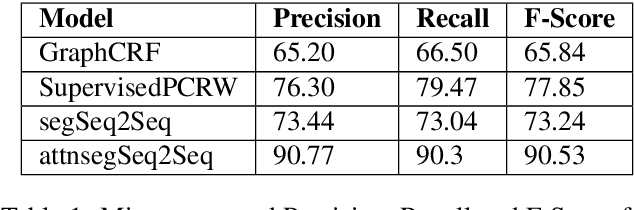
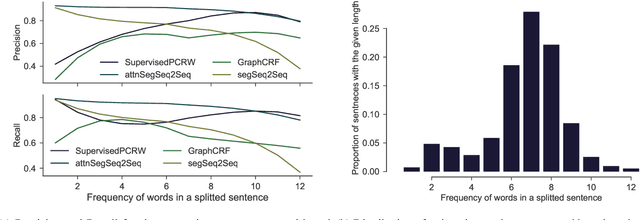
There is an abundance of digitised texts available in Sanskrit. However, the word segmentation task in such texts are challenging due to the issue of 'Sandhi'. In Sandhi, words in a sentence often fuse together to form a single chunk of text, where the word delimiter vanishes and sounds at the word boundaries undergo transformations, which is also reflected in the written text. Here, we propose an approach that uses a deep sequence to sequence (seq2seq) model that takes only the sandhied string as the input and predicts the unsandhied string. The state of the art models are linguistically involved and have external dependencies for the lexical and morphological analysis of the input. Our model can be trained "overnight" and be used for production. In spite of the knowledge lean approach, our system preforms better than the current state of the art by gaining a percentage increase of 16.79 % than the current state of the art.