 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't Ask the LLM to Track Freshness: A Deterministic Recipe for Memory Conflict Resolution
May 31, 2026LLM-based memory systems increasingly maintain facts that evolve over time, where a recurring failure is conflict resolution: when a fact has multiple contradictory values, which should the agent return? MemoryAgentBench (MAB; Hu et al., 2026) makes this explicit in its FactConsolidation task: facts are numbered, the counterfactual has the higher serial, and agents are told newer facts have larger serials. Yet every published system underperforms: HippoRAG-v2 reaches 54% on single-hop (FC-SH), BM25 48%, Mem0 18%, and the temporal KG Zep/Graphiti just 7%. Multi-hop is near-unsolved (at most 7% across 22 systems). We argue the bottleneck is the assembly step: baselines leave conflict resolution to LLM-mediated retrieval or generation rather than version-aware aggregation. A matched-setup comparison (same backbone, retrieval, chunking, TOP_K) shows that replacing the LLM-judgment answer pipeline with candidate-extraction plus Python max(serial) yields +10.8 points on FC-SH (gpt-4o-mini), widening from +8 at 6K to +21 at 262K. This is a whole-pipeline effect (resolver, prompt, format, and temperature vary jointly); isolating the resolver is future work. The recipe reaches 78.0% on FC-SH (gpt-4o-mini), 94.8% (gpt-4o), and 30.2% on FC-MH (gpt-4o-mini, rising to 51.5% with gpt-4o) via a per-hop deterministic extension of Self-Ask. At matched-262K, it beats HippoRAG-v2 by +28 points and the best published FC-MH result by +20. The implication is corrective for the subfield: the bottleneck on conflict resolution is assembly (post-retrieval aggregation), not storage. A LongMemEval knowledge-update check shows the mechanism ports from max(serial) to max(timestamp) but only ties LLM judgment (57.8% vs 64.4%, n=45): deterministic aggregation is the right primitive for current-value conflicts and must be composed with question-type-aware handling for broader memory QA.
Building a Word Segmenter for Sanskrit Overnight
Feb 17, 2018
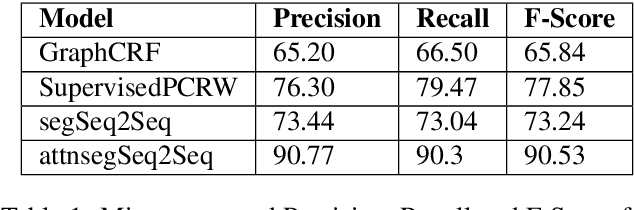
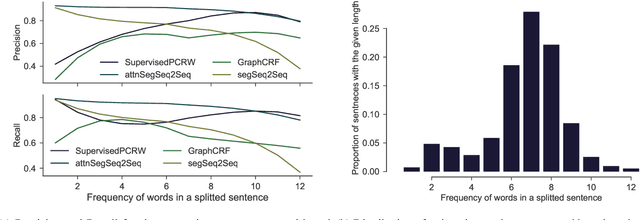
There is an abundance of digitised texts available in Sanskrit. However, the word segmentation task in such texts are challenging due to the issue of 'Sandhi'. In Sandhi, words in a sentence often fuse together to form a single chunk of text, where the word delimiter vanishes and sounds at the word boundaries undergo transformations, which is also reflected in the written text. Here, we propose an approach that uses a deep sequence to sequence (seq2seq) model that takes only the sandhied string as the input and predicts the unsandhied string. The state of the art models are linguistically involved and have external dependencies for the lexical and morphological analysis of the input. Our model can be trained "overnight" and be used for production. In spite of the knowledge lean approach, our system preforms better than the current state of the art by gaining a percentage increase of 16.79 % than the current state of the art.
Visualization Regularizers for Neural Network based Image Recognition
Jan 03, 2017
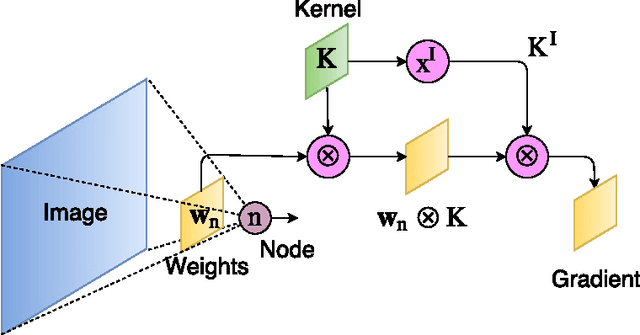

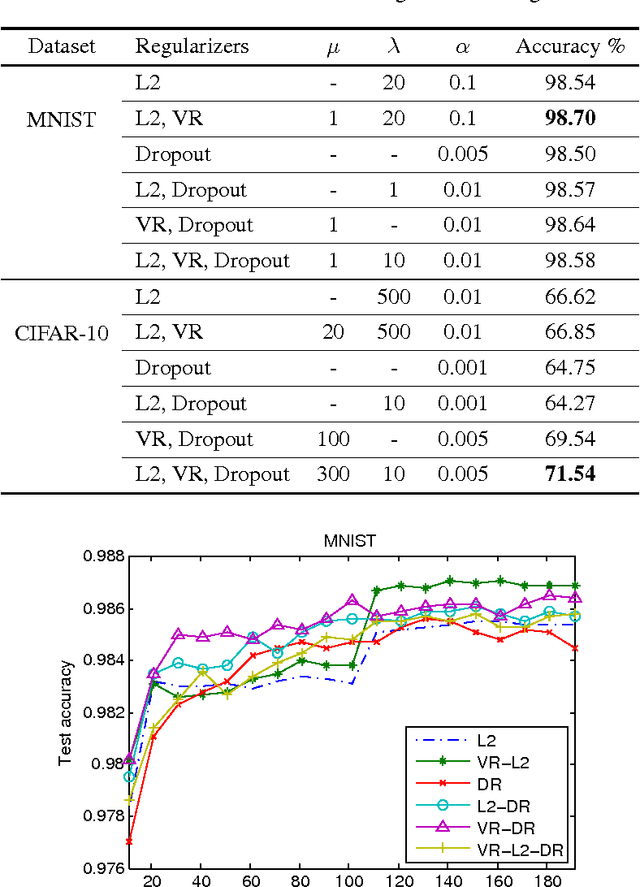
The success of deep neural networks is mostly due their ability to learn meaningful features from the data. Features learned in the hidden layers of deep neural networks trained in computer vision tasks have been shown to be similar to mid-level vision features. We leverage this fact in this work and propose the visualization regularizer for image tasks. The proposed regularization technique enforces smoothness of the features learned by hidden nodes and turns out to be a special case of Tikhonov regularization. We achieve higher classification accuracy as compared to existing regularizers such as the L2 norm regularizer and dropout, on benchmark datasets without changing the training computational complexity.
MRF-based Background Initialisation for Improved Foreground Detection in Cluttered Surveillance Videos
Jun 19, 2014

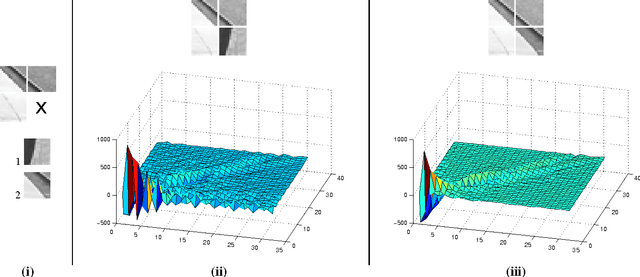

Robust foreground object segmentation via background modelling is a difficult problem in cluttered environments, where obtaining a clear view of the background to model is almost impossible. In this paper, we propose a method capable of robustly estimating the background and detecting regions of interest in such environments. In particular, we propose to extend the background initialisation component of a recent patch-based foreground detection algorithm with an elaborate technique based on Markov Random Fields, where the optimal labelling solution is computed using iterated conditional modes. Rather than relying purely on local temporal statistics, the proposed technique takes into account the spatial continuity of the entire background. Experiments with several tracking algorithms on the CAVIAR dataset indicate that the proposed method leads to considerable improvements in object tracking accuracy, when compared to methods based on Gaussian mixture models and feature histograms.
Improved Anomaly Detection in Crowded Scenes via Cell-based Analysis of Foreground Speed, Size and Texture
Apr 03, 2013
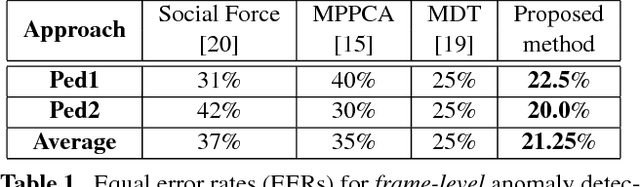


A robust and efficient anomaly detection technique is proposed, capable of dealing with crowded scenes where traditional tracking based approaches tend to fail. Initial foreground segmentation of the input frames confines the analysis to foreground objects and effectively ignores irrelevant background dynamics. Input frames are split into non-overlapping cells, followed by extracting features based on motion, size and texture from each cell. Each feature type is independently analysed for the presence of an anomaly. Unlike most methods, a refined estimate of object motion is achieved by computing the optical flow of only the foreground pixels. The motion and size features are modelled by an approximated version of kernel density estimation, which is computationally efficient even for large training datasets. Texture features are modelled by an adaptively grown codebook, with the number of entries in the codebook selected in an online fashion. Experiments on the recently published UCSD Anomaly Detection dataset show that the proposed method obtains considerably better results than three recent approaches: MPPCA, social force, and mixture of dynamic textures (MDT). The proposed method is also several orders of magnitude faster than MDT, the next best performing method.
Improved Foreground Detection via Block-based Classifier Cascade with Probabilistic Decision Integration
Mar 18, 2013



Background subtraction is a fundamental low-level processing task in numerous computer vision applications. The vast majority of algorithms process images on a pixel-by-pixel basis, where an independent decision is made for each pixel. A general limitation of such processing is that rich contextual information is not taken into account. We propose a block-based method capable of dealing with noise, illumination variations and dynamic backgrounds, while still obtaining smooth contours of foreground objects. Specifically, image sequences are analysed on an overlapping block-by-block basis. A low-dimensional texture descriptor obtained from each block is passed through an adaptive classifier cascade, where each stage handles a distinct problem. A probabilistic foreground mask generation approach then exploits block overlaps to integrate interim block-level decisions into final pixel-level foreground segmentation. Unlike many pixel-based methods, ad-hoc post-processing of foreground masks is not required. Experiments on the difficult Wallflower and I2R datasets show that the proposed approach obtains on average better results (both qualitatively and quantitatively) than several prominent methods. We furthermore propose the use of tracking performance as an unbiased approach for assessing the practical usefulness of foreground segmentation methods, and show that the proposed approach leads to considerable improvements in tracking accuracy on the CAVIAR dataset.
A Low-Complexity Algorithm for Static Background Estimation from Cluttered Image Sequences in Surveillance Contexts
Mar 11, 2013
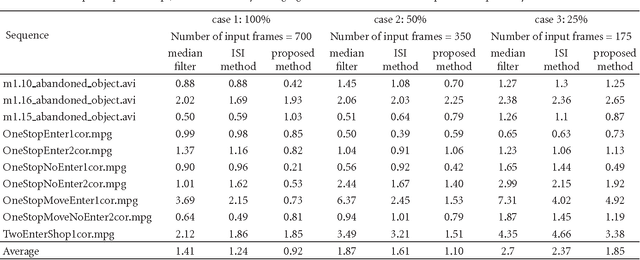

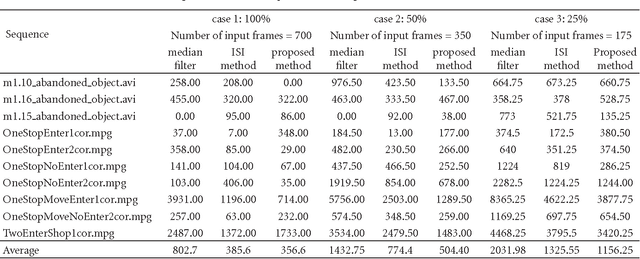
For the purposes of foreground estimation, the true background model is unavailable in many practical circumstances and needs to be estimated from cluttered image sequences. We propose a sequential technique for static background estimation in such conditions, with low computational and memory requirements. Image sequences are analysed on a block-by-block basis. For each block location a representative set is maintained which contains distinct blocks obtained along its temporal line. The background estimation is carried out in a Markov Random Field framework, where the optimal labelling solution is computed using iterated conditional modes. The clique potentials are computed based on the combined frequency response of the candidate block and its neighbourhood. It is assumed that the most appropriate block results in the smoothest response, indirectly enforcing the spatial continuity of structures within a scene. Experiments on real-life surveillance videos demonstrate that the proposed method obtains considerably better background estimates (both qualitatively and quantitatively) than median filtering and the recently proposed "intervals of stable intensity" method. Further experiments on the Wallflower dataset suggest that the combination of the proposed method with a foreground segmentation algorithm results in improved foreground segmentation.