 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComponent-based Attention for Large-scale Trademark Retrieval
Nov 07, 2018


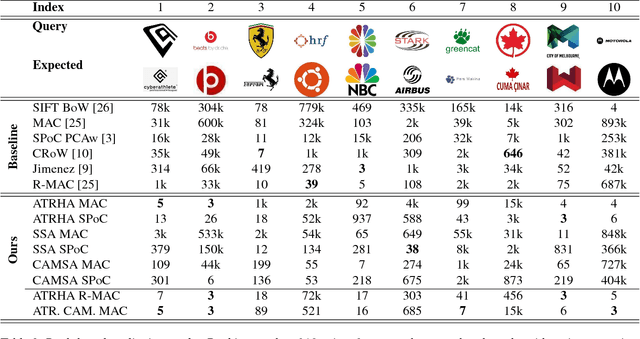
The demand for large-scale trademark retrieval (TR) systems has significantly increased to combat the rise in international trademark infringement. Unfortunately, the ranking accuracy of current approaches using either hand-crafted or pre-trained deep convolution neural network (DCNN) features is inadequate for large-scale deployments. We show in this paper that the ranking accuracy of TR systems can be significantly improved by incorporating hard and soft attention mechanisms, which direct attention to critical information such as figurative elements and reduce attention given to distracting and uninformative elements such as text and background. Our proposed approach achieves state-of-the-art results on a challenging large-scale trademark dataset.
Patch-based Probabilistic Image Quality Assessment for Face Selection and Improved Video-based Face Recognition
Mar 14, 2014

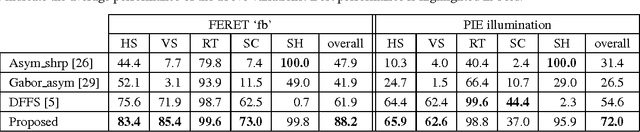

In video based face recognition, face images are typically captured over multiple frames in uncontrolled conditions, where head pose, illumination, shadowing, motion blur and focus change over the sequence. Additionally, inaccuracies in face localisation can also introduce scale and alignment variations. Using all face images, including images of poor quality, can actually degrade face recognition performance. While one solution it to use only the "best" subset of images, current face selection techniques are incapable of simultaneously handling all of the abovementioned issues. We propose an efficient patch-based face image quality assessment algorithm which quantifies the similarity of a face image to a probabilistic face model, representing an "ideal" face. Image characteristics that affect recognition are taken into account, including variations in geometric alignment (shift, rotation and scale), sharpness, head pose and cast shadows. Experiments on FERET and PIE datasets show that the proposed algorithm is able to identify images which are simultaneously the most frontal, aligned, sharp and well illuminated. Further experiments on a new video surveillance dataset (termed ChokePoint) show that the proposed method provides better face subsets than existing face selection techniques, leading to significant improvements in recognition accuracy.
Dynamic Amelioration of Resolution Mismatches for Local Feature Based Identity Inference
Apr 08, 2013
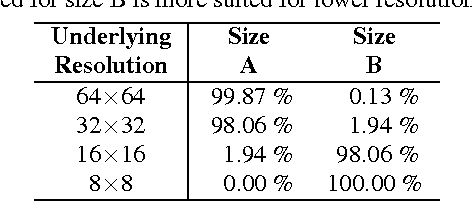
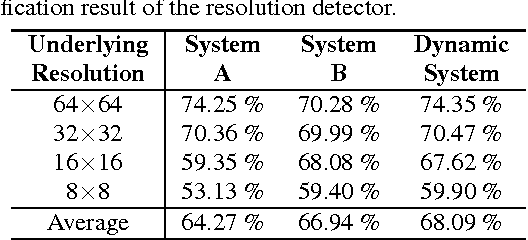
While existing face recognition systems based on local features are robust to issues such as misalignment, they can exhibit accuracy degradation when comparing images of differing resolutions. This is common in surveillance environments where a gallery of high resolution mugshots is compared to low resolution CCTV probe images, or where the size of a given image is not a reliable indicator of the underlying resolution (eg. poor optics). To alleviate this degradation, we propose a compensation framework which dynamically chooses the most appropriate face recognition system for a given pair of image resolutions. This framework applies a novel resolution detection method which does not rely on the size of the input images, but instead exploits the sensitivity of local features to resolution using a probabilistic multi-region histogram approach. Experiments on a resolution-modified version of the "Labeled Faces in the Wild" dataset show that the proposed resolution detector frontend obtains a 99% average accuracy in selecting the most appropriate face recognition system, resulting in higher overall face discrimination accuracy (across several resolutions) compared to the individual baseline face recognition systems.
Video Face Matching using Subset Selection and Clustering of Probabilistic Multi-Region Histograms
Mar 26, 2013

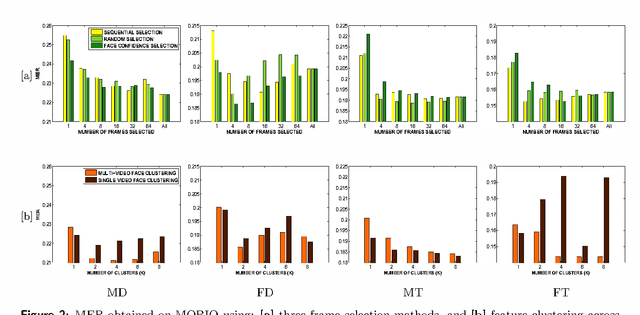

Balancing computational efficiency with recognition accuracy is one of the major challenges in real-world video-based face recognition. A significant design decision for any such system is whether to process and use all possible faces detected over the video frames, or whether to select only a few "best" faces. This paper presents a video face recognition system based on probabilistic Multi-Region Histograms to characterise performance trade-offs in: (i) selecting a subset of faces compared to using all faces, and (ii) combining information from all faces via clustering. Three face selection metrics are evaluated for choosing a subset: face detection confidence, random subset, and sequential selection. Experiments on the recently introduced MOBIO dataset indicate that the usage of all faces through clustering always outperformed selecting only a subset of faces. The experiments also show that the face selection metric based on face detection confidence generally provides better recognition performance than random or sequential sampling. Moreover, the optimal number of faces varies drastically across selection metric and subsets of MOBIO. Given the trade-offs between computational effort, recognition accuracy and robustness, it is recommended that face feature clustering would be most advantageous in batch processing (particularly for video-based watchlists), whereas face selection methods should be limited to applications with significant computational restrictions.