 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSlideNet: Fast and Accurate Slide Quality Assessment Based on Deep Neural Networks
Mar 20, 2018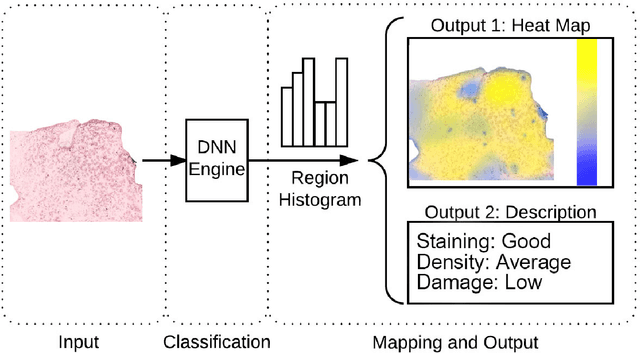

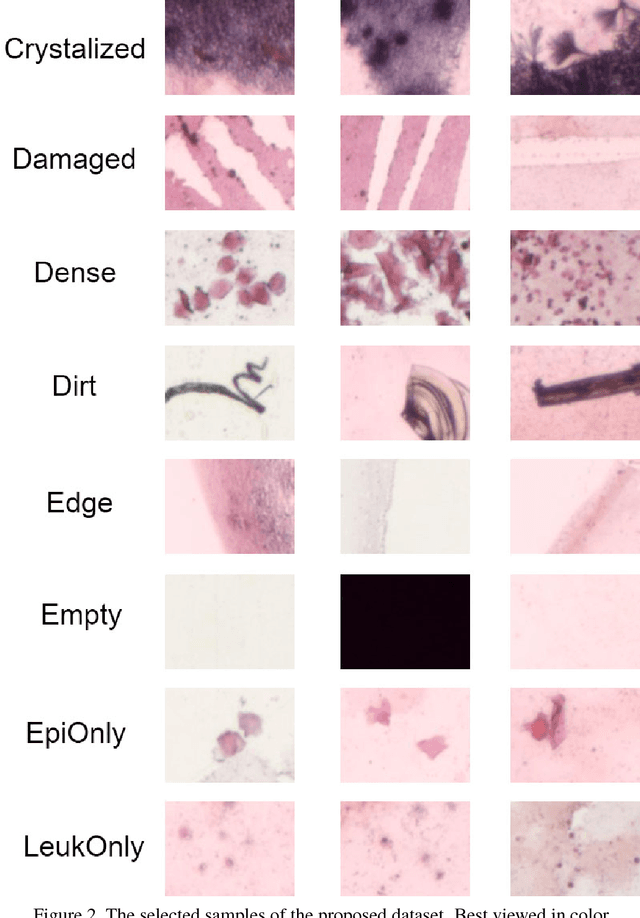
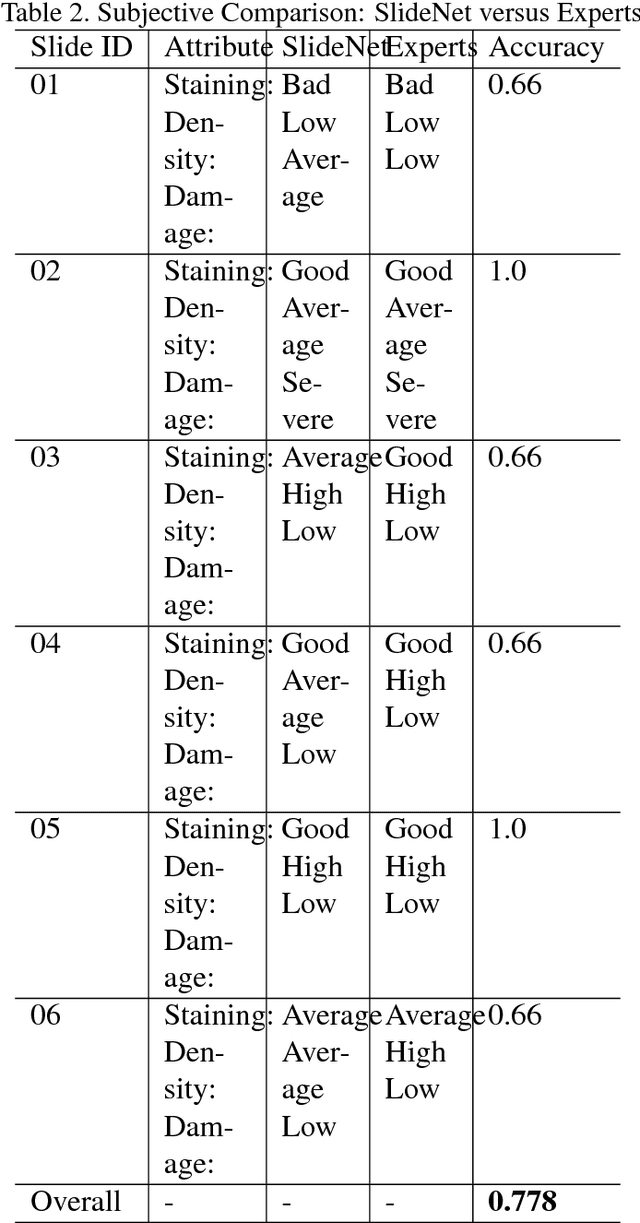
This work tackles the automatic fine-grained slide quality assessment problem for digitized direct smears test using the Gram staining protocol. Automatic quality assessment can provide useful information for the pathologists and the whole digital pathology workflow. For instance, if the system found a slide to have a low staining quality, it could send a request to the automatic slide preparation system to remake the slide. If the system detects severe damage in the slides, it could notify the experts that manual microscope reading may be required. In order to address the quality assessment problem, we propose a deep neural network based framework to automatically assess the slide quality in a semantic way. Specifically, the first step of our framework is to perform dense fine-grained region classification on the whole slide and calculate the region distribution histogram. Next, our framework will generate assessments of the slide quality from various perspectives: staining quality, information density, damage level and which regions are more valuable for subsequent high-magnification analysis. To make the information more accessible, we present our results in the form of a heat map and text summaries. Additionally, in order to stimulate research in this direction, we propose a novel dataset for slide quality assessment. Experiments show that the proposed framework outperforms recent related works.
Joint Recognition and Segmentation of Actions via Probabilistic Integration of Spatio-Temporal Fisher Vectors
Oct 04, 2016


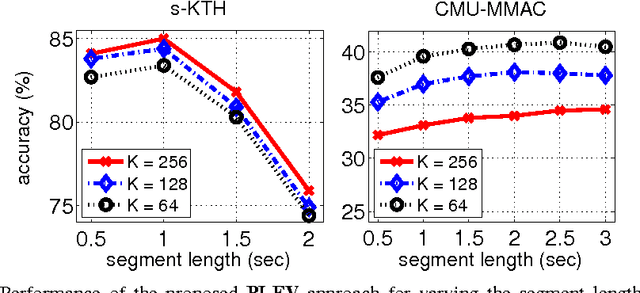
We propose a hierarchical approach to multi-action recognition that performs joint classification and segmentation. A given video (containing several consecutive actions) is processed via a sequence of overlapping temporal windows. Each frame in a temporal window is represented through selective low-level spatio-temporal features which efficiently capture relevant local dynamics. Features from each window are represented as a Fisher vector, which captures first and second order statistics. Instead of directly classifying each Fisher vector, it is converted into a vector of class probabilities. The final classification decision for each frame is then obtained by integrating the class probabilities at the frame level, which exploits the overlapping of the temporal windows. Experiments were performed on two datasets: s-KTH (a stitched version of the KTH dataset to simulate multi-actions), and the challenging CMU-MMAC dataset. On s-KTH, the proposed approach achieves an accuracy of 85.0%, significantly outperforming two recent approaches based on GMMs and HMMs which obtained 78.3% and 71.2%, respectively. On CMU-MMAC, the proposed approach achieves an accuracy of 40.9%, outperforming the GMM and HMM approaches which obtained 33.7% and 38.4%, respectively. Furthermore, the proposed system is on average 40 times faster than the GMM based approach.
Comparative Evaluation of Action Recognition Methods via Riemannian Manifolds, Fisher Vectors and GMMs: Ideal and Challenging Conditions
Oct 04, 2016
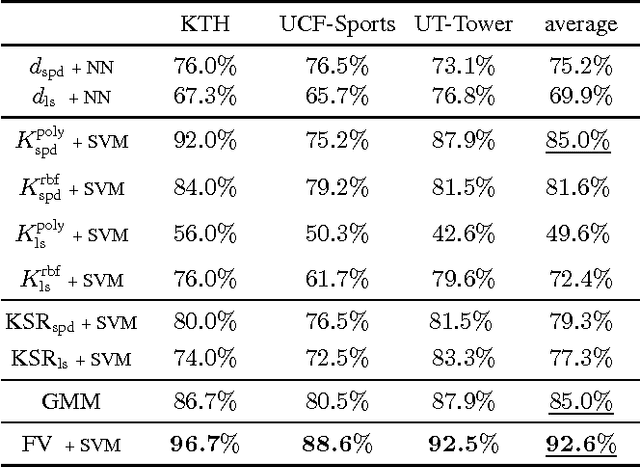

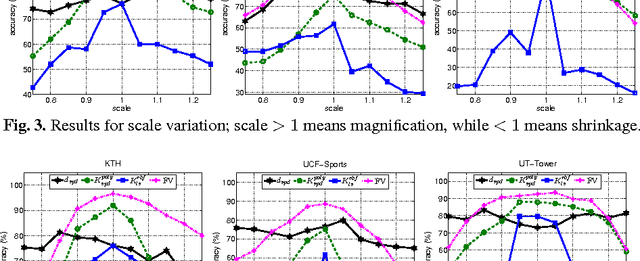
We present a comparative evaluation of various techniques for action recognition while keeping as many variables as possible controlled. We employ two categories of Riemannian manifolds: symmetric positive definite matrices and linear subspaces. For both categories we use their corresponding nearest neighbour classifiers, kernels, and recent kernelised sparse representations. We compare against traditional action recognition techniques based on Gaussian mixture models and Fisher vectors (FVs). We evaluate these action recognition techniques under ideal conditions, as well as their sensitivity in more challenging conditions (variations in scale and translation). Despite recent advancements for handling manifolds, manifold based techniques obtain the lowest performance and their kernel representations are more unstable in the presence of challenging conditions. The FV approach obtains the highest accuracy under ideal conditions. Moreover, FV best deals with moderate scale and translation changes.
Towards Miss Universe Automatic Prediction: The Evening Gown Competition
Sep 12, 2016

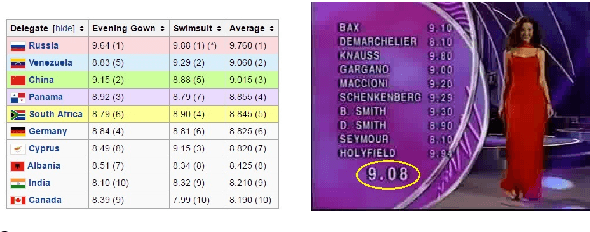
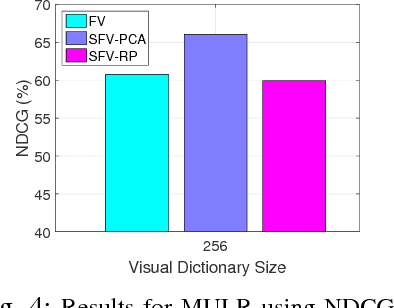
Can we predict the winner of Miss Universe after watching how they stride down the catwalk during the evening gown competition? Fashion gurus say they can! In our work, we study this question from the perspective of computer vision. In particular, we want to understand whether existing computer vision approaches can be used to automatically extract the qualities exhibited by the Miss Universe winners during their catwalk. This study can pave the way towards new vision-based applications for the fashion industry. To this end, we propose a novel video dataset, called the Miss Universe dataset, comprising 10 years of the evening gown competition selected between 1996-2010. We further propose two ranking-related problems: (1) Miss Universe Listwise Ranking and (2) Miss Universe Pairwise Ranking. In addition, we also develop an approach that simultaneously addresses the two proposed problems. To describe the videos we employ the recently proposed Stacked Fisher Vectors in conjunction with robust local spatio-temporal features. From our evaluation we found that although the addressed problems are extremely challenging, the proposed system is able to rank the winner in the top 3 best predicted scores for 5 out of 10 Miss Universe competitions.
Multi-Action Recognition via Stochastic Modelling of Optical Flow and Gradients
Feb 06, 2015


In this paper we propose a novel approach to multi-action recognition that performs joint segmentation and classification. This approach models each action using a Gaussian mixture using robust low-dimensional action features. Segmentation is achieved by performing classification on overlapping temporal windows, which are then merged to produce the final result. This approach is considerably less complicated than previous methods which use dynamic programming or computationally expensive hidden Markov models (HMMs). Initial experiments on a stitched version of the KTH dataset show that the proposed approach achieves an accuracy of 78.3%, outperforming a recent HMM-based approach which obtained 71.2%.
Summarisation of Short-Term and Long-Term Videos using Texture and Colour
Mar 03, 2014

We present a novel approach to video summarisation that makes use of a Bag-of-visual-Textures (BoT) approach. Two systems are proposed, one based solely on the BoT approach and another which exploits both colour information and BoT features. On 50 short-term videos from the Open Video Project we show that our BoT and fusion systems both achieve state-of-the-art performance, obtaining an average F-measure of 0.83 and 0.86 respectively, a relative improvement of 9% and 13% when compared to the previous state-of-the-art. When applied to a new underwater surveillance dataset containing 33 long-term videos, the proposed system reduces the amount of footage by a factor of 27, with only minor degradation in the information content. This order of magnitude reduction in video data represents significant savings in terms of time and potential labour cost when manually reviewing such footage.