 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing LIP to Gloss Over Faces in Single-Stage Face Detection Networks
Jul 05, 2018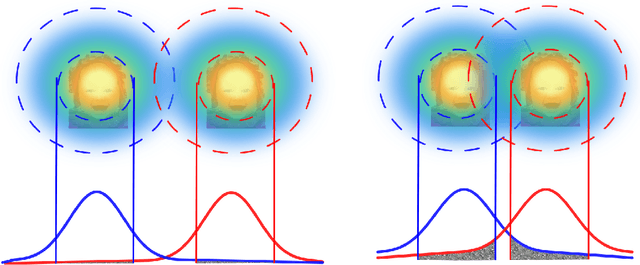
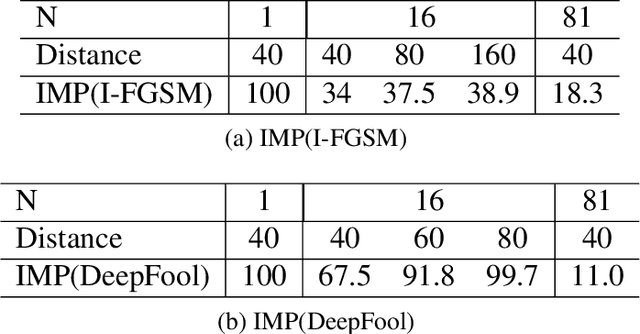

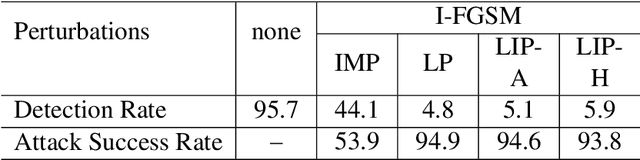
This work shows that it is possible to fool/attack recent state-of-the-art face detectors which are based on the single-stage networks. Successfully attacking face detectors could be a serious malware vulnerability when deploying a smart surveillance system utilizing face detectors. We show that existing adversarial perturbation methods are not effective to perform such an attack, especially when there are multiple faces in the input image. This is because the adversarial perturbation specifically generated for one face may disrupt the adversarial perturbation for another face. In this paper, we call this problem the Instance Perturbation Interference (IPI) problem. This IPI problem is addressed by studying the relationship between the deep neural network receptive field and the adversarial perturbation. As such, we propose the Localized Instance Perturbation (LIP) that uses adversarial perturbation constrained to the Effective Receptive Field (ERF) of a target to perform the attack. Experiment results show the LIP method massively outperforms existing adversarial perturbation generation methods -- often by a factor of 2 to 10.
Convex Class Model on Symmetric Positive Definite Manifolds
Jun 14, 2018



The effectiveness of Symmetric Positive Definite (SPD) manifold features has been proven in various computer vision tasks. However, due to the non-Euclidean geometry of these features, existing Euclidean machineries cannot be directly used. In this paper, we tackle the classification tasks with limited training data on SPD manifolds. Our proposed framework, named Manifold Convex Class Model, represents each class on SPD manifolds using a convex model and classification can be performed by computing distances to the convex models. We provide three methods based on different metrics to address the optimization problem of the smallest distance of a point to the convex model on SPD manifold. The efficacy of our proposed framework is demonstrated both on synthetic data and several computer vision tasks including object recognition, texture classification, person re-identification and traffic scene classification.
What is the Best Way for Extracting Meaningful Attributes from Pictures?
Oct 17, 2016


Automatic attribute discovery methods have gained in popularity to extract sets of visual attributes from images or videos for various tasks. Despite their good performance in some classification tasks, it is difficult to evaluate whether the attributes discovered by these methods are meaningful and which methods are the most appropriate to discover attributes for visual descriptions. In its simplest form, such an evaluation can be performed by manually verifying whether there is any consistent identifiable visual concept distinguishing between positive and negative exemplars labelled by an attribute. This manual checking is tedious, expensive and labour intensive. In addition, comparisons between different methods could also be problematic as it is not clear how one could quantitatively decide which attribute is more meaningful than the others. In this paper, we propose a novel attribute meaningfulness metric to address this challenging problem. With this metric, automatic quantitative evaluation can be performed on the attribute sets; thus, reducing the enormous effort to perform manual evaluation. The proposed metric is applied to some recent automatic attribute discovery and hashing methods on four attribute-labelled datasets. To further validate the efficacy of the proposed method, we conducted a user study. In addition, we also compared our metric with a semi-supervised attribute discover method using the mixture of probabilistic PCA. In our evaluation, we gleaned several insights that could be beneficial in developing new automatic attribute discovery methods.
Determining the best attributes for surveillance video keywords generation
Feb 21, 2016



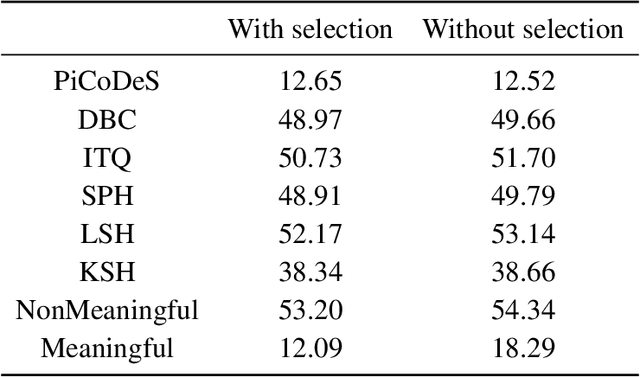
Automatic video keyword generation is one of the key ingredients in reducing the burden of security officers in analyzing surveillance videos. Keywords or attributes are generally chosen manually based on expert knowledge of surveillance. Most existing works primarily aim at either supervised learning approaches relying on extensive manual labelling or hierarchical probabilistic models that assume the features are extracted using the bag-of-words approach; thus limiting the utilization of the other features. To address this, we turn our attention to automatic attribute discovery approaches. However, it is not clear which automatic discovery approach can discover the most meaningful attributes. Furthermore, little research has been done on how to compare and choose the best automatic attribute discovery methods. In this paper, we propose a novel approach, based on the shared structure exhibited amongst meaningful attributes, that enables us to compare between different automatic attribute discovery approaches.We then validate our approach by comparing various attribute discovery methods such as PiCoDeS on two attribute datasets. The evaluation shows that our approach is able to select the automatic discovery approach that discovers the most meaningful attributes. We then employ the best discovery approach to generate keywords for videos recorded from a surveillance system. This work shows it is possible to massively reduce the amount of manual work in generating video keywords without limiting ourselves to a particular video feature descriptor.
Automatic and Quantitative evaluation of attribute discovery methods
Feb 05, 2016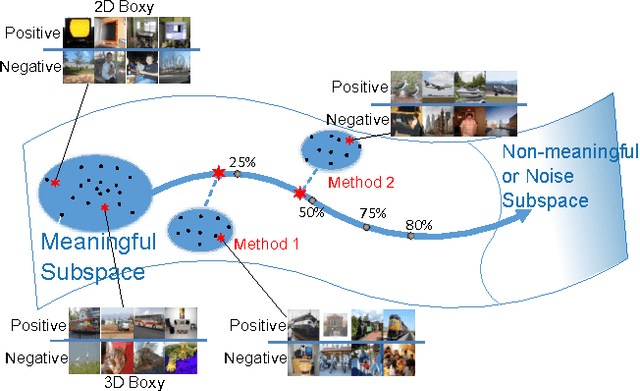

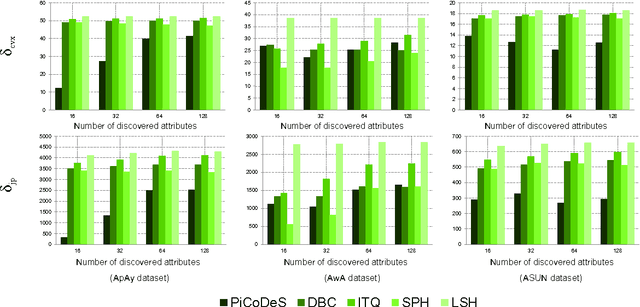
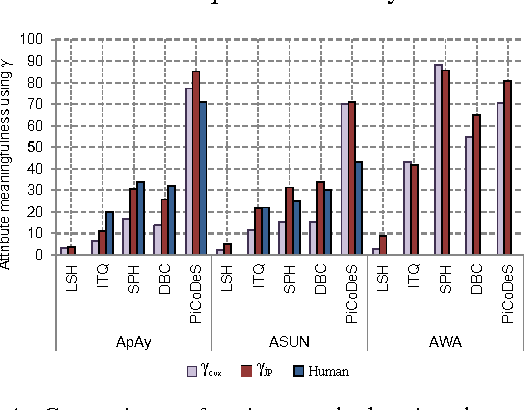
Many automatic attribute discovery methods have been developed to extract a set of visual attributes from images for various tasks. However, despite good performance in some image classification tasks, it is difficult to evaluate whether these methods discover meaningful attributes and which one is the best to find the attributes for image descriptions. An intuitive way to evaluate this is to manually verify whether consistent identifiable visual concepts exist to distinguish between positive and negative images of an attribute. This manual checking is tedious, labor intensive and expensive and it is very hard to get quantitative comparisons between different methods. In this work, we tackle this problem by proposing an attribute meaningfulness metric, that can perform automatic evaluation on the meaningfulness of attribute sets as well as achieving quantitative comparisons. We apply our proposed metric to recent automatic attribute discovery methods and popular hashing methods on three attribute datasets. A user study is also conducted to validate the effectiveness of the metric. In our evaluation, we gleaned some insights that could be beneficial in developing automatic attribute discovery methods to generate meaningful attributes. To the best of our knowledge, this is the first work to quantitatively measure the semantic content of automatically discovered attributes.
Patch-based Probabilistic Image Quality Assessment for Face Selection and Improved Video-based Face Recognition
Mar 14, 2014

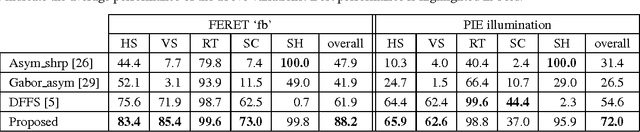

In video based face recognition, face images are typically captured over multiple frames in uncontrolled conditions, where head pose, illumination, shadowing, motion blur and focus change over the sequence. Additionally, inaccuracies in face localisation can also introduce scale and alignment variations. Using all face images, including images of poor quality, can actually degrade face recognition performance. While one solution it to use only the "best" subset of images, current face selection techniques are incapable of simultaneously handling all of the abovementioned issues. We propose an efficient patch-based face image quality assessment algorithm which quantifies the similarity of a face image to a probabilistic face model, representing an "ideal" face. Image characteristics that affect recognition are taken into account, including variations in geometric alignment (shift, rotation and scale), sharpness, head pose and cast shadows. Experiments on FERET and PIE datasets show that the proposed algorithm is able to identify images which are simultaneously the most frontal, aligned, sharp and well illuminated. Further experiments on a new video surveillance dataset (termed ChokePoint) show that the proposed method provides better face subsets than existing face selection techniques, leading to significant improvements in recognition accuracy.
Matching Image Sets via Adaptive Multi Convex Hull
Mar 03, 2014
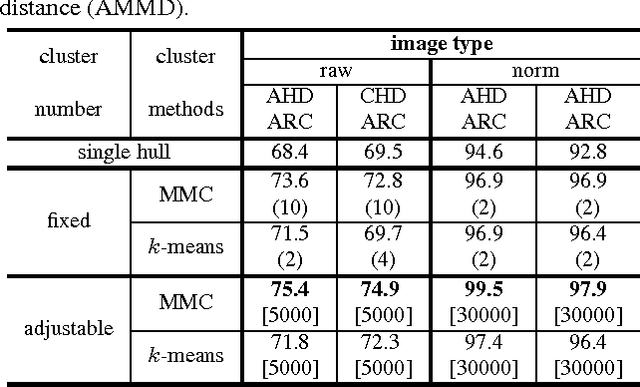
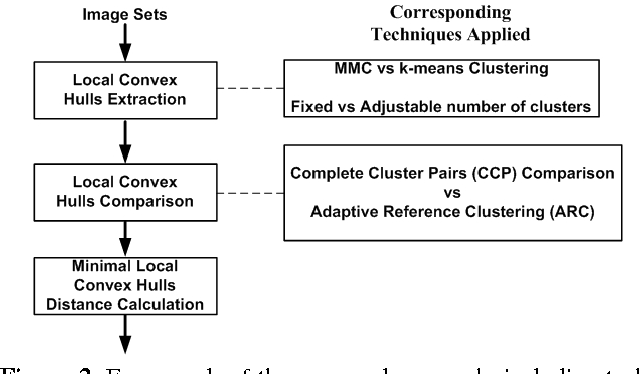

Traditional nearest points methods use all the samples in an image set to construct a single convex or affine hull model for classification. However, strong artificial features and noisy data may be generated from combinations of training samples when significant intra-class variations and/or noise occur in the image set. Existing multi-model approaches extract local models by clustering each image set individually only once, with fixed clusters used for matching with various image sets. This may not be optimal for discrimination, as undesirable environmental conditions (eg. illumination and pose variations) may result in the two closest clusters representing different characteristics of an object (eg. frontal face being compared to non-frontal face). To address the above problem, we propose a novel approach to enhance nearest points based methods by integrating affine/convex hull classification with an adapted multi-model approach. We first extract multiple local convex hulls from a query image set via maximum margin clustering to diminish the artificial variations and constrain the noise in local convex hulls. We then propose adaptive reference clustering (ARC) to constrain the clustering of each gallery image set by forcing the clusters to have resemblance to the clusters in the query image set. By applying ARC, noisy clusters in the query set can be discarded. Experiments on Honda, MoBo and ETH-80 datasets show that the proposed method outperforms single model approaches and other recent techniques, such as Sparse Approximated Nearest Points, Mutual Subspace Method and Manifold Discriminant Analysis.
Classification of Human Epithelial Type 2 Cell Indirect Immunofluoresence Images via Codebook Based Descriptors
Apr 04, 2013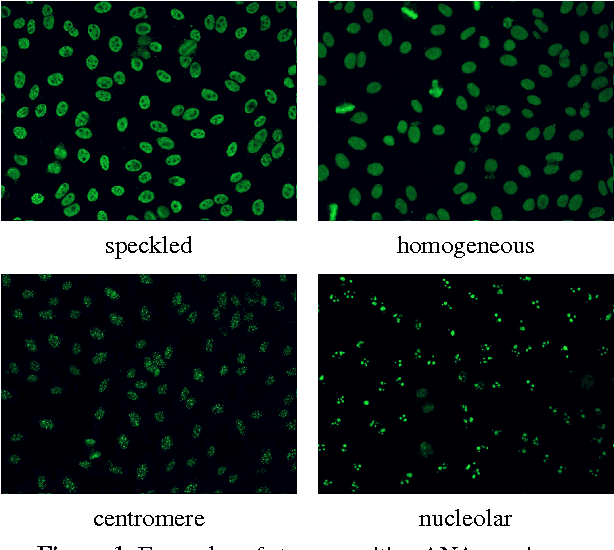

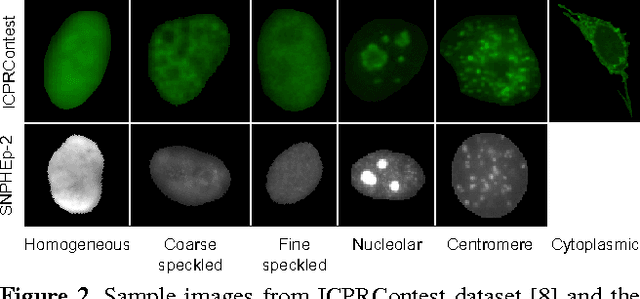
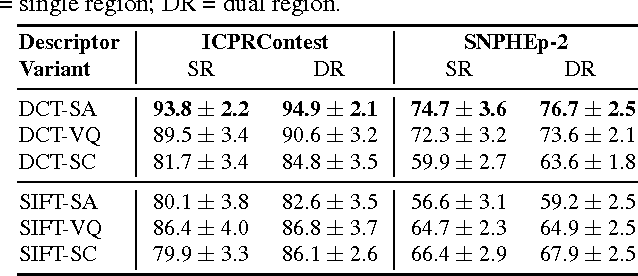
The Anti-Nuclear Antibody (ANA) clinical pathology test is commonly used to identify the existence of various diseases. A hallmark method for identifying the presence of ANAs is the Indirect Immunofluorescence method on Human Epithelial (HEp-2) cells, due to its high sensitivity and the large range of antigens that can be detected. However, the method suffers from numerous shortcomings, such as being subjective as well as time and labour intensive. Computer Aided Diagnostic (CAD) systems have been developed to address these problems, which automatically classify a HEp-2 cell image into one of its known patterns (eg., speckled, homogeneous). Most of the existing CAD systems use handpicked features to represent a HEp-2 cell image, which may only work in limited scenarios. In this paper, we propose a cell classification system comprised of a dual-region codebook-based descriptor, combined with the Nearest Convex Hull Classifier. We evaluate the performance of several variants of the descriptor on two publicly available datasets: ICPR HEp-2 cell classification contest dataset and the new SNPHEp-2 dataset. To our knowledge, this is the first time codebook-based descriptors are applied and studied in this domain. Experiments show that the proposed system has consistent high performance and is more robust than two recent CAD systems.
Video Face Matching using Subset Selection and Clustering of Probabilistic Multi-Region Histograms
Mar 26, 2013

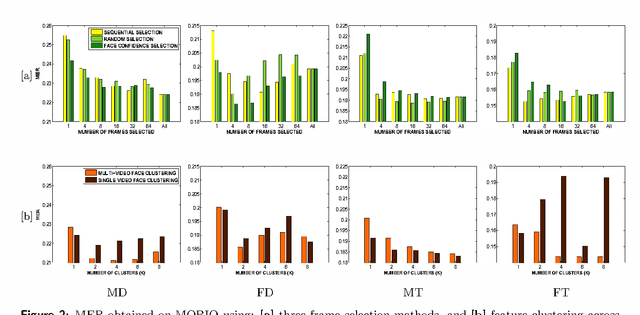

Balancing computational efficiency with recognition accuracy is one of the major challenges in real-world video-based face recognition. A significant design decision for any such system is whether to process and use all possible faces detected over the video frames, or whether to select only a few "best" faces. This paper presents a video face recognition system based on probabilistic Multi-Region Histograms to characterise performance trade-offs in: (i) selecting a subset of faces compared to using all faces, and (ii) combining information from all faces via clustering. Three face selection metrics are evaluated for choosing a subset: face detection confidence, random subset, and sequential selection. Experiments on the recently introduced MOBIO dataset indicate that the usage of all faces through clustering always outperformed selecting only a subset of faces. The experiments also show that the face selection metric based on face detection confidence generally provides better recognition performance than random or sequential sampling. Moreover, the optimal number of faces varies drastically across selection metric and subsets of MOBIO. Given the trade-offs between computational effort, recognition accuracy and robustness, it is recommended that face feature clustering would be most advantageous in batch processing (particularly for video-based watchlists), whereas face selection methods should be limited to applications with significant computational restrictions.