 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimal Semantic Sufficiency Meets Unsupervised Domain Generalization
Sep 19, 2025The generalization ability of deep learning has been extensively studied in supervised settings, yet it remains less explored in unsupervised scenarios. Recently, the Unsupervised Domain Generalization (UDG) task has been proposed to enhance the generalization of models trained with prevalent unsupervised learning techniques, such as Self-Supervised Learning (SSL). UDG confronts the challenge of distinguishing semantics from variations without category labels. Although some recent methods have employed domain labels to tackle this issue, such domain labels are often unavailable in real-world contexts. In this paper, we address these limitations by formalizing UDG as the task of learning a Minimal Sufficient Semantic Representation: a representation that (i) preserves all semantic information shared across augmented views (sufficiency), and (ii) maximally removes information irrelevant to semantics (minimality). We theoretically ground these objectives from the perspective of information theory, demonstrating that optimizing representations to achieve sufficiency and minimality directly reduces out-of-distribution risk. Practically, we implement this optimization through Minimal-Sufficient UDG (MS-UDG), a learnable model by integrating (a) an InfoNCE-based objective to achieve sufficiency; (b) two complementary components to promote minimality: a novel semantic-variation disentanglement loss and a reconstruction-based mechanism for capturing adequate variation. Empirically, MS-UDG sets a new state-of-the-art on popular unsupervised domain-generalization benchmarks, consistently outperforming existing SSL and UDG methods, without category or domain labels during representation learning.
SD-MAD: Sign-Driven Few-shot Multi-Anomaly Detection in Medical Images
May 22, 2025Medical anomaly detection (AD) is crucial for early clinical intervention, yet it faces challenges due to limited access to high-quality medical imaging data, caused by privacy concerns and data silos. Few-shot learning has emerged as a promising approach to alleviate these limitations by leveraging the large-scale prior knowledge embedded in vision-language models (VLMs). Recent advancements in few-shot medical AD have treated normal and abnormal cases as a one-class classification problem, often overlooking the distinction among multiple anomaly categories. Thus, in this paper, we propose a framework tailored for few-shot medical anomaly detection in the scenario where the identification of multiple anomaly categories is required. To capture the detailed radiological signs of medical anomaly categories, our framework incorporates diverse textual descriptions for each category generated by a Large-Language model, under the assumption that different anomalies in medical images may share common radiological signs in each category. Specifically, we introduce SD-MAD, a two-stage Sign-Driven few-shot Multi-Anomaly Detection framework: (i) Radiological signs are aligned with anomaly categories by amplifying inter-anomaly discrepancy; (ii) Aligned signs are selected further to mitigate the effect of the under-fitting and uncertain-sample issue caused by limited medical data, employing an automatic sign selection strategy at inference. Moreover, we propose three protocols to comprehensively quantify the performance of multi-anomaly detection. Extensive experiments illustrate the effectiveness of our method.
Multivariate Prototype Representation for Domain-Generalized Incremental Learning
Sep 24, 2023



Deep learning models suffer from catastrophic forgetting when being fine-tuned with samples of new classes. This issue becomes even more pronounced when faced with the domain shift between training and testing data. In this paper, we study the critical and less explored Domain-Generalized Class-Incremental Learning (DGCIL). We design a DGCIL approach that remembers old classes, adapts to new classes, and can classify reliably objects from unseen domains. Specifically, our loss formulation maintains classification boundaries and suppresses the domain-specific information of each class. With no old exemplars stored, we use knowledge distillation and estimate old class prototype drift as incremental training advances. Our prototype representations are based on multivariate Normal distributions whose means and covariances are constantly adapted to changing model features to represent old classes well by adapting to the feature space drift. For old classes, we sample pseudo-features from the adapted Normal distributions with the help of Cholesky decomposition. In contrast to previous pseudo-feature sampling strategies that rely solely on average mean prototypes, our method excels at capturing varying semantic information. Experiments on several benchmarks validate our claims.
Few-Shot Class-Incremental Learning from an Open-Set Perspective
Jul 30, 2022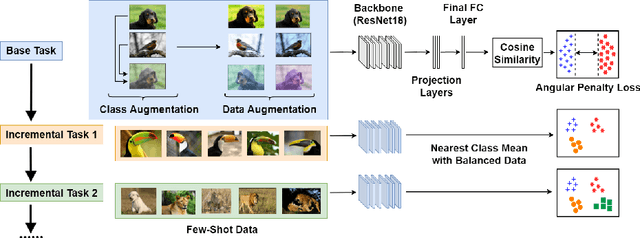
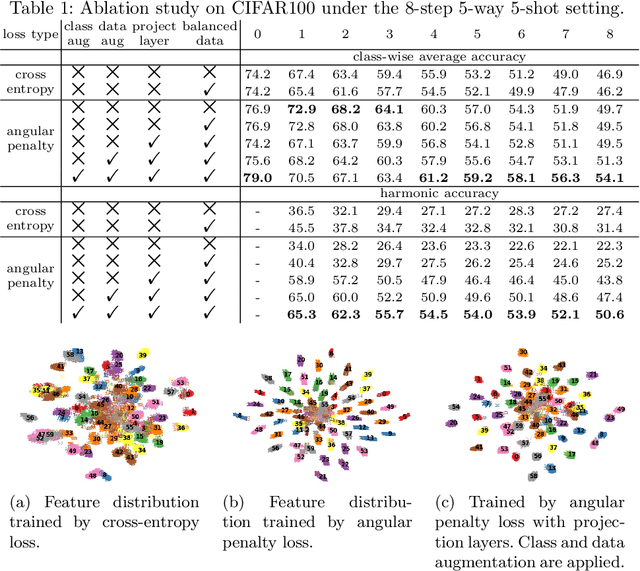
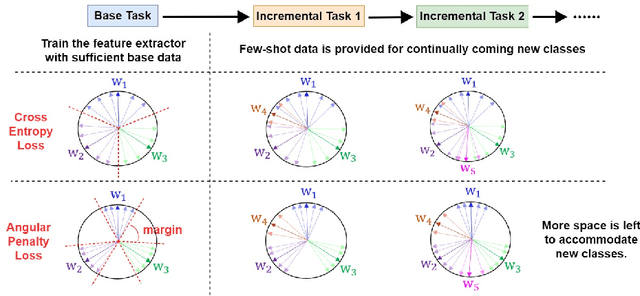
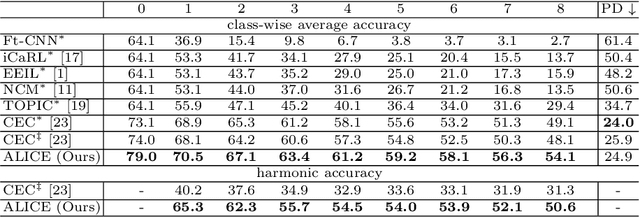
The continual appearance of new objects in the visual world poses considerable challenges for current deep learning methods in real-world deployments. The challenge of new task learning is often exacerbated by the scarcity of data for the new categories due to rarity or cost. Here we explore the important task of Few-Shot Class-Incremental Learning (FSCIL) and its extreme data scarcity condition of one-shot. An ideal FSCIL model needs to perform well on all classes, regardless of their presentation order or paucity of data. It also needs to be robust to open-set real-world conditions and be easily adapted to the new tasks that always arise in the field. In this paper, we first reevaluate the current task setting and propose a more comprehensive and practical setting for the FSCIL task. Then, inspired by the similarity of the goals for FSCIL and modern face recognition systems, we propose our method -- Augmented Angular Loss Incremental Classification or ALICE. In ALICE, instead of the commonly used cross-entropy loss, we propose to use the angular penalty loss to obtain well-clustered features. As the obtained features not only need to be compactly clustered but also diverse enough to maintain generalization for future incremental classes, we further discuss how class augmentation, data augmentation, and data balancing affect classification performance. Experiments on benchmark datasets, including CIFAR100, miniImageNet, and CUB200, demonstrate the improved performance of ALICE over the state-of-the-art FSCIL methods.
DIODE: Dilatable Incremental Object Detection
Aug 12, 2021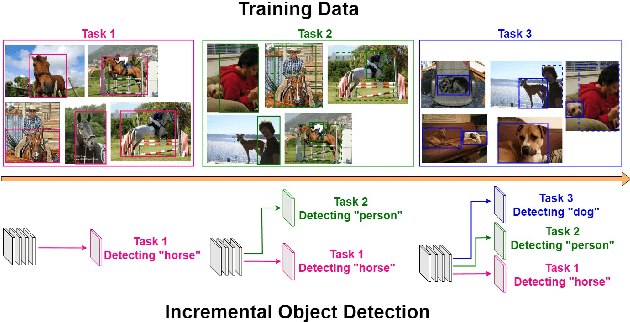
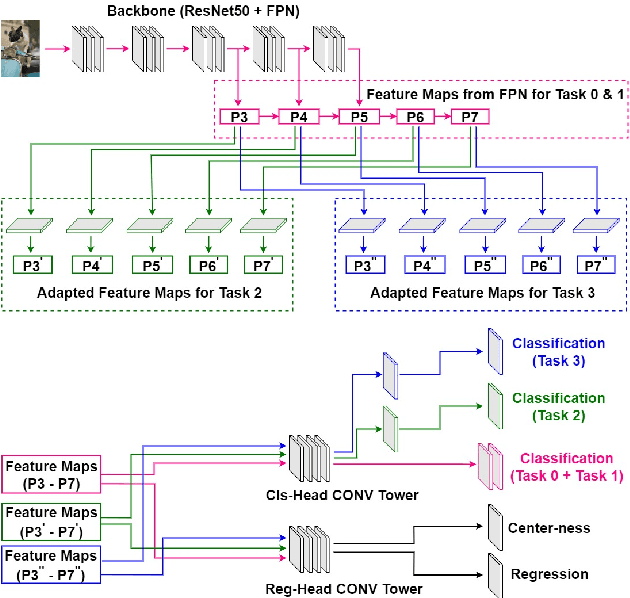
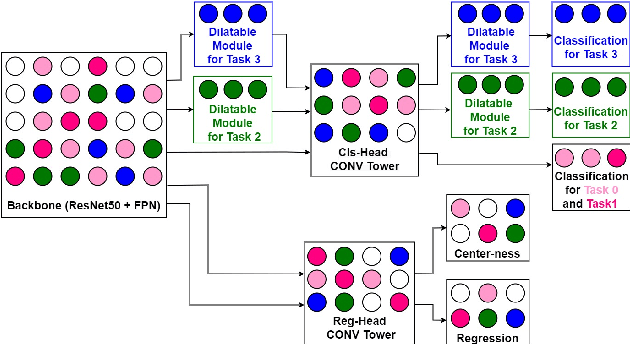
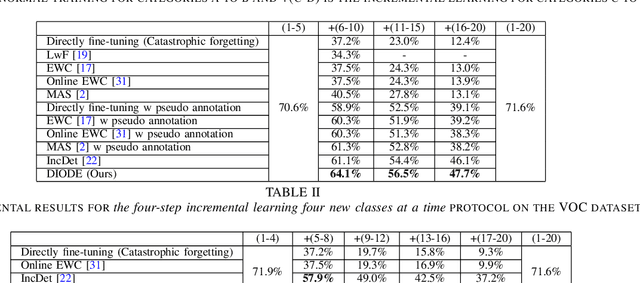
To accommodate rapid changes in the real world, the cognition system of humans is capable of continually learning concepts. On the contrary, conventional deep learning models lack this capability of preserving previously learned knowledge. When a neural network is fine-tuned to learn new tasks, its performance on previously trained tasks will significantly deteriorate. Many recent works on incremental object detection tackle this problem by introducing advanced regularization. Although these methods have shown promising results, the benefits are often short-lived after the first incremental step. Under multi-step incremental learning, the trade-off between old knowledge preserving and new task learning becomes progressively more severe. Thus, the performance of regularization-based incremental object detectors gradually decays for subsequent learning steps. In this paper, we aim to alleviate this performance decay on multi-step incremental detection tasks by proposing a dilatable incremental object detector (DIODE). For the task-shared parameters, our method adaptively penalizes the changes of important weights for previous tasks. At the same time, the structure of the model is dilated or expanded by a limited number of task-specific parameters to promote new task learning. Extensive experiments on PASCAL VOC and COCO datasets demonstrate substantial improvements over the state-of-the-art methods. Notably, compared with the state-of-the-art methods, our method achieves up to 6.0% performance improvement by increasing the number of parameters by just 1.2% for each newly learned task.
Scalable Bayesian Deep Learning with Kernel Seed Networks
Apr 19, 2021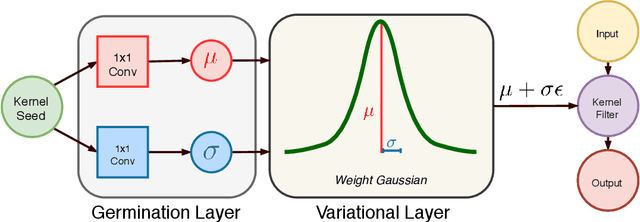
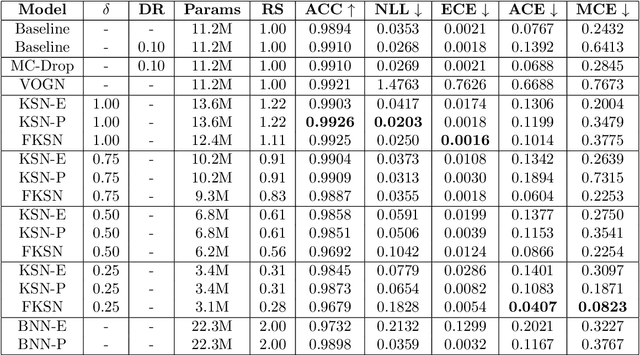
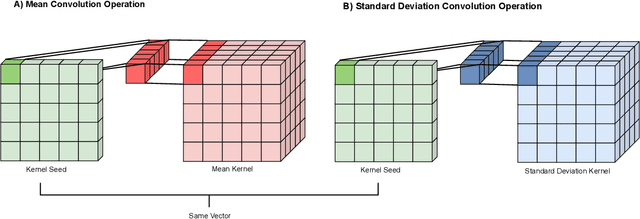
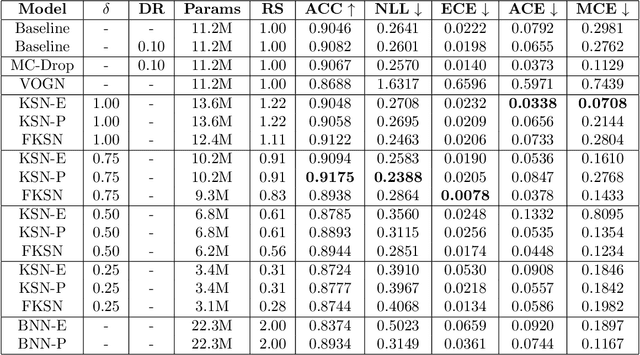
This paper addresses the scalability problem of Bayesian deep neural networks. The performance of deep neural networks is undermined by the fact that these algorithms have poorly calibrated measures of uncertainty. This restricts their application in high risk domains such as computer aided diagnosis and autonomous vehicle navigation. Bayesian Deep Learning (BDL) offers a promising method for representing uncertainty in neural network. However, BDL requires a separate set of parameters to store the mean and standard deviation of model weights to learn a distribution. This results in a prohibitive 2-fold increase in the number of model parameters. To address this problem we present a method for performing BDL, namely Kernel Seed Networks (KSN), which does not require a 2-fold increase in the number of parameters. KSNs use 1x1 Convolution operations to learn a compressed latent space representation of the parameter distribution. In this paper we show how this allows KSNs to outperform conventional BDL methods while reducing the number of required parameters by up to a factor of 6.6.
SID: Incremental Learning for Anchor-Free Object Detection via Selective and Inter-Related Distillation
Dec 31, 2020


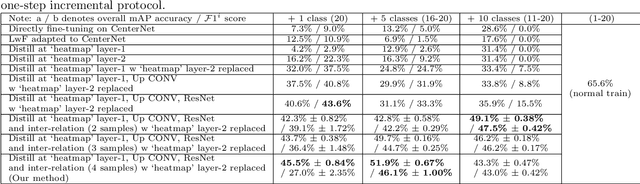
Incremental learning requires a model to continually learn new tasks from streaming data. However, traditional fine-tuning of a well-trained deep neural network on a new task will dramatically degrade performance on the old task -- a problem known as catastrophic forgetting. In this paper, we address this issue in the context of anchor-free object detection, which is a new trend in computer vision as it is simple, fast, and flexible. Simply adapting current incremental learning strategies fails on these anchor-free detectors due to lack of consideration of their specific model structures. To deal with the challenges of incremental learning on anchor-free object detectors, we propose a novel incremental learning paradigm called Selective and Inter-related Distillation (SID). In addition, a novel evaluation metric is proposed to better assess the performance of detectors under incremental learning conditions. By selective distilling at the proper locations and further transferring additional instance relation knowledge, our method demonstrates significant advantages on the benchmark datasets PASCAL VOC and COCO.
Faster ILOD: Incremental Learning for Object Detectors based on Faster RCNN
Mar 09, 2020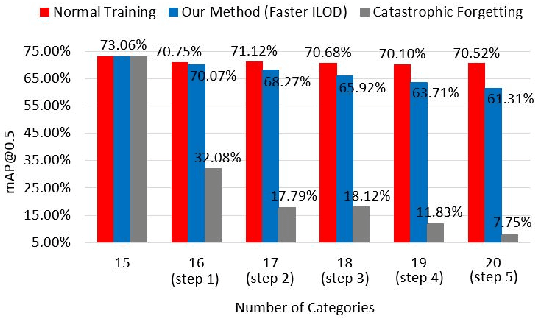
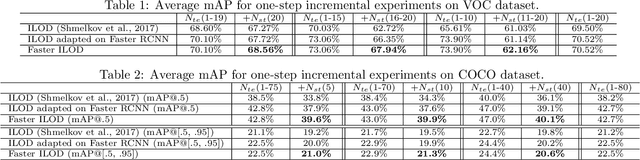
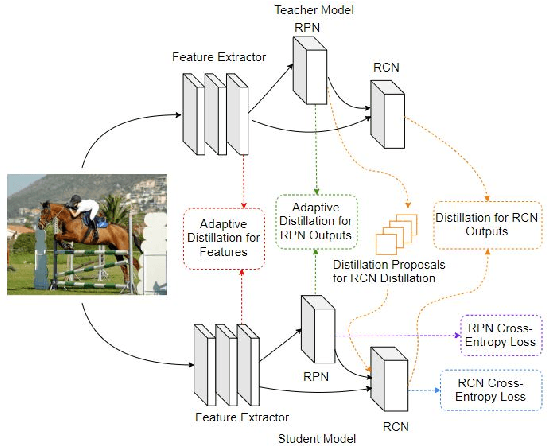
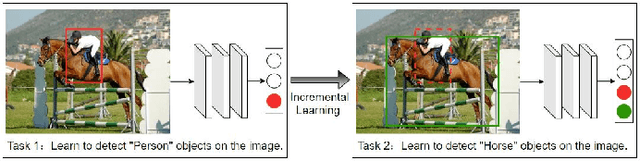
The human vision and perception system is inherently incremental where new knowledge is continually learned over time whilst existing knowledge is retained. On the other hand, deep learning networks are ill-equipped for incremental learning. When a well-trained network is adapted to new categories, its performance on the old categories will dramatically degrade. To address this problem, incremental learning methods have been explored to preserve the old knowledge of deep learning models. However, the state-of-the-art incremental object detector employs an external fixed region proposal method that increases overall computation time and reduces accuracy compared to object detectors such as Faster RCNN that use trainable Region Proposal Networks (RPNs). The purpose of this paper is to design an efficient end-to-end incremental object detector using knowledge distillation for object detectors based on RPNs. We first evaluate and analyze the performance of RPN-based detector with classic distillation towards incremental detection tasks. Then, we introduce multi-network adaptive distillation that properly retains knowledge from the old categories when fine-turning the model for new task. Experiments on the benchmark datasets, PASCAL VOC and COCO, demonstrate that the proposed incremental detector is more accurate as well as being 13 times faster than the baseline detector.
Unsupervised Domain Adaptive Object Detection using Forward-Backward Cyclic Adaptation
Feb 03, 2020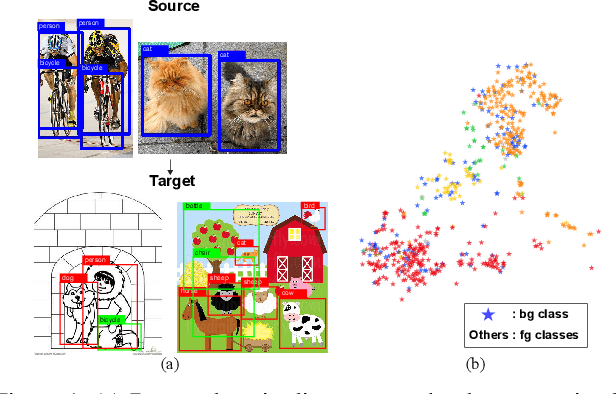

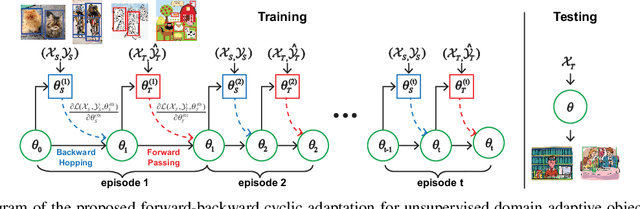
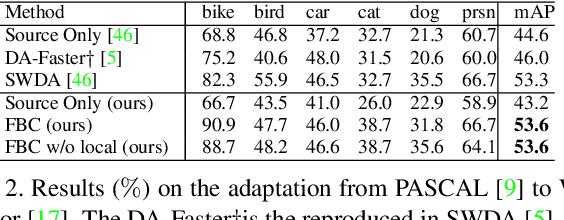
We present a novel approach to perform the unsupervised domain adaptation for object detection through forward-backward cyclic (FBC) training. Recent adversarial training based domain adaptation methods have shown their effectiveness on minimizing domain discrepancy via marginal feature distributions alignment. However, aligning the marginal feature distributions does not guarantee the alignment of class conditional distributions. This limitation is more evident when adapting object detectors as the domain discrepancy is larger compared to the image classification task, e.g. various number of objects exist in one image and the majority of content in an image is the background. This motivates us to learn domain invariance for category level semantics via gradient alignment. Intuitively, if the gradients of two domains point in similar directions, then the learning of one domain can improve that of another domain. To achieve gradient alignment, we propose Forward-Backward Cyclic Adaptation, which iteratively computes adaptation from source to target via backward hopping and from target to source via forward passing. In addition, we align low-level features for adapting holistic color/texture via adversarial training. However, the detector performs well on both domains is not ideal for target domain. As such, in each cycle, domain diversity is enforced by maximum entropy regularization on the source domain to penalize confident source-specific learning and minimum entropy regularization on target domain to intrigue target-specific learning. Theoretical analysis of the training process is provided, and extensive experiments on challenging cross-domain object detection datasets have shown the superiority of our approach over the state-of-the-art.
To What Extent Does Downsampling, Compression, and Data Scarcity Impact Renal Image Analysis?
Sep 22, 2019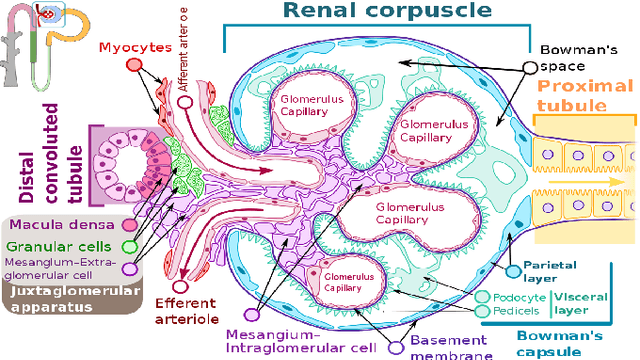
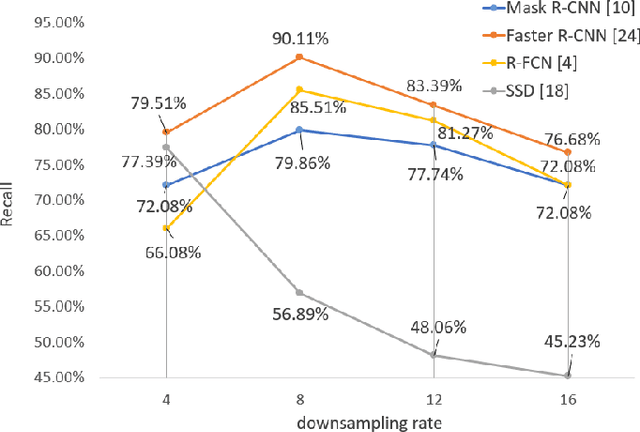
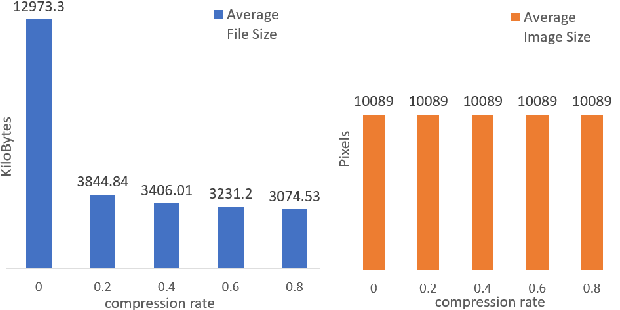
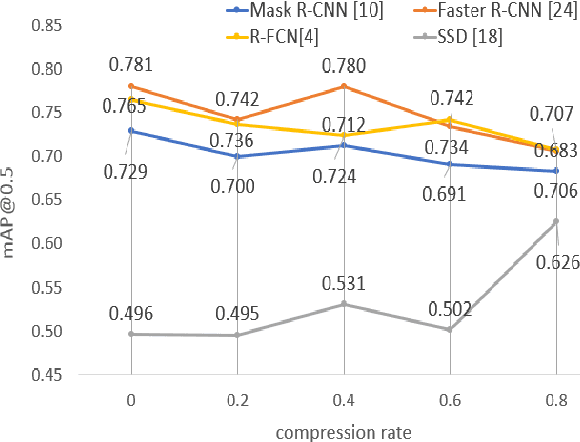
The condition of the Glomeruli, or filter sacks, in renal Direct Immunofluorescence (DIF) specimens is a critical indicator for diagnosing kidney diseases. A digital pathology system which digitizes a glass histology slide into a Whole Slide Image (WSI) and then automatically detects and zooms in on the glomeruli with a higher magnification objective will be extremely helpful for pathologists. In this paper, using glomerulus detection as the study case, we provide analysis and observations on several important issues to help with the development of Computer Aided Diagnostic (CAD) systems to process WSIs. Large image resolution, large file size, and data scarcity are always challenging to deal with. To this end, we first examine image downsampling rates in terms of their effect on detection accuracy. Second, we examine the impact of image compression. Third, we examine the relationship between the size of the training set and detection accuracy. To understand the above issues, experiments are performed on the state-of-the-art detectors: Faster R-CNN, R-FCN, Mask R-CNN and SSD. Critical findings are observed: (1) The best balance between detection accuracy, detection speed and file size is achieved at 8 times downsampling captured with a $40\times$ objective; (2) compression which reduces the file size dramatically, does not necessarily have an adverse effect on overall accuracy; (3) reducing the amount of training data to some extents causes a drop in precision but has a negligible impact on the recall; (4) in most cases, Faster R-CNN achieves the best accuracy in the glomerulus detection task. We show that the image file size of $40\times$ WSI images can be reduced by a factor of over 6000 with negligible loss of glomerulus detection accuracy.