 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatch-based Probabilistic Image Quality Assessment for Face Selection and Improved Video-based Face Recognition
Paper and Code


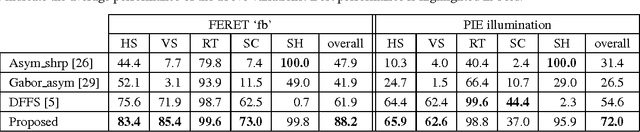

In video based face recognition, face images are typically captured over multiple frames in uncontrolled conditions, where head pose, illumination, shadowing, motion blur and focus change over the sequence. Additionally, inaccuracies in face localisation can also introduce scale and alignment variations. Using all face images, including images of poor quality, can actually degrade face recognition performance. While one solution it to use only the "best" subset of images, current face selection techniques are incapable of simultaneously handling all of the abovementioned issues. We propose an efficient patch-based face image quality assessment algorithm which quantifies the similarity of a face image to a probabilistic face model, representing an "ideal" face. Image characteristics that affect recognition are taken into account, including variations in geometric alignment (shift, rotation and scale), sharpness, head pose and cast shadows. Experiments on FERET and PIE datasets show that the proposed algorithm is able to identify images which are simultaneously the most frontal, aligned, sharp and well illuminated. Further experiments on a new video surveillance dataset (termed ChokePoint) show that the proposed method provides better face subsets than existing face selection techniques, leading to significant improvements in recognition accuracy.