 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSOS: Selective Objective Switch for Rapid Immunofluorescence Whole Slide Image Classification
Mar 11, 2020
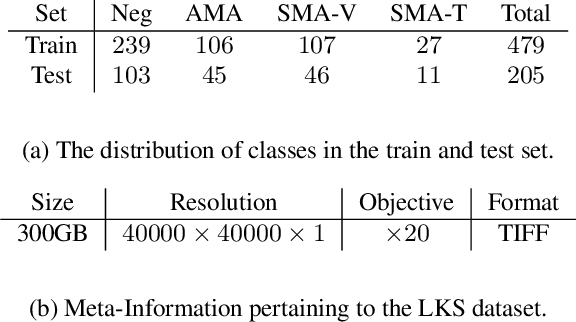
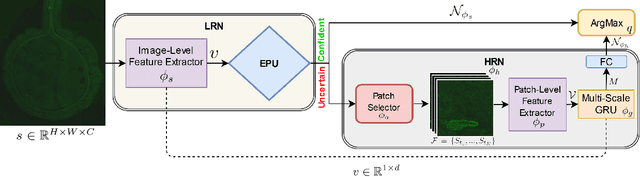
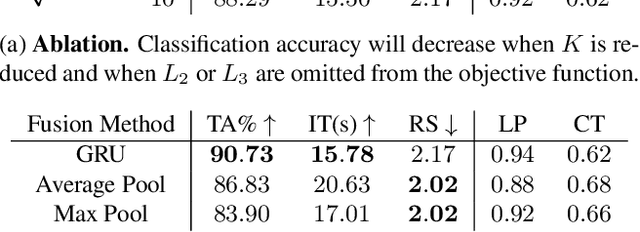
The difficulty of processing gigapixel whole slide images (WSIs) in clinical microscopy has been a long-standing barrier to implementing computer aided diagnostic systems. Since modern computing resources are unable to perform computations at this extremely large scale, current state of the art methods utilize patch-based processing to preserve the resolution of WSIs. However, these methods are often resource intensive and make significant compromises on processing time. In this paper, we demonstrate that conventional patch-based processing is redundant for certain WSI classification tasks where high resolution is only required in a minority of cases. This reflects what is observed in clinical practice; where a pathologist may screen slides using a low power objective and only switch to a high power in cases where they are uncertain about their findings. To eliminate these redundancies, we propose a method for the selective use of high resolution processing based on the confidence of predictions on downscaled WSIs --- we call this the Selective Objective Switch (SOS). Our method is validated on a novel dataset of 684 Liver-Kidney-Stomach immunofluorescence WSIs routinely used in the investigation of autoimmune liver disease. By limiting high resolution processing to cases which cannot be classified confidently at low resolution, we maintain the accuracy of patch-level analysis whilst reducing the inference time by a factor of 7.74.
To What Extent Does Downsampling, Compression, and Data Scarcity Impact Renal Image Analysis?
Sep 22, 2019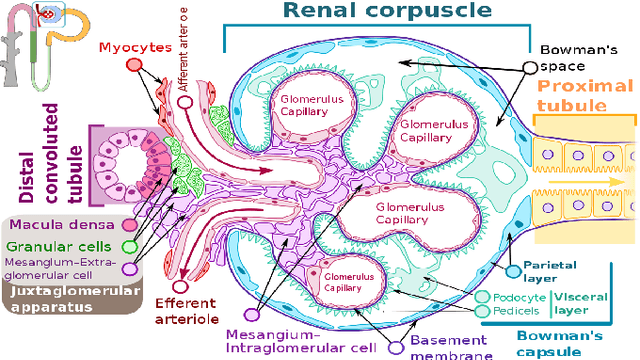
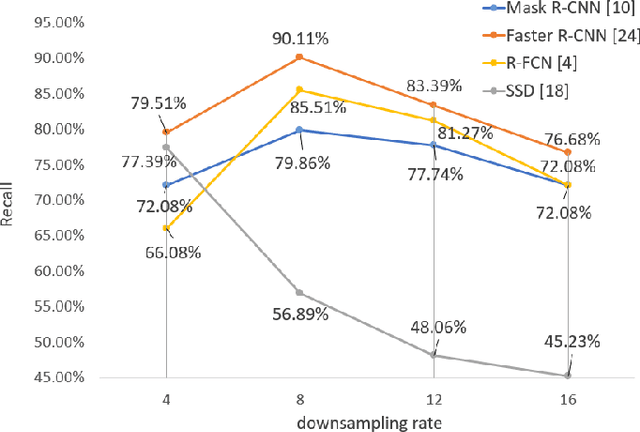
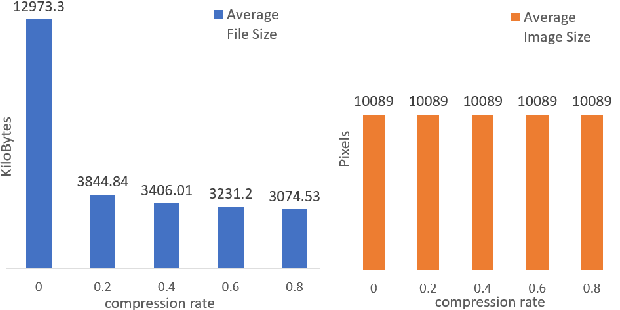
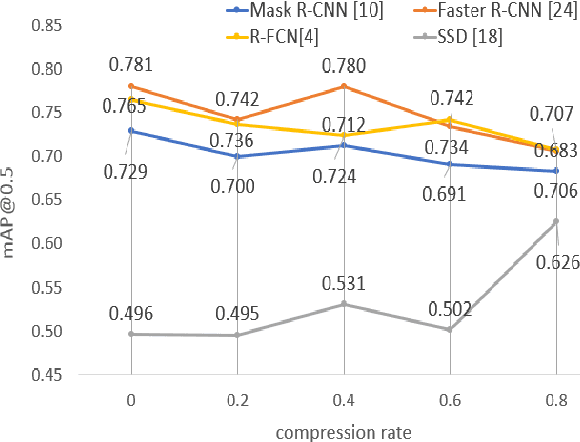
The condition of the Glomeruli, or filter sacks, in renal Direct Immunofluorescence (DIF) specimens is a critical indicator for diagnosing kidney diseases. A digital pathology system which digitizes a glass histology slide into a Whole Slide Image (WSI) and then automatically detects and zooms in on the glomeruli with a higher magnification objective will be extremely helpful for pathologists. In this paper, using glomerulus detection as the study case, we provide analysis and observations on several important issues to help with the development of Computer Aided Diagnostic (CAD) systems to process WSIs. Large image resolution, large file size, and data scarcity are always challenging to deal with. To this end, we first examine image downsampling rates in terms of their effect on detection accuracy. Second, we examine the impact of image compression. Third, we examine the relationship between the size of the training set and detection accuracy. To understand the above issues, experiments are performed on the state-of-the-art detectors: Faster R-CNN, R-FCN, Mask R-CNN and SSD. Critical findings are observed: (1) The best balance between detection accuracy, detection speed and file size is achieved at 8 times downsampling captured with a $40\times$ objective; (2) compression which reduces the file size dramatically, does not necessarily have an adverse effect on overall accuracy; (3) reducing the amount of training data to some extents causes a drop in precision but has a negligible impact on the recall; (4) in most cases, Faster R-CNN achieves the best accuracy in the glomerulus detection task. We show that the image file size of $40\times$ WSI images can be reduced by a factor of over 6000 with negligible loss of glomerulus detection accuracy.
SlideNet: Fast and Accurate Slide Quality Assessment Based on Deep Neural Networks
Mar 20, 2018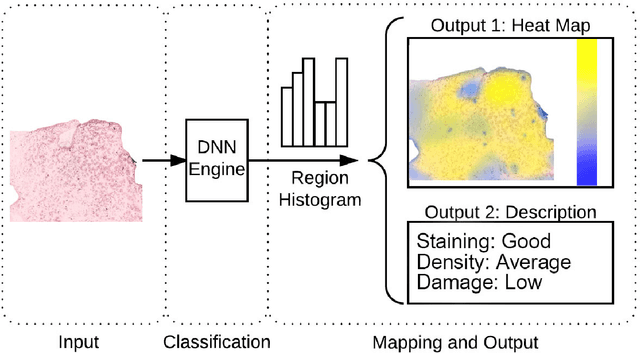

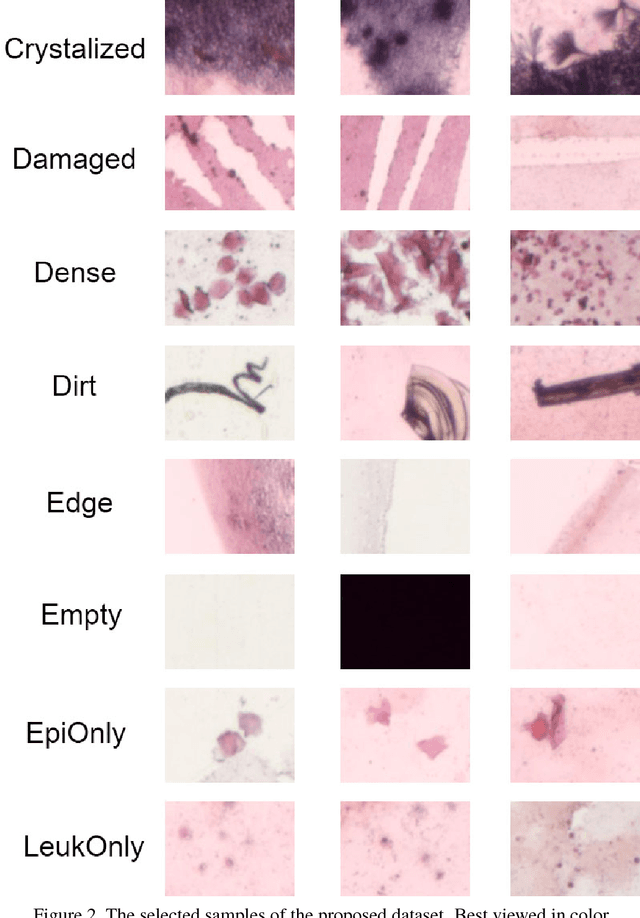
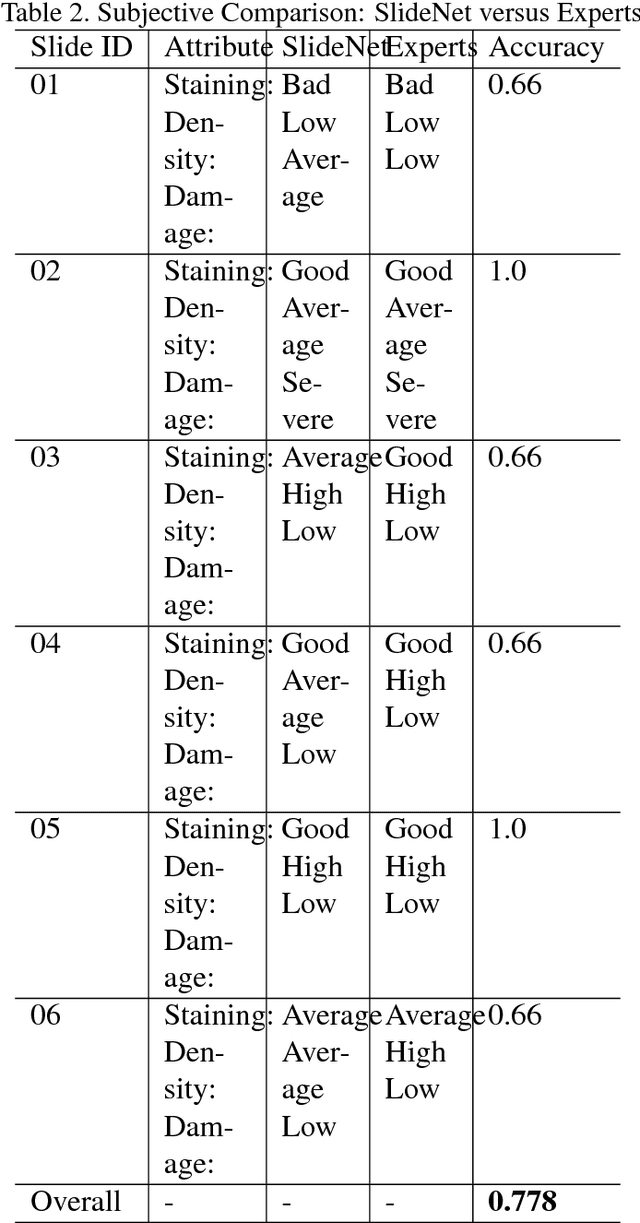
This work tackles the automatic fine-grained slide quality assessment problem for digitized direct smears test using the Gram staining protocol. Automatic quality assessment can provide useful information for the pathologists and the whole digital pathology workflow. For instance, if the system found a slide to have a low staining quality, it could send a request to the automatic slide preparation system to remake the slide. If the system detects severe damage in the slides, it could notify the experts that manual microscope reading may be required. In order to address the quality assessment problem, we propose a deep neural network based framework to automatically assess the slide quality in a semantic way. Specifically, the first step of our framework is to perform dense fine-grained region classification on the whole slide and calculate the region distribution histogram. Next, our framework will generate assessments of the slide quality from various perspectives: staining quality, information density, damage level and which regions are more valuable for subsequent high-magnification analysis. To make the information more accessible, we present our results in the form of a heat map and text summaries. Additionally, in order to stimulate research in this direction, we propose a novel dataset for slide quality assessment. Experiments show that the proposed framework outperforms recent related works.
Discovering Discriminative Cell Attributes for HEp-2 Specimen Image Classification
Jul 28, 2014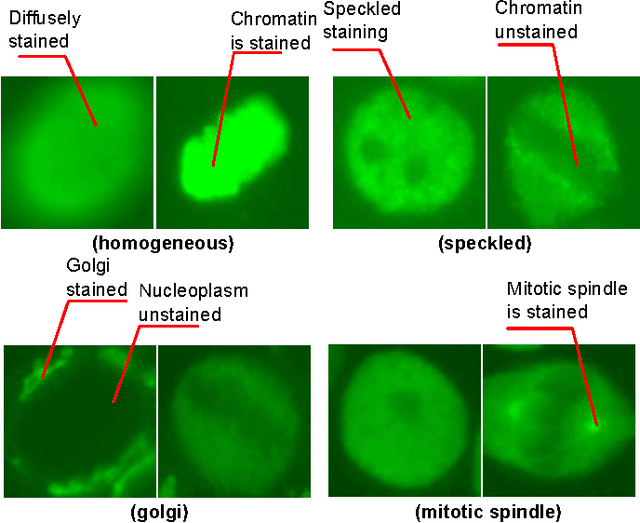
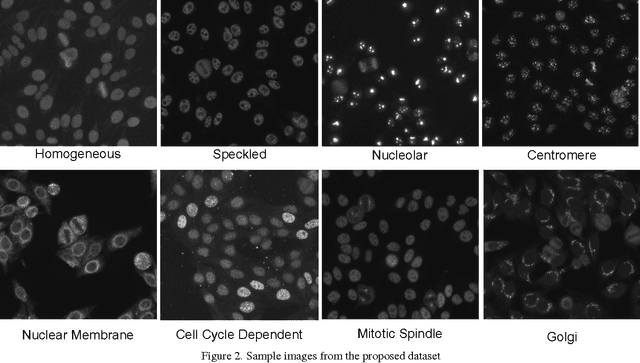
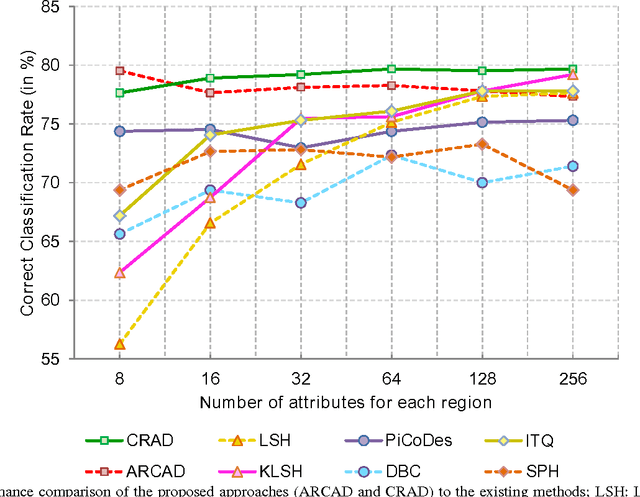
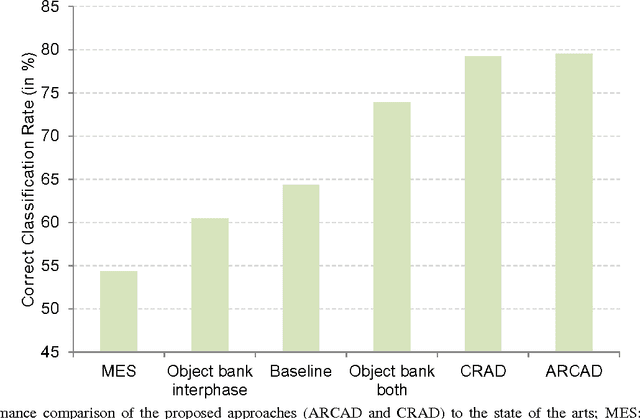
Recently, there has been a growing interest in developing Computer Aided Diagnostic (CAD) systems for improving the reliability and consistency of pathology test results. This paper describes a novel CAD system for the Anti-Nuclear Antibody (ANA) test via Indirect Immunofluorescence protocol on Human Epithelial Type 2 (HEp-2) cells. While prior works have primarily focused on classifying cell images extracted from ANA specimen images, this work takes a further step by focussing on the specimen image classification problem itself. Our system is able to efficiently classify specimen images as well as producing meaningful descriptions of ANA pattern class which helps physicians to understand the differences between various ANA patterns. We achieve this goal by designing a specimen-level image descriptor that: (1) is highly discriminative; (2) has small descriptor length and (3) is semantically meaningful at the cell level. In our work, a specimen image descriptor is represented by its overall cell attribute descriptors. As such, we propose two max-margin based learning schemes to discover cell attributes whilst still maintaining the discrimination of the specimen image descriptor. Our learning schemes differ from the existing discriminative attribute learning approaches as they primarily focus on discovering image-level attributes. Comparative evaluations were undertaken to contrast the proposed approach to various state-of-the-art approaches on a novel HEp-2 cell dataset which was specifically proposed for the specimen-level classification. Finally, we showcase the ability of the proposed approach to provide textual descriptions to explain ANA patterns.
Automatic Classification of Human Epithelial Type 2 Cell Indirect Immunofluorescence Images using Cell Pyramid Matching
Mar 15, 2014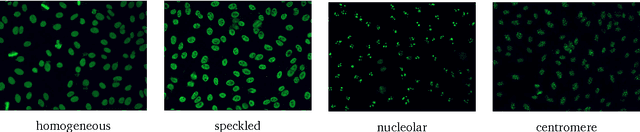
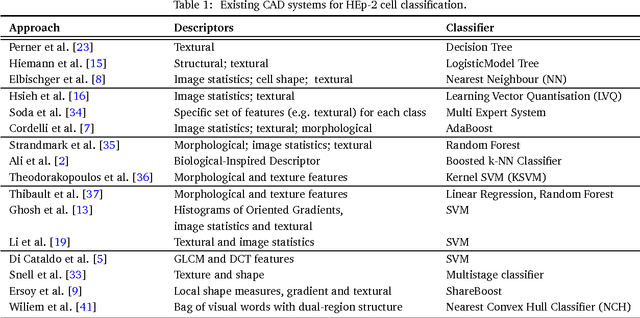
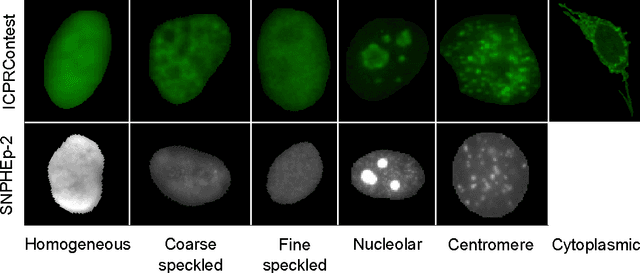
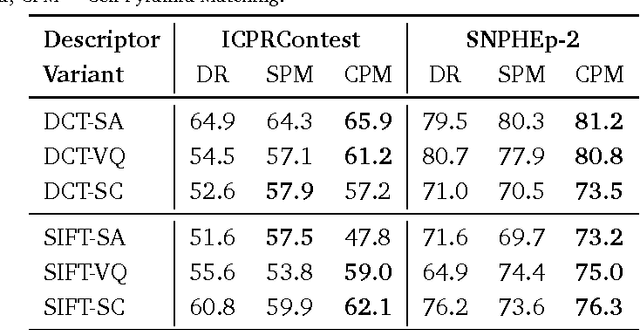
This paper describes a novel system for automatic classification of images obtained from Anti-Nuclear Antibody (ANA) pathology tests on Human Epithelial type 2 (HEp-2) cells using the Indirect Immunofluorescence (IIF) protocol. The IIF protocol on HEp-2 cells has been the hallmark method to identify the presence of ANAs, due to its high sensitivity and the large range of antigens that can be detected. However, it suffers from numerous shortcomings, such as being subjective as well as time and labour intensive. Computer Aided Diagnostic (CAD) systems have been developed to address these problems, which automatically classify a HEp-2 cell image into one of its known patterns (eg. speckled, homogeneous). Most of the existing CAD systems use handpicked features to represent a HEp-2 cell image, which may only work in limited scenarios. We propose a novel automatic cell image classification method termed Cell Pyramid Matching (CPM), which is comprised of regional histograms of visual words coupled with the Multiple Kernel Learning framework. We present a study of several variations of generating histograms and show the efficacy of the system on two publicly available datasets: the ICPR HEp-2 cell classification contest dataset and the SNPHEp-2 dataset.
* arXiv admin note: substantial text overlap with arXiv:1304.1262
Classification of Human Epithelial Type 2 Cell Indirect Immunofluoresence Images via Codebook Based Descriptors
Apr 04, 2013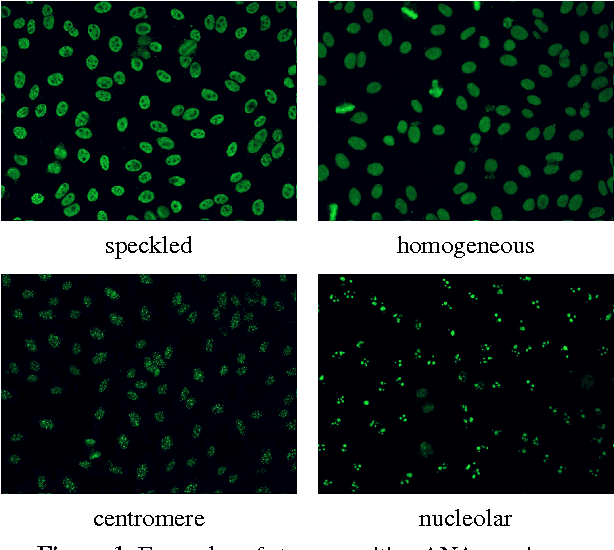

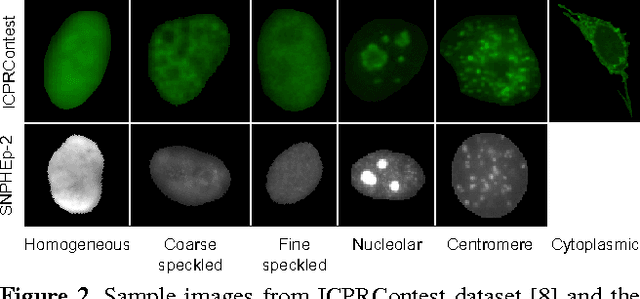
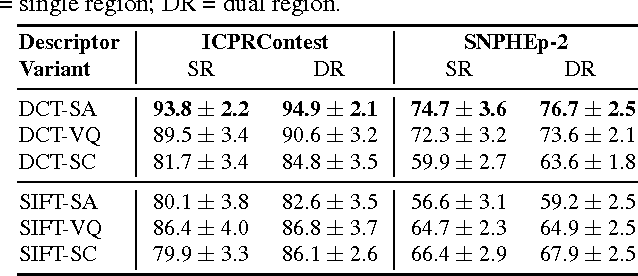
The Anti-Nuclear Antibody (ANA) clinical pathology test is commonly used to identify the existence of various diseases. A hallmark method for identifying the presence of ANAs is the Indirect Immunofluorescence method on Human Epithelial (HEp-2) cells, due to its high sensitivity and the large range of antigens that can be detected. However, the method suffers from numerous shortcomings, such as being subjective as well as time and labour intensive. Computer Aided Diagnostic (CAD) systems have been developed to address these problems, which automatically classify a HEp-2 cell image into one of its known patterns (eg., speckled, homogeneous). Most of the existing CAD systems use handpicked features to represent a HEp-2 cell image, which may only work in limited scenarios. In this paper, we propose a cell classification system comprised of a dual-region codebook-based descriptor, combined with the Nearest Convex Hull Classifier. We evaluate the performance of several variants of the descriptor on two publicly available datasets: ICPR HEp-2 cell classification contest dataset and the new SNPHEp-2 dataset. To our knowledge, this is the first time codebook-based descriptors are applied and studied in this domain. Experiments show that the proposed system has consistent high performance and is more robust than two recent CAD systems.