 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMRF-based Background Initialisation for Improved Foreground Detection in Cluttered Surveillance Videos
Jun 19, 2014


Robust foreground object segmentation via background modelling is a difficult problem in cluttered environments, where obtaining a clear view of the background to model is almost impossible. In this paper, we propose a method capable of robustly estimating the background and detecting regions of interest in such environments. In particular, we propose to extend the background initialisation component of a recent patch-based foreground detection algorithm with an elaborate technique based on Markov Random Fields, where the optimal labelling solution is computed using iterated conditional modes. Rather than relying purely on local temporal statistics, the proposed technique takes into account the spatial continuity of the entire background. Experiments with several tracking algorithms on the CAVIAR dataset indicate that the proposed method leads to considerable improvements in object tracking accuracy, when compared to methods based on Gaussian mixture models and feature histograms.
K-Tangent Spaces on Riemannian Manifolds for Improved Pedestrian Detection
Mar 05, 2014
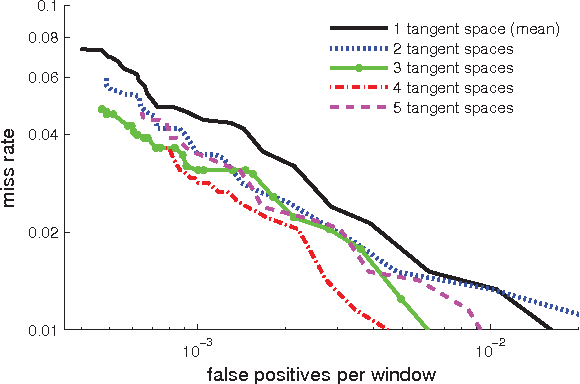
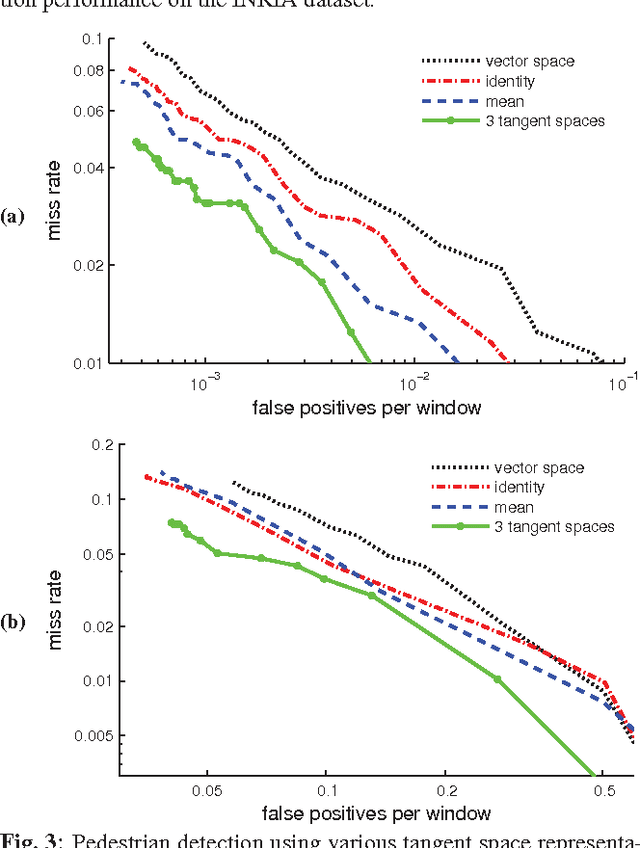
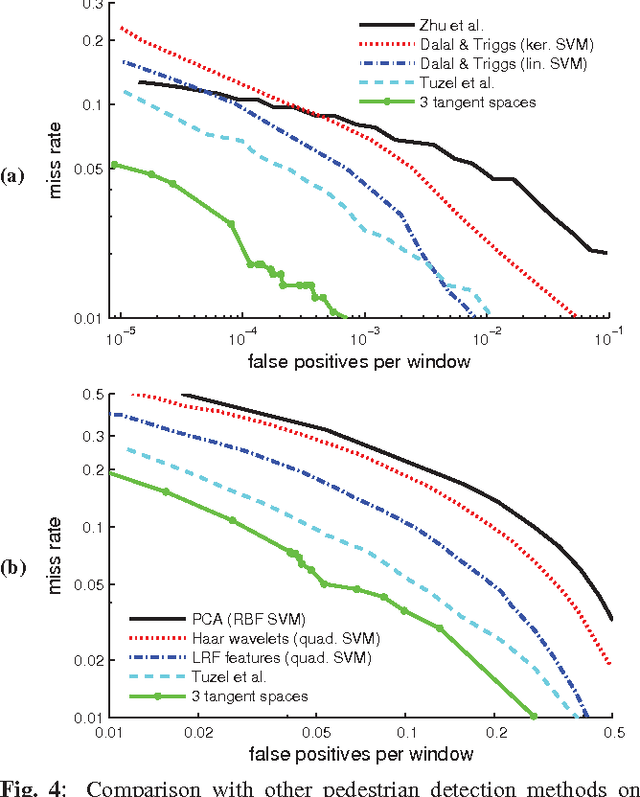
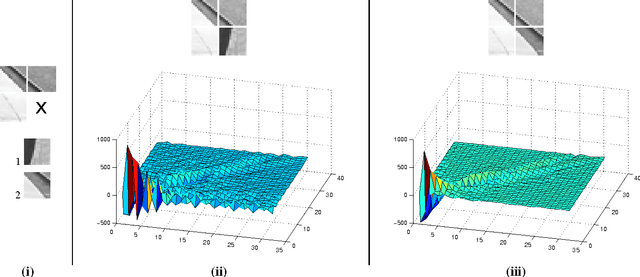
For covariance-based image descriptors, taking into account the curvature of the corresponding feature space has been shown to improve discrimination performance. This is often done through representing the descriptors as points on Riemannian manifolds, with the discrimination accomplished on a tangent space. However, such treatment is restrictive as distances between arbitrary points on the tangent space do not represent true geodesic distances, and hence do not represent the manifold structure accurately. In this paper we propose a general discriminative model based on the combination of several tangent spaces, in order to preserve more details of the structure. The model can be used as a weak learner in a boosting-based pedestrian detection framework. Experiments on the challenging INRIA and DaimlerChrysler datasets show that the proposed model leads to considerably higher performance than methods based on histograms of oriented gradients as well as previous Riemannian-based techniques.
Shadow Detection: A Survey and Comparative Evaluation of Recent Methods
Apr 04, 2013

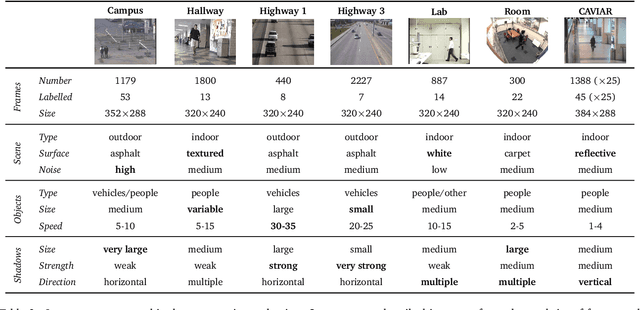

This paper presents a survey and a comparative evaluation of recent techniques for moving cast shadow detection. We identify shadow removal as a critical step for improving object detection and tracking. The survey covers methods published during the last decade, and places them in a feature-based taxonomy comprised of four categories: chromacity, physical, geometry and textures. A selection of prominent methods across the categories is compared in terms of quantitative performance measures (shadow detection and discrimination rates, colour desaturation) as well as qualitative observations. Furthermore, we propose the use of tracking performance as an unbiased approach for determining the practical usefulness of shadow detection methods. The evaluation indicates that all shadow detection approaches make different contributions and all have individual strength and weaknesses. Out of the selected methods, the geometry-based technique has strict assumptions and is not generalisable to various environments, but it is a straightforward choice when the objects of interest are easy to model and their shadows have different orientation. The chromacity based method is the fastest to implement and run, but it is sensitive to noise and less effective in low saturated scenes. The physical method improves upon the accuracy of the chromacity method by adapting to local shadow models, but fails when the spectral properties of the objects are similar to that of the background. The small-region texture based method is especially robust for pixels whose neighbourhood is textured, but may take longer to implement and is the most computationally expensive. The large-region texture based method produces the most accurate results, but has a significant computational load due to its multiple processing steps.
Spatio-Temporal Covariance Descriptors for Action and Gesture Recognition
Mar 25, 2013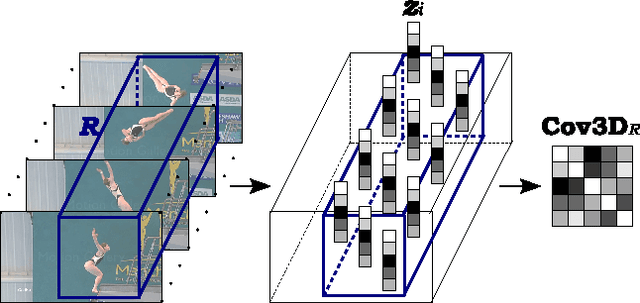

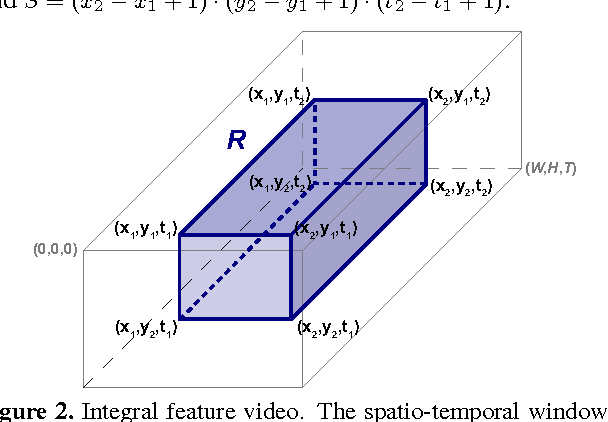
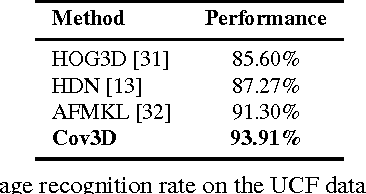
We propose a new action and gesture recognition method based on spatio-temporal covariance descriptors and a weighted Riemannian locality preserving projection approach that takes into account the curved space formed by the descriptors. The weighted projection is then exploited during boosting to create a final multiclass classification algorithm that employs the most useful spatio-temporal regions. We also show how the descriptors can be computed quickly through the use of integral video representations. Experiments on the UCF sport, CK+ facial expression and Cambridge hand gesture datasets indicate superior performance of the proposed method compared to several recent state-of-the-art techniques. The proposed method is robust and does not require additional processing of the videos, such as foreground detection, interest-point detection or tracking.