 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBags of Affine Subspaces for Robust Object Tracking
Feb 05, 2016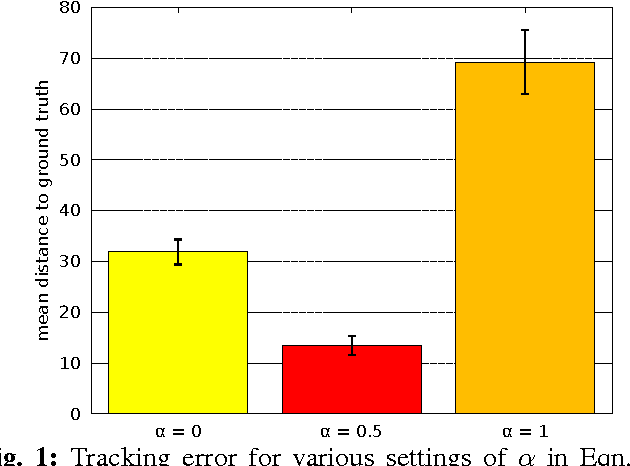

We propose an adaptive tracking algorithm where the object is modelled as a continuously updated bag of affine subspaces, with each subspace constructed from the object's appearance over several consecutive frames. In contrast to linear subspaces, affine subspaces explicitly model the origin of subspaces. Furthermore, instead of using a brittle point-to-subspace distance during the search for the object in a new frame, we propose to use a subspace-to-subspace distance by representing candidate image areas also as affine subspaces. Distances between subspaces are then obtained by exploiting the non-Euclidean geometry of Grassmann manifolds. Experiments on challenging videos (containing object occlusions, deformations, as well as variations in pose and illumination) indicate that the proposed method achieves higher tracking accuracy than several recent discriminative trackers.
From Manifold to Manifold: Geometry-Aware Dimensionality Reduction for SPD Matrices
Nov 17, 2014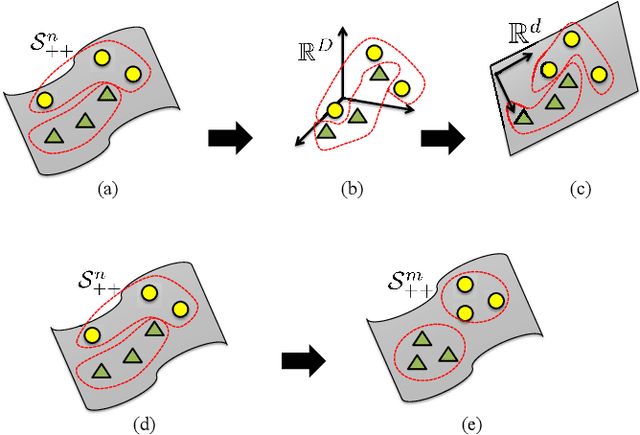
Representing images and videos with Symmetric Positive Definite (SPD) matrices and considering the Riemannian geometry of the resulting space has proven beneficial for many recognition tasks. Unfortunately, computation on the Riemannian manifold of SPD matrices --especially of high-dimensional ones-- comes at a high cost that limits the applicability of existing techniques. In this paper we introduce an approach that lets us handle high-dimensional SPD matrices by constructing a lower-dimensional, more discriminative SPD manifold. To this end, we model the mapping from the high-dimensional SPD manifold to the low-dimensional one with an orthonormal projection. In particular, we search for a projection that yields a low-dimensional manifold with maximum discriminative power encoded via an affinity-weighted similarity measure based on metrics on the manifold. Learning can then be expressed as an optimization problem on a Grassmann manifold. Our evaluation on several classification tasks shows that our approach leads to a significant accuracy gain over state-of-the-art methods.
Expanding the Family of Grassmannian Kernels: An Embedding Perspective
Jul 04, 2014



Modeling videos and image-sets as linear subspaces has proven beneficial for many visual recognition tasks. However, it also incurs challenges arising from the fact that linear subspaces do not obey Euclidean geometry, but lie on a special type of Riemannian manifolds known as Grassmannian. To leverage the techniques developed for Euclidean spaces (e.g, support vector machines) with subspaces, several recent studies have proposed to embed the Grassmannian into a Hilbert space by making use of a positive definite kernel. Unfortunately, only two Grassmannian kernels are known, none of which -as we will show- is universal, which limits their ability to approximate a target function arbitrarily well. Here, we introduce several positive definite Grassmannian kernels, including universal ones, and demonstrate their superiority over previously-known kernels in various tasks, such as classification, clustering, sparse coding and hashing.
K-Tangent Spaces on Riemannian Manifolds for Improved Pedestrian Detection
Mar 05, 2014
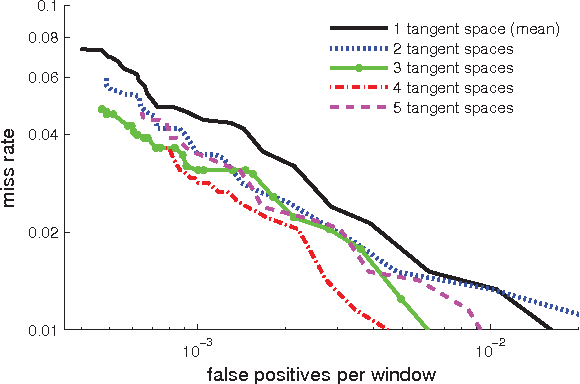
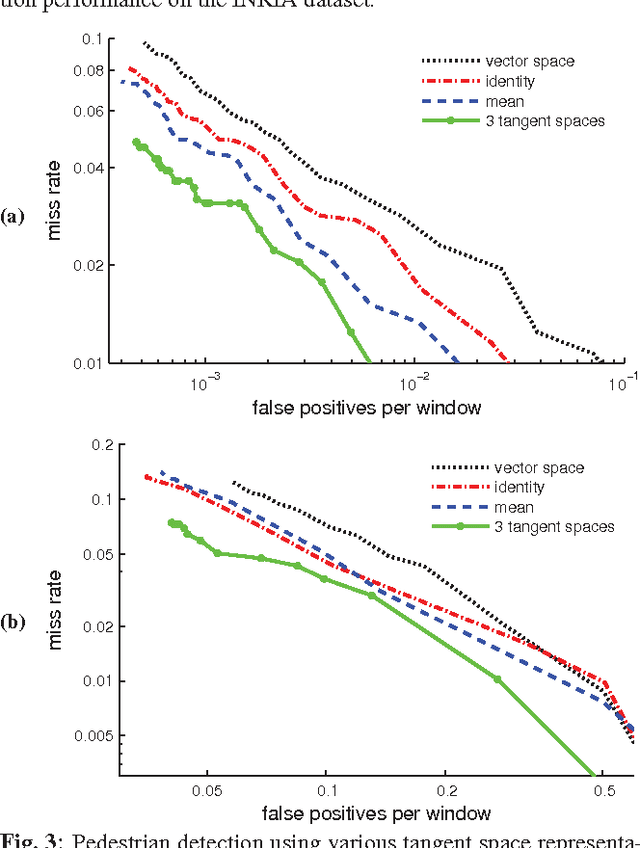
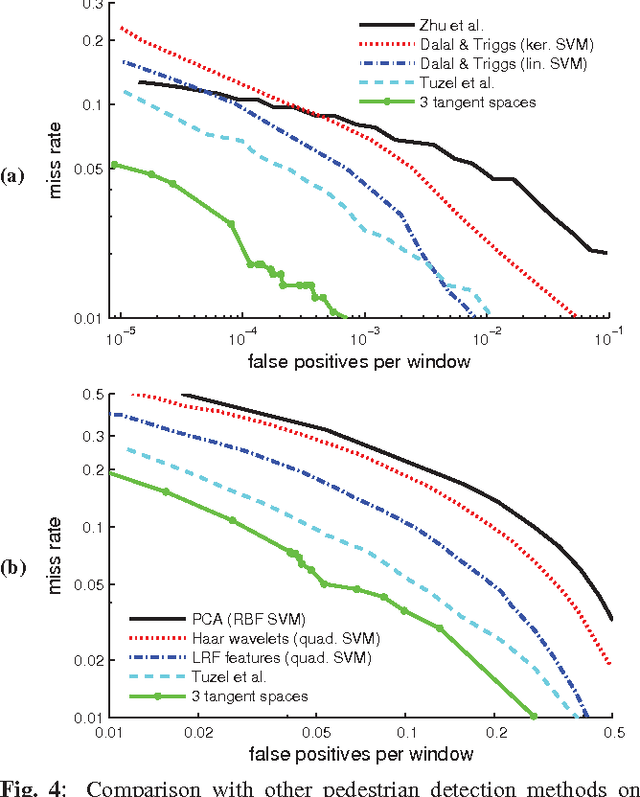
For covariance-based image descriptors, taking into account the curvature of the corresponding feature space has been shown to improve discrimination performance. This is often done through representing the descriptors as points on Riemannian manifolds, with the discrimination accomplished on a tangent space. However, such treatment is restrictive as distances between arbitrary points on the tangent space do not represent true geodesic distances, and hence do not represent the manifold structure accurately. In this paper we propose a general discriminative model based on the combination of several tangent spaces, in order to preserve more details of the structure. The model can be used as a weak learner in a boosting-based pedestrian detection framework. Experiments on the challenging INRIA and DaimlerChrysler datasets show that the proposed model leads to considerably higher performance than methods based on histograms of oriented gradients as well as previous Riemannian-based techniques.
Object Tracking via Non-Euclidean Geometry: A Grassmann Approach
Mar 03, 2014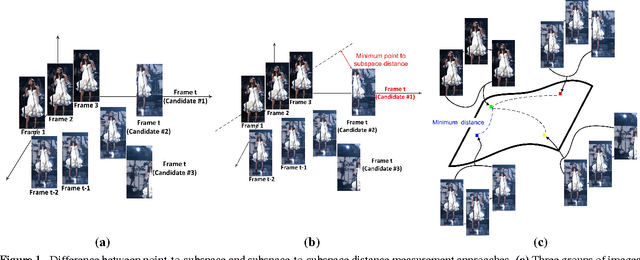
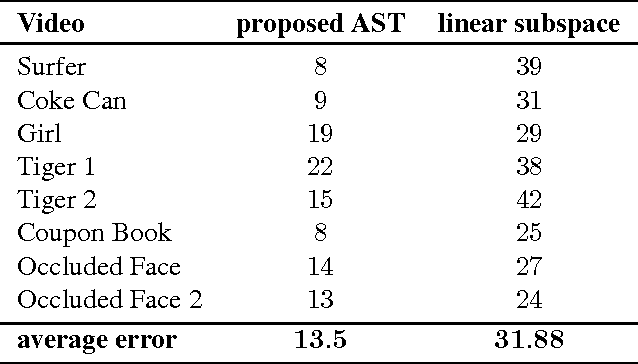
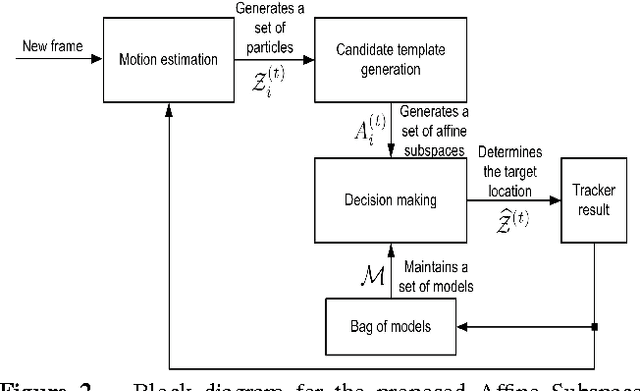

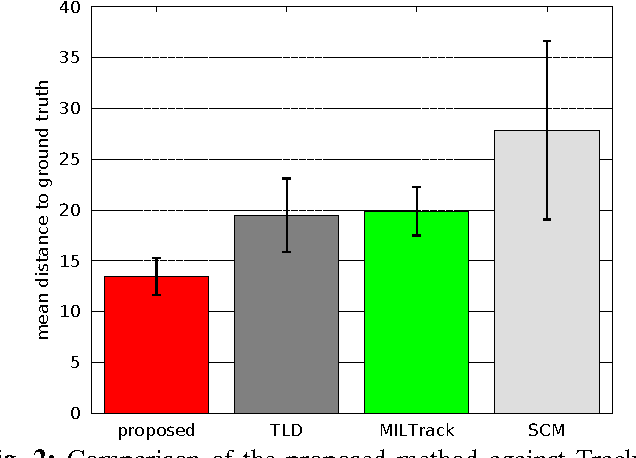
A robust visual tracking system requires an object appearance model that is able to handle occlusion, pose, and illumination variations in the video stream. This can be difficult to accomplish when the model is trained using only a single image. In this paper, we first propose a tracking approach based on affine subspaces (constructed from several images) which are able to accommodate the abovementioned variations. We use affine subspaces not only to represent the object, but also the candidate areas that the object may occupy. We furthermore propose a novel approach to measure affine subspace-to-subspace distance via the use of non-Euclidean geometry of Grassmann manifolds. The tracking problem is then considered as an inference task in a Markov Chain Monte Carlo framework via particle filtering. Quantitative evaluation on challenging video sequences indicates that the proposed approach obtains considerably better performance than several recent state-of-the-art methods such as Tracking-Learning-Detection and MILtrack.
Sparse Coding and Dictionary Learning for Symmetric Positive Definite Matrices: A Kernel Approach
Apr 16, 2013

Recent advances suggest that a wide range of computer vision problems can be addressed more appropriately by considering non-Euclidean geometry. This paper tackles the problem of sparse coding and dictionary learning in the space of symmetric positive definite matrices, which form a Riemannian manifold. With the aid of the recently introduced Stein kernel (related to a symmetric version of Bregman matrix divergence), we propose to perform sparse coding by embedding Riemannian manifolds into reproducing kernel Hilbert spaces. This leads to a convex and kernel version of the Lasso problem, which can be solved efficiently. We furthermore propose an algorithm for learning a Riemannian dictionary (used for sparse coding), closely tied to the Stein kernel. Experiments on several classification tasks (face recognition, texture classification, person re-identification) show that the proposed sparse coding approach achieves notable improvements in discrimination accuracy, in comparison to state-of-the-art methods such as tensor sparse coding, Riemannian locality preserving projection, and symmetry-driven accumulation of local features.
Spatio-Temporal Covariance Descriptors for Action and Gesture Recognition
Mar 25, 2013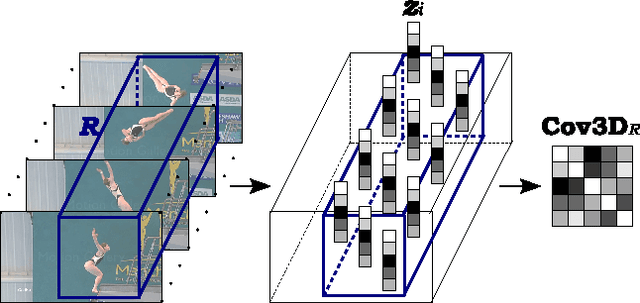

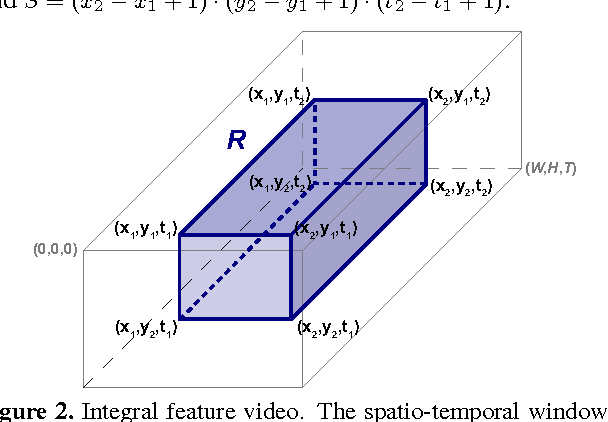
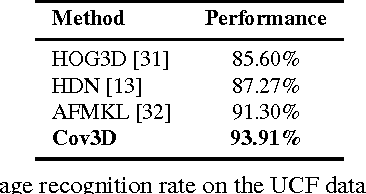
We propose a new action and gesture recognition method based on spatio-temporal covariance descriptors and a weighted Riemannian locality preserving projection approach that takes into account the curved space formed by the descriptors. The weighted projection is then exploited during boosting to create a final multiclass classification algorithm that employs the most useful spatio-temporal regions. We also show how the descriptors can be computed quickly through the use of integral video representations. Experiments on the UCF sport, CK+ facial expression and Cambridge hand gesture datasets indicate superior performance of the proposed method compared to several recent state-of-the-art techniques. The proposed method is robust and does not require additional processing of the videos, such as foreground detection, interest-point detection or tracking.
Combined Learning of Salient Local Descriptors and Distance Metrics for Image Set Face Verification
Mar 12, 2013


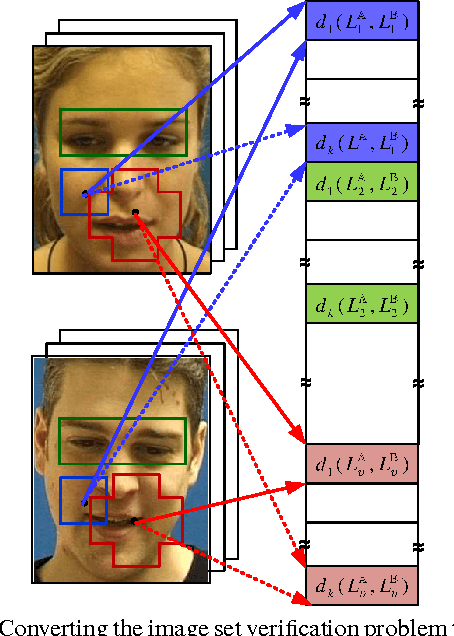
In contrast to comparing faces via single exemplars, matching sets of face images increases robustness and discrimination performance. Recent image set matching approaches typically measure similarities between subspaces or manifolds, while representing faces in a rigid and holistic manner. Such representations are easily affected by variations in terms of alignment, illumination, pose and expression. While local feature based representations are considerably more robust to such variations, they have received little attention within the image set matching area. We propose a novel image set matching technique, comprised of three aspects: (i) robust descriptors of face regions based on local features, partly inspired by the hierarchy in the human visual system, (ii) use of several subspace and exemplar metrics to compare corresponding face regions, (iii) jointly learning which regions are the most discriminative while finding the optimal mixing weights for combining metrics. Face recognition experiments on LFW, PIE and MOBIO face datasets show that the proposed algorithm obtains considerably better performance than several recent state-of-the-art techniques, such as Local Principal Angle and the Kernel Affine Hull Method.
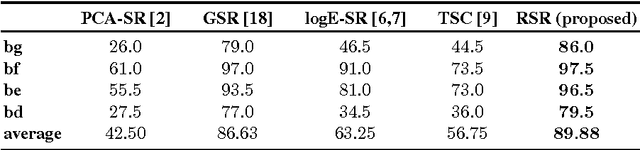
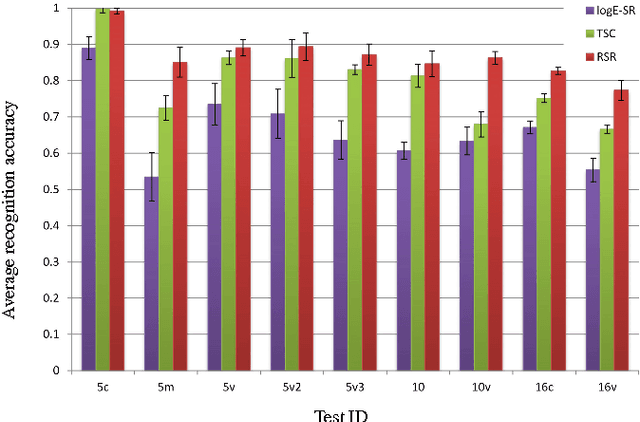
On Robust Face Recognition via Sparse Encoding: the Good, the Bad, and the Ugly
Mar 07, 2013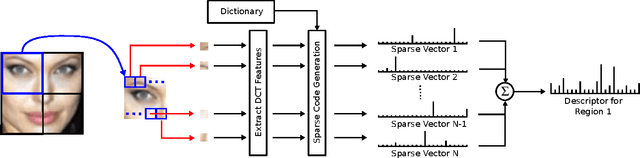



In the field of face recognition, Sparse Representation (SR) has received considerable attention during the past few years. Most of the relevant literature focuses on holistic descriptors in closed-set identification applications. The underlying assumption in SR-based methods is that each class in the gallery has sufficient samples and the query lies on the subspace spanned by the gallery of the same class. Unfortunately, such assumption is easily violated in the more challenging face verification scenario, where an algorithm is required to determine if two faces (where one or both have not been seen before) belong to the same person. In this paper, we first discuss why previous attempts with SR might not be applicable to verification problems. We then propose an alternative approach to face verification via SR. Specifically, we propose to use explicit SR encoding on local image patches rather than the entire face. The obtained sparse signals are pooled via averaging to form multiple region descriptors, which are then concatenated to form an overall face descriptor. Due to the deliberate loss spatial relations within each region (caused by averaging), the resulting descriptor is robust to misalignment & various image deformations. Within the proposed framework, we evaluate several SR encoding techniques: l1-minimisation, Sparse Autoencoder Neural Network (SANN), and an implicit probabilistic technique based on Gaussian Mixture Models. Thorough experiments on AR, FERET, exYaleB, BANCA and ChokePoint datasets show that the proposed local SR approach obtains considerably better and more robust performance than several previous state-of-the-art holistic SR methods, in both verification and closed-set identification problems. The experiments also show that l1-minimisation based encoding has a considerably higher computational than the other techniques, but leads to higher recognition rates.